Downloaded 40 times













![Lower TCO
June
2013
Study
by
Accenture
Technology
Labs
Not
Sponsored
or
Funded
by
Amazon
“Accenture
assessed
the
price-‐
performance
raJo
between
bare-‐metal
Hadoop
clusters
and
Hadoop-‐as-‐a-‐Service
on
Amazon
Web
Services…[and]
revealed
that
Hadoop-‐as-‐a-‐Service
offers
bePer
price-‐performance
raJo…”
hkp://www.accenture.com/us-‐en/Pages/insight-‐hadoop-‐
deployment-‐comparison.aspx](https://image.slidesharecdn.com/july2013-130722153651-phpapp02/85/Amazon-Elastic-Map-Reduce-Ian-Meyers-40-320.jpg)
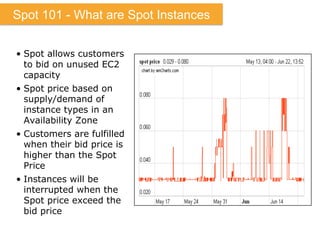
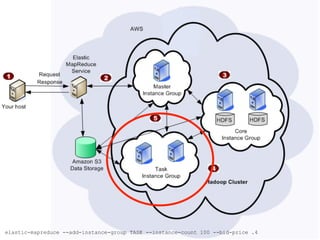
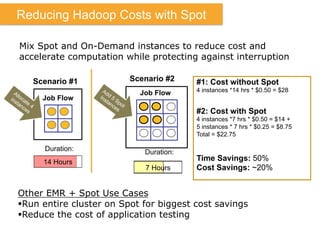

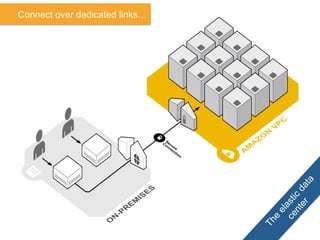



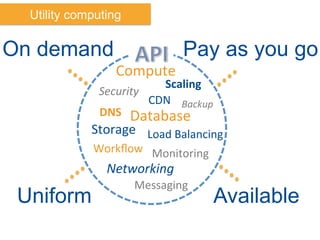
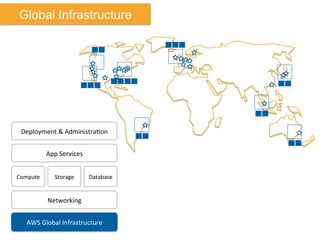
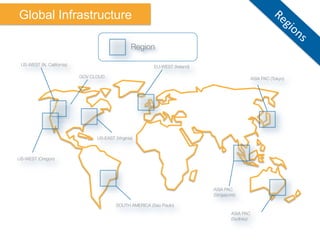
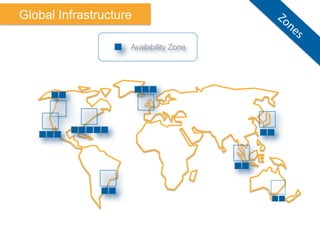
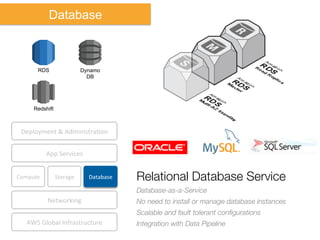
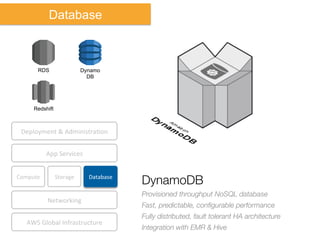
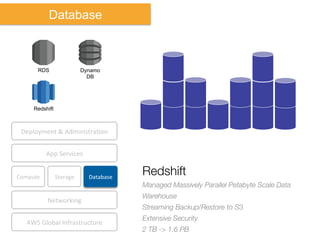
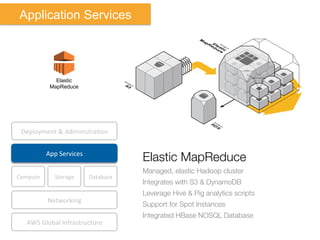
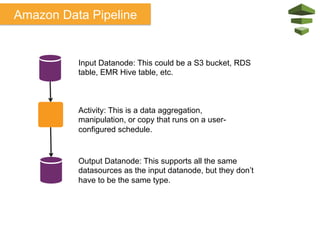
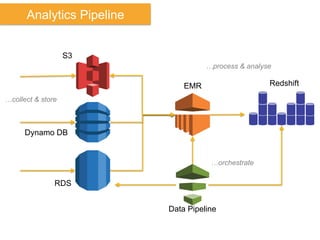
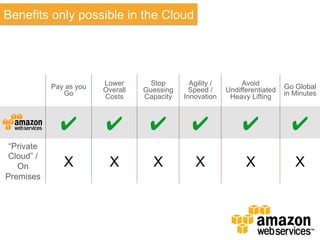
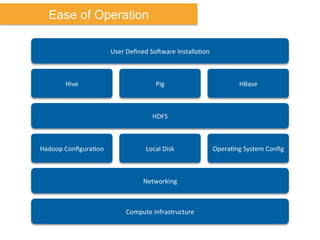
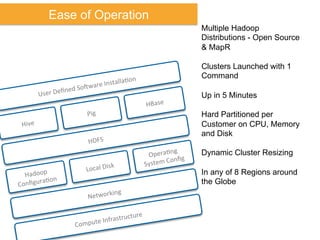
The document discusses Amazon Web Services (AWS) and its cloud computing offerings, focusing on the advantages of utility computing, scalability, and cost management. It details various services including Elastic MapReduce, Simple Storage Service, and databases like RDS and DynamoDB, along with their performance metrics and use cases. Additionally, the document highlights the benefits of using AWS for IT infrastructure, emphasizing agility, reduced capital expenditure, and global reach.













































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)