Download as PDF, PPTX


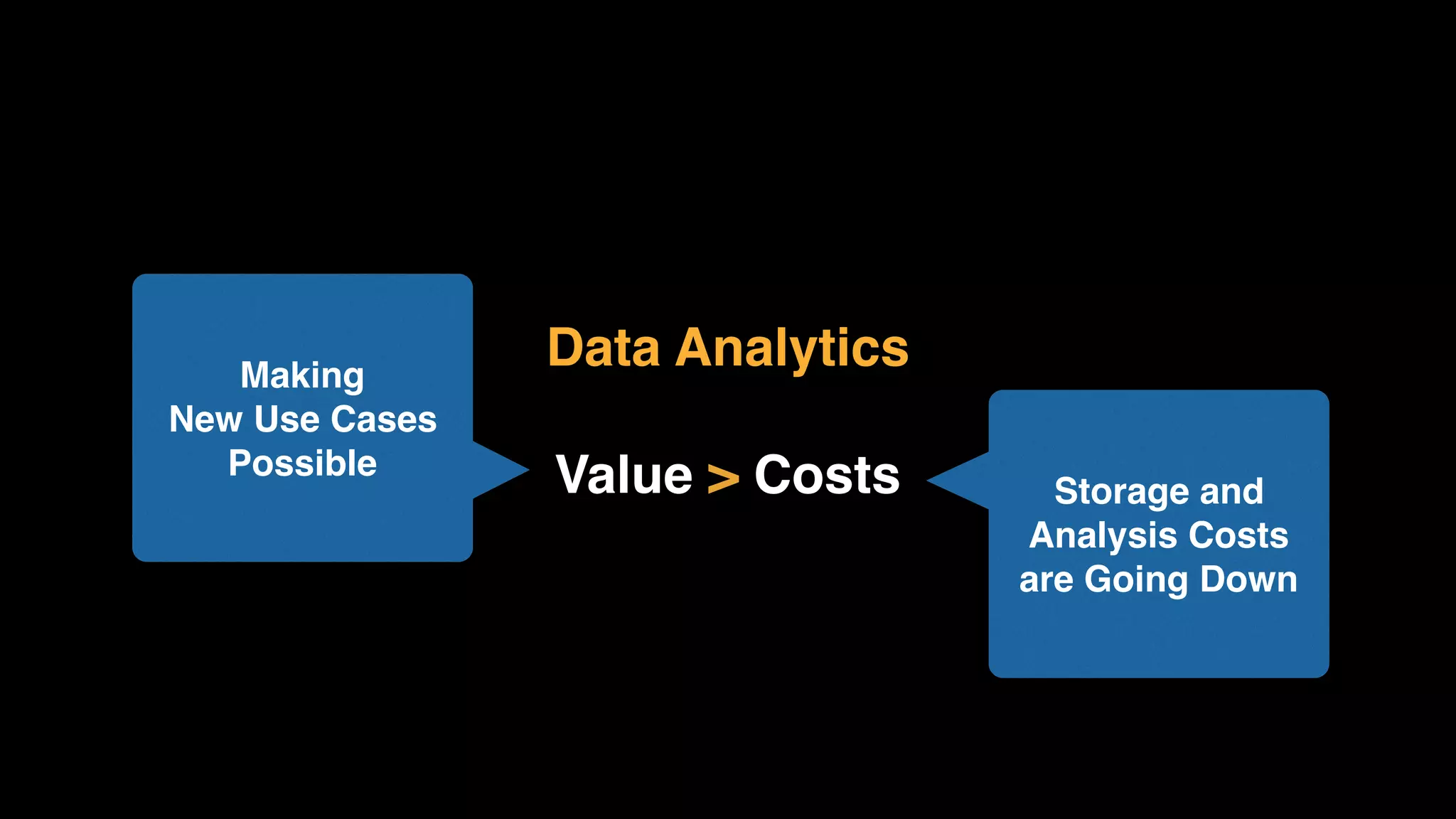
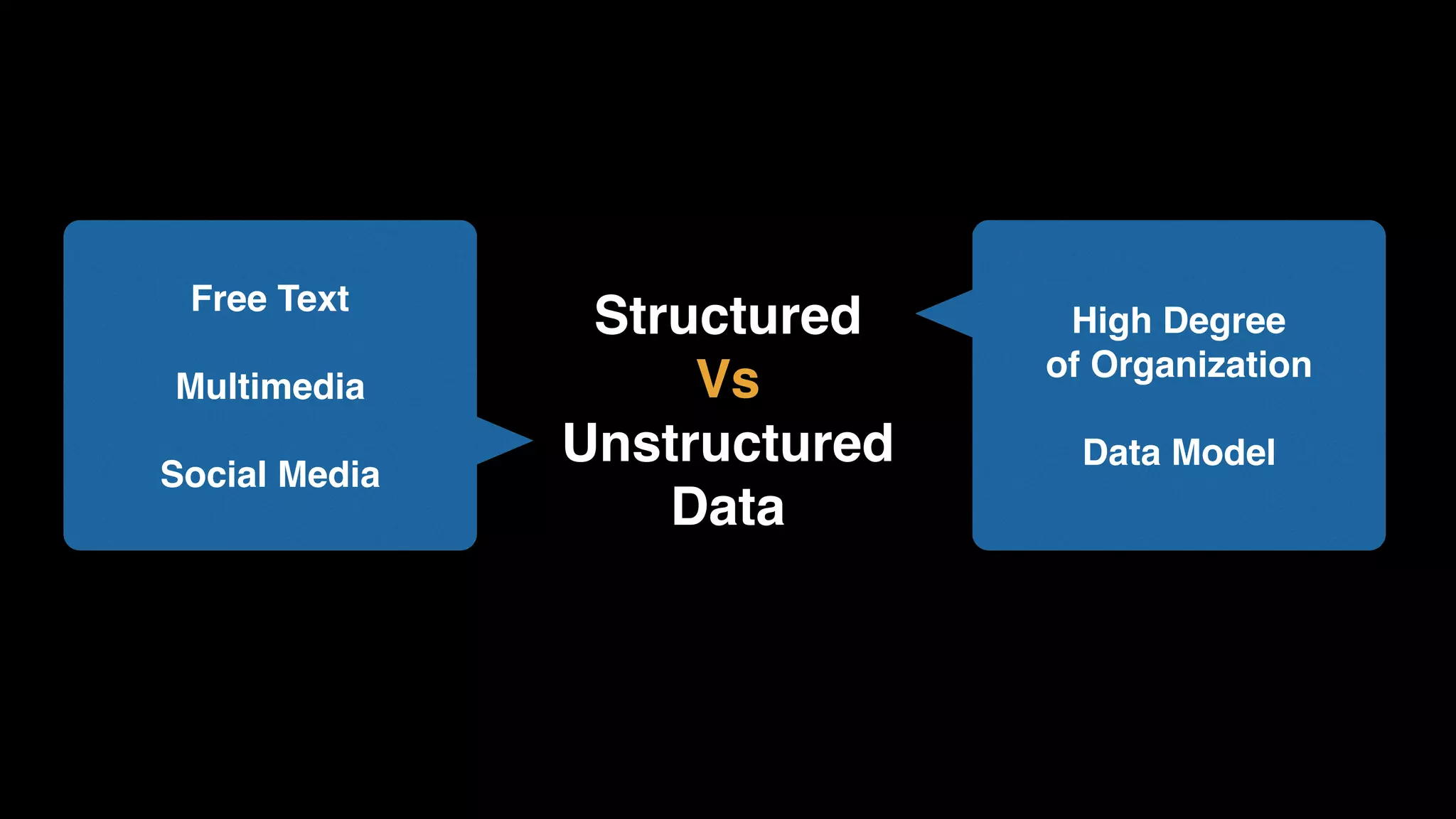
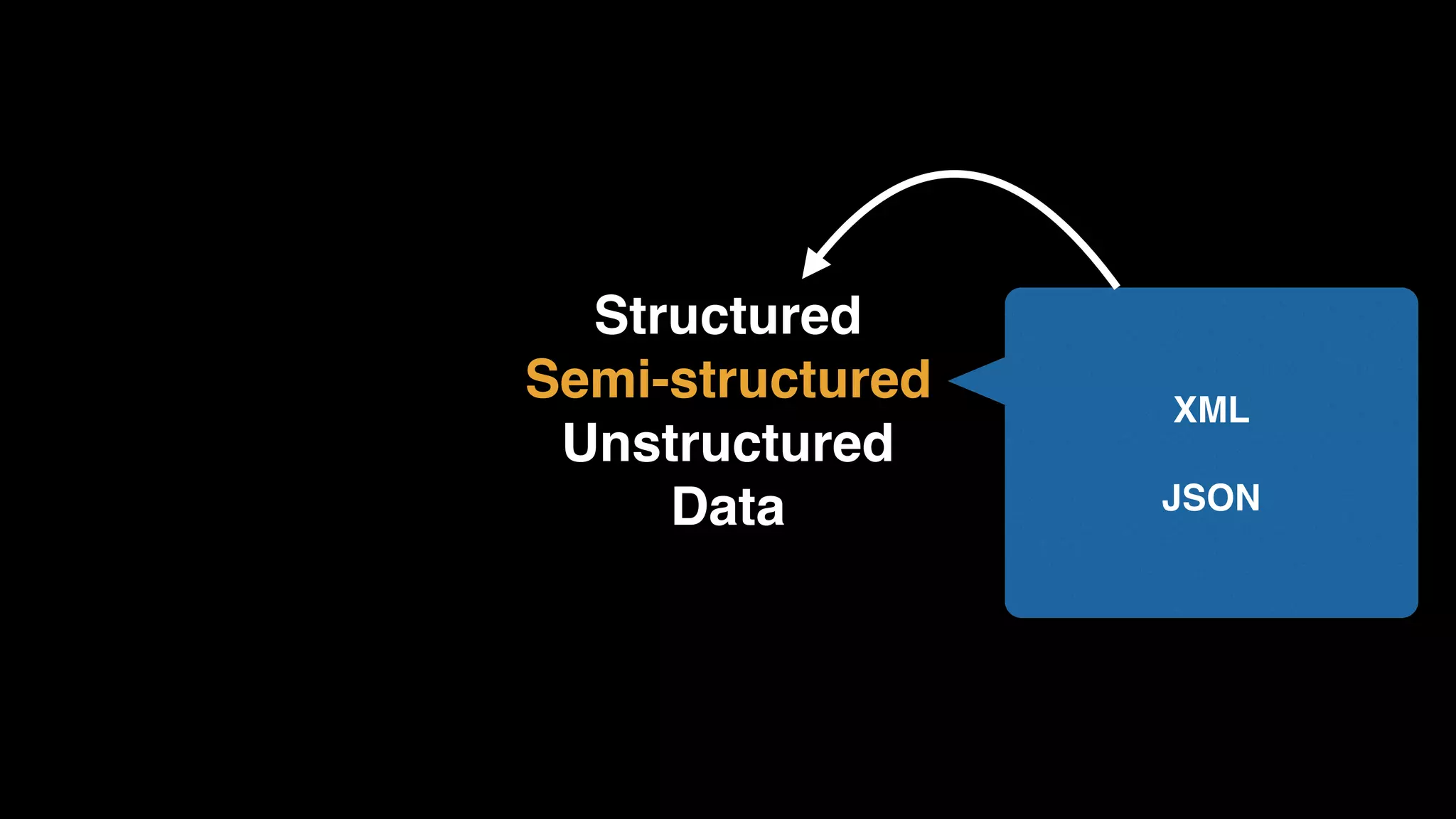
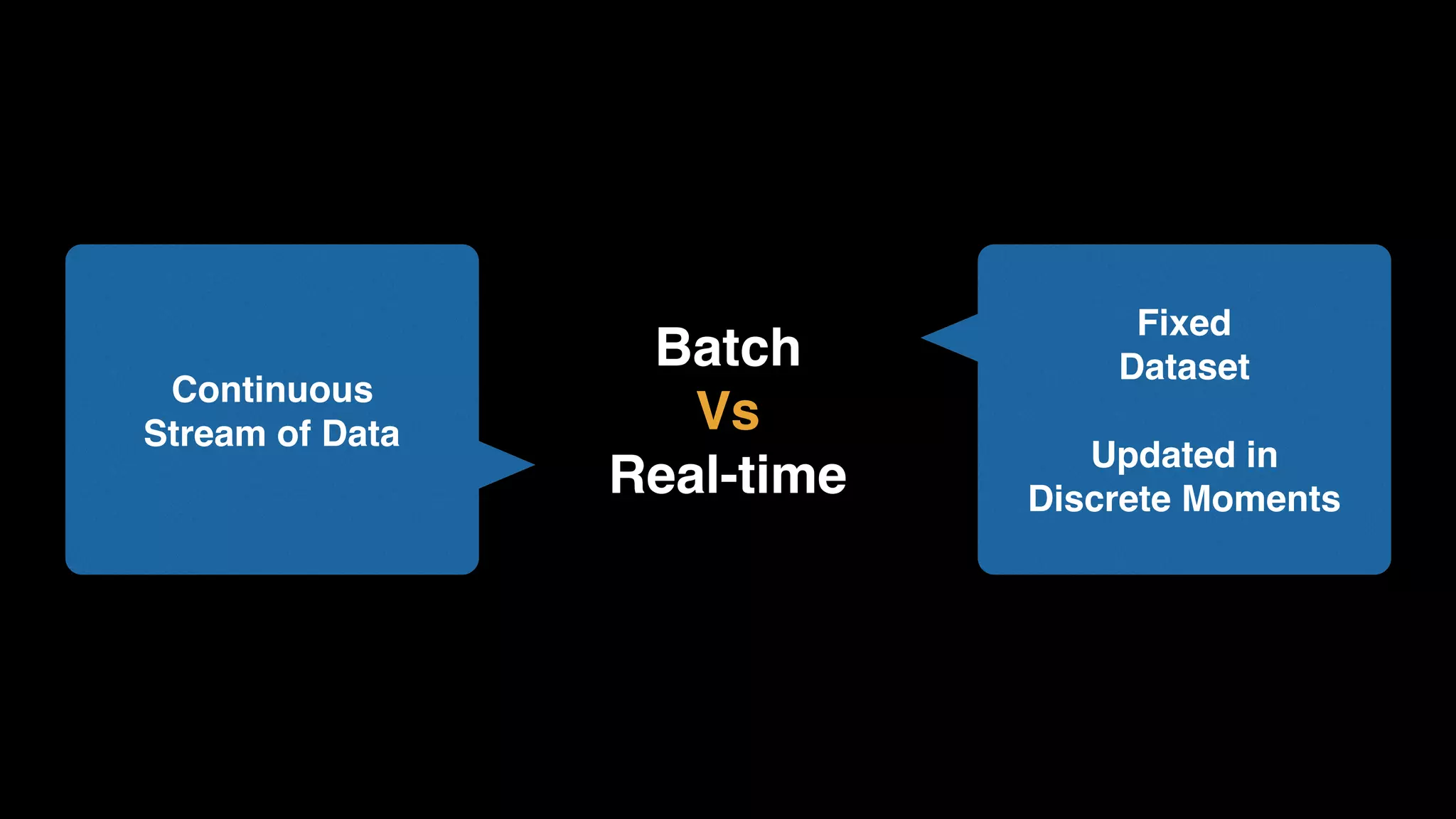
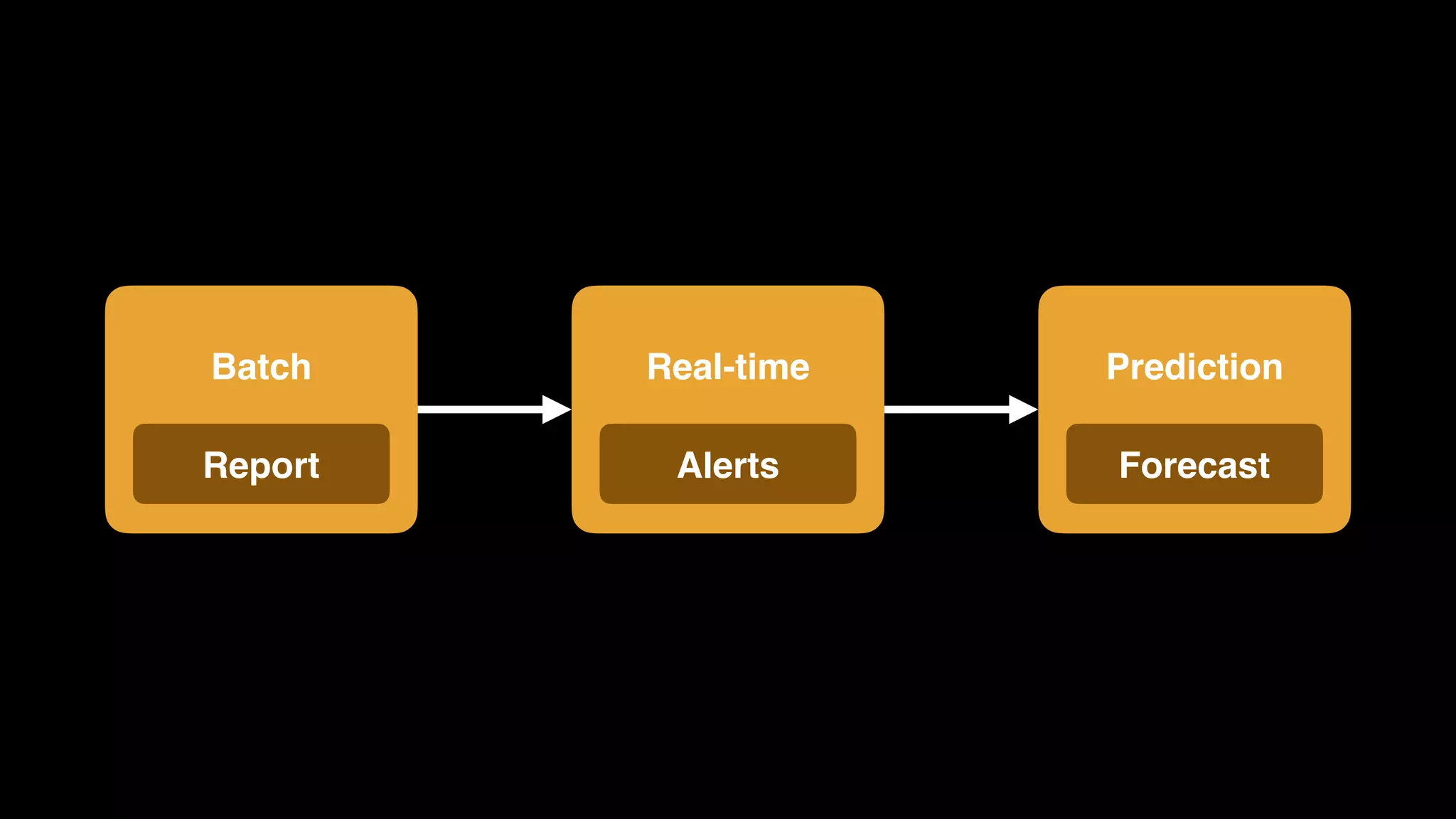

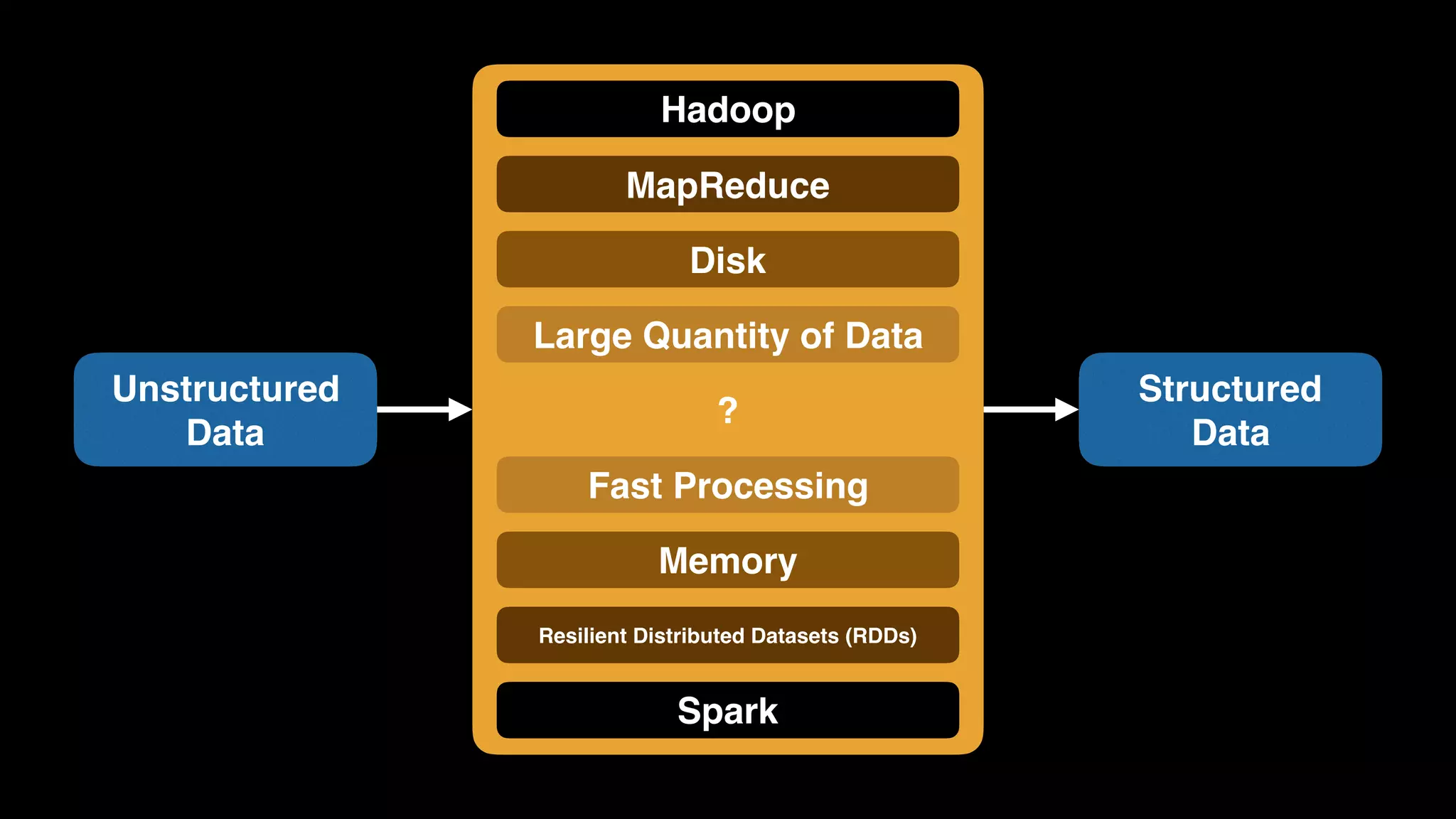
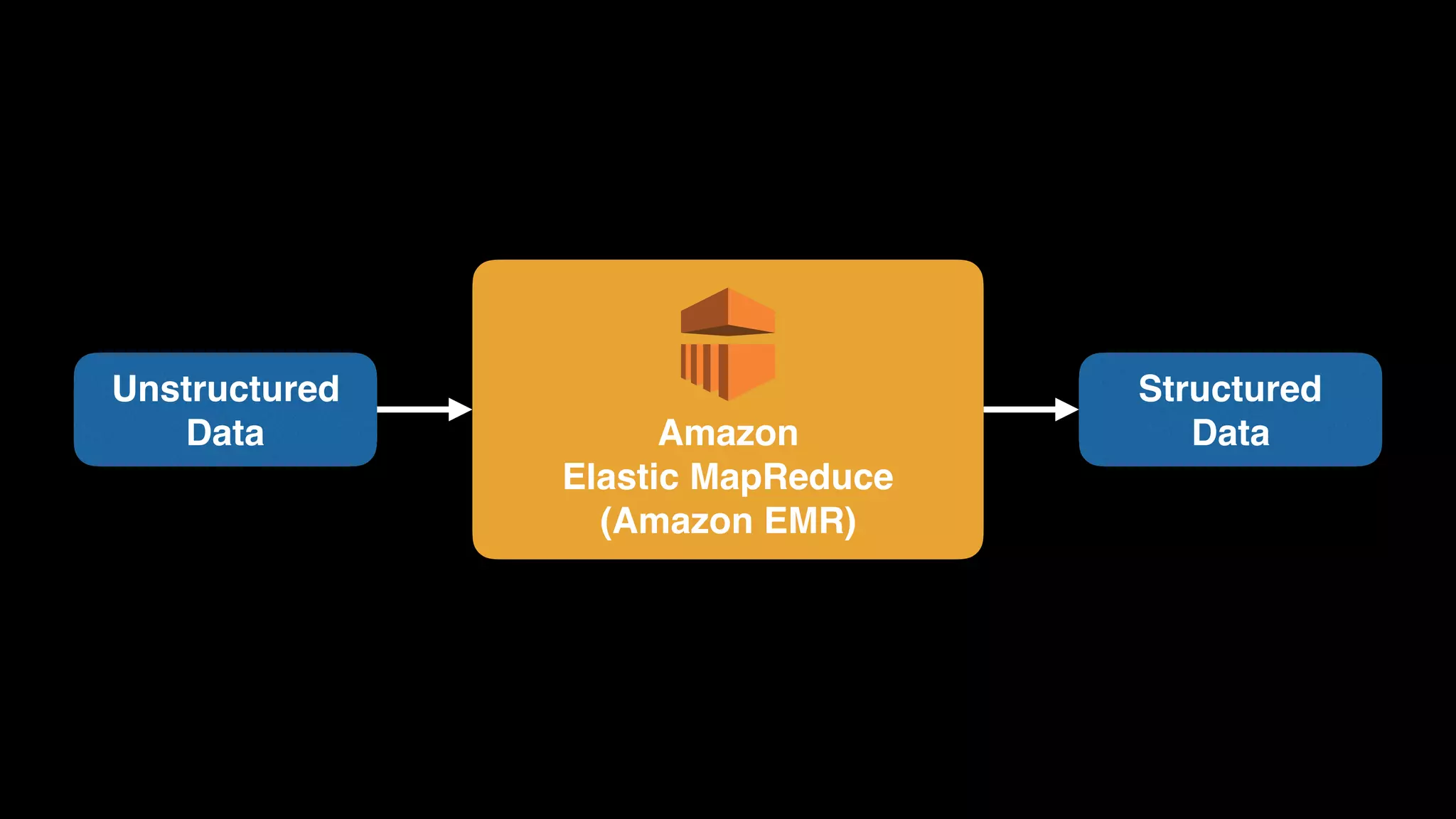
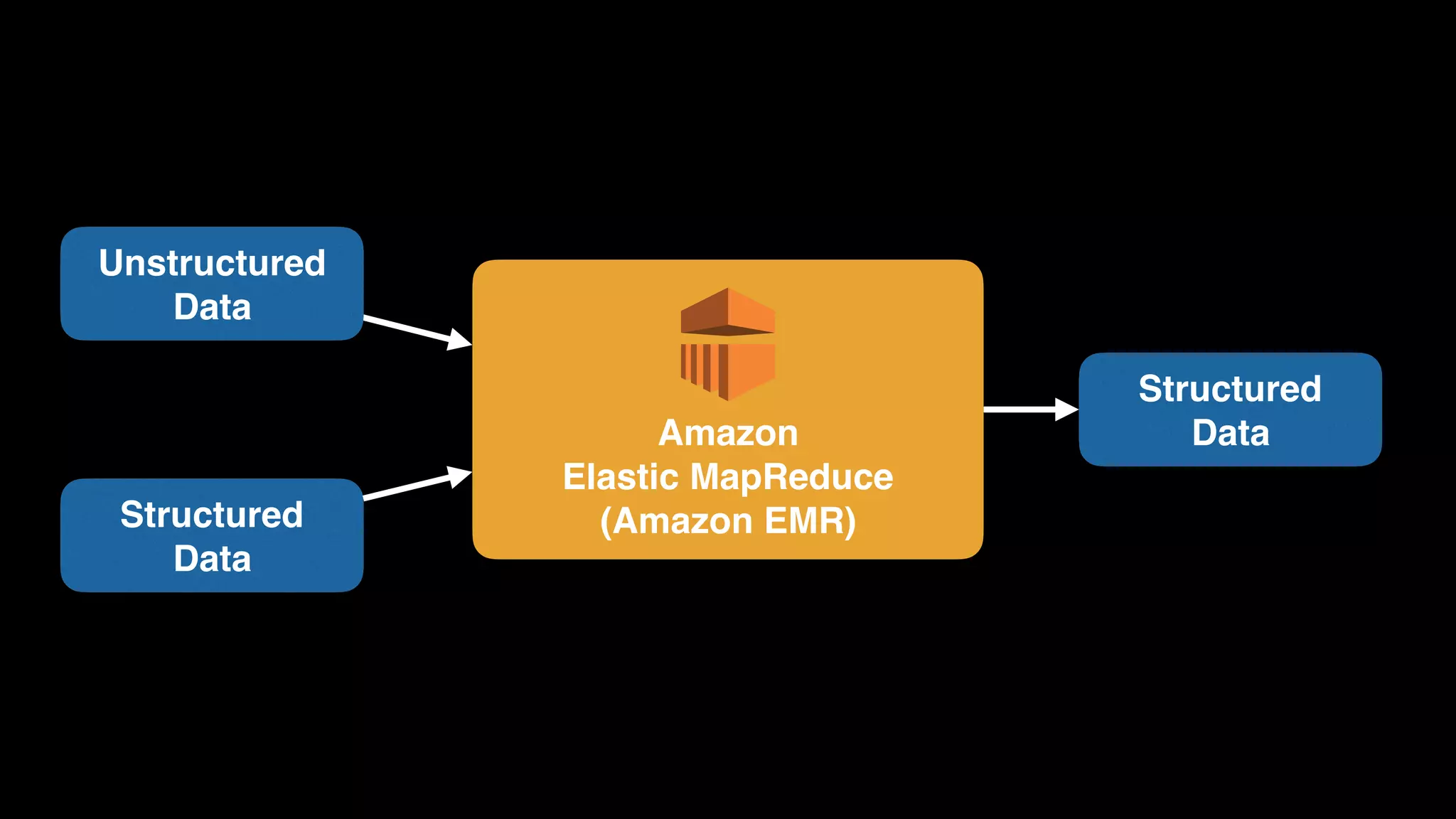

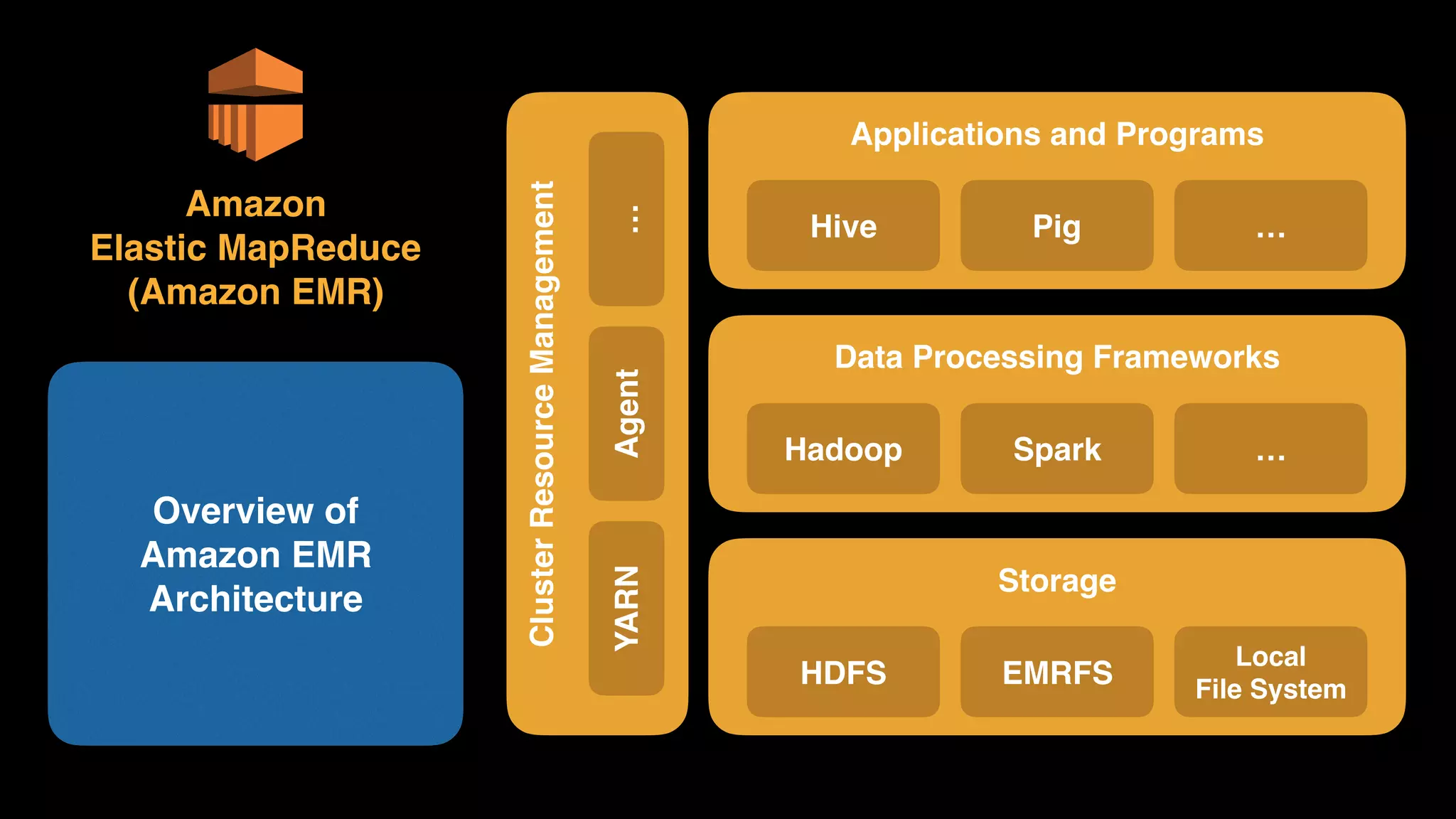
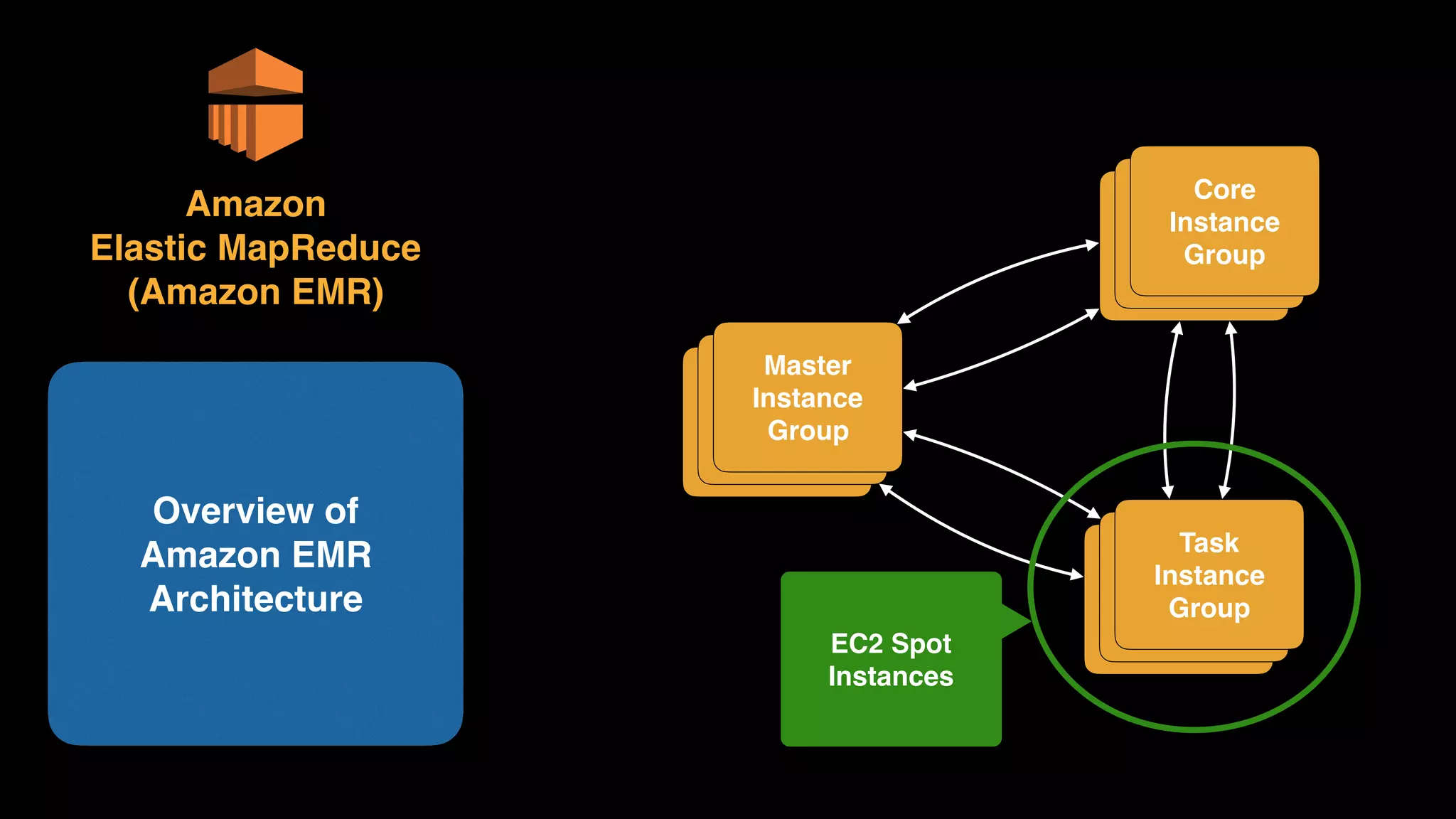
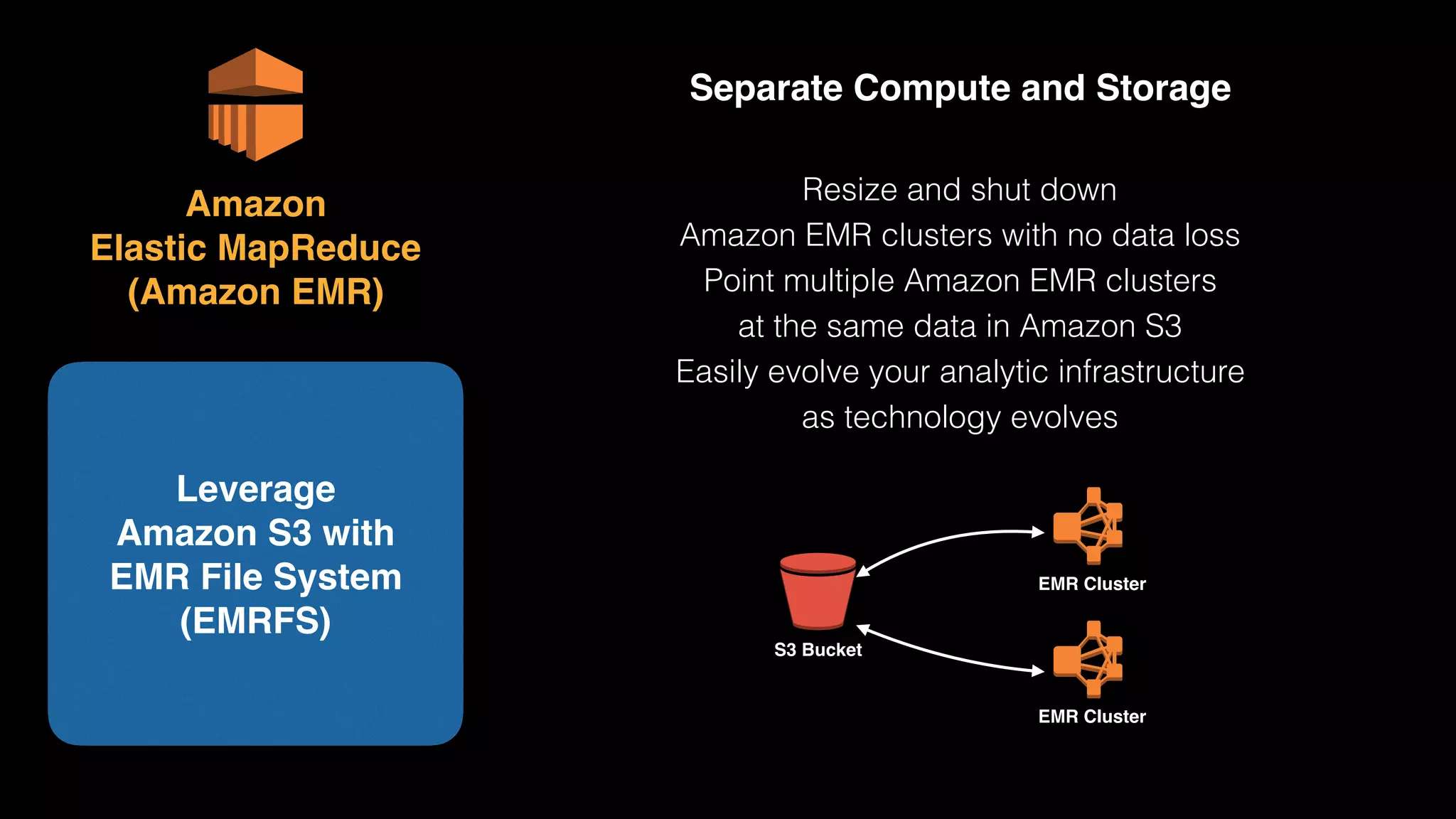
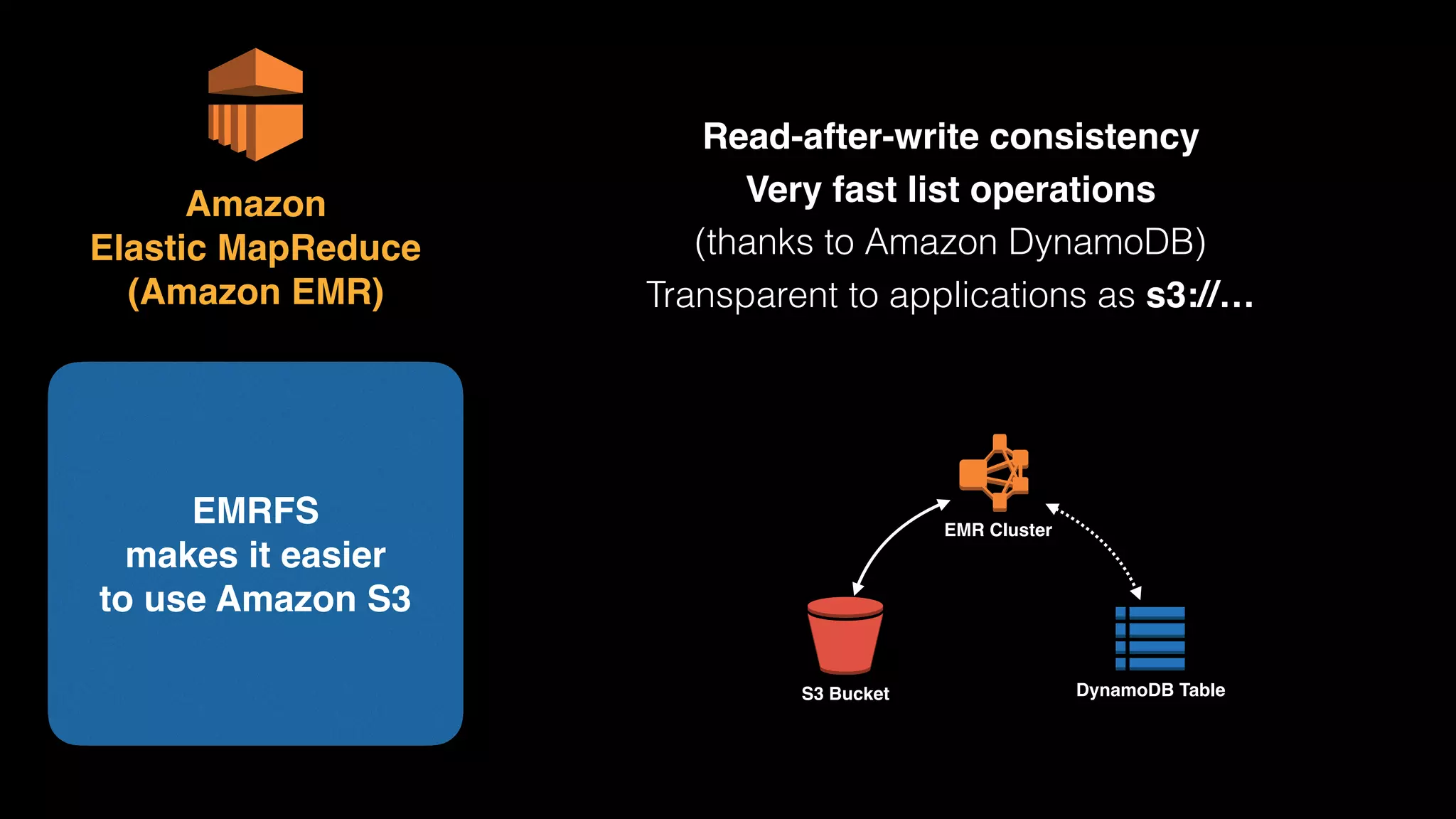
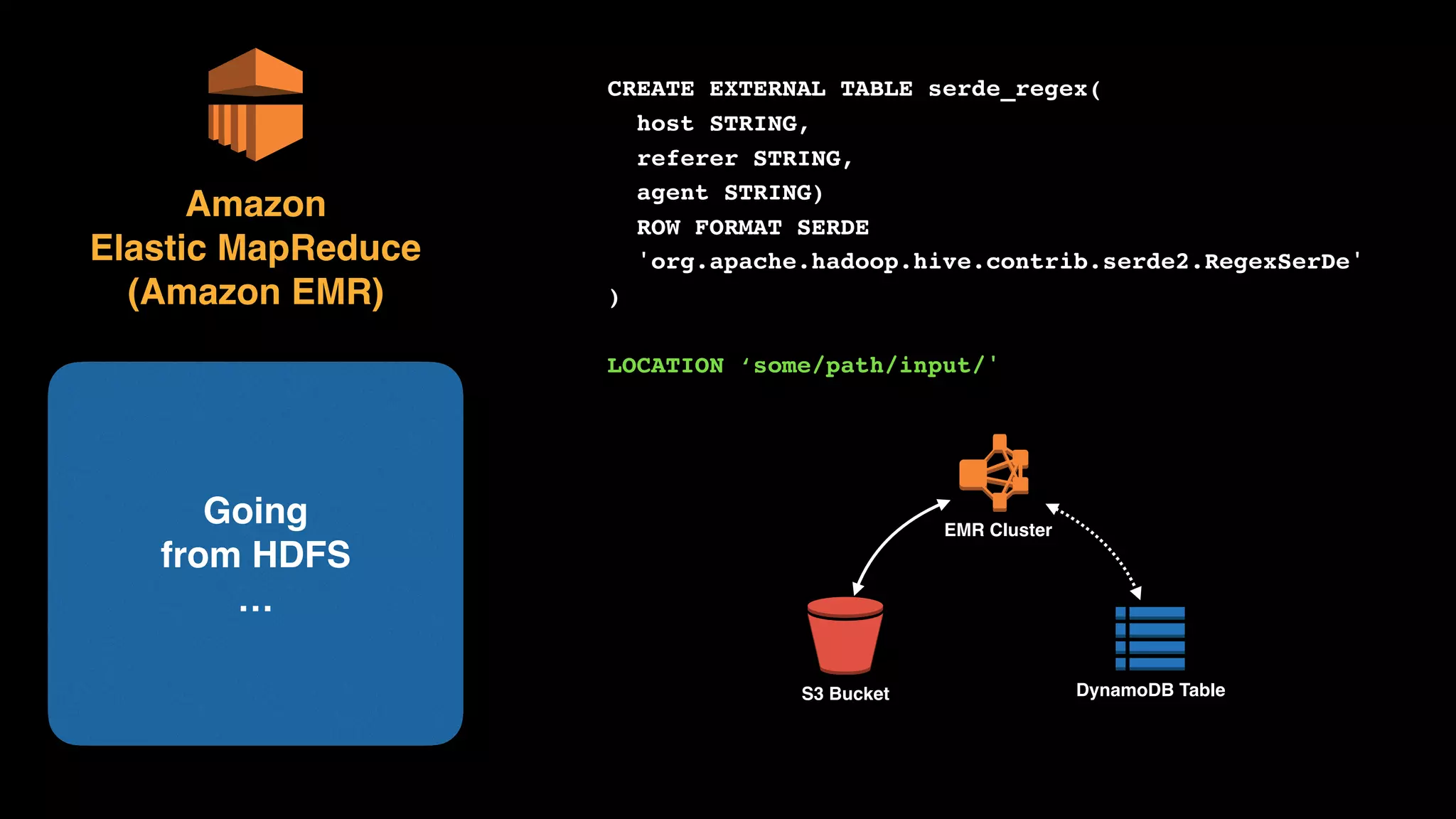
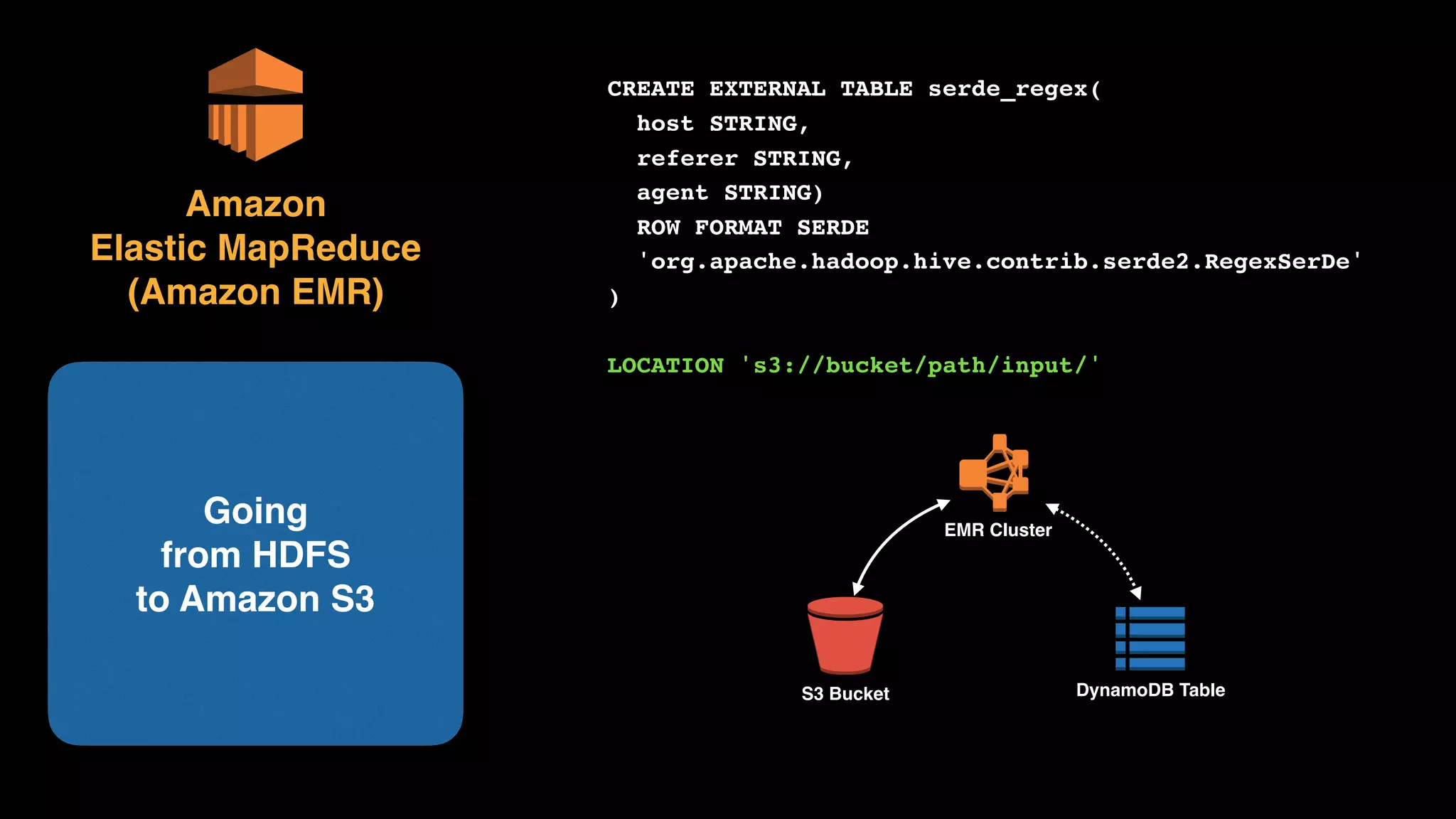
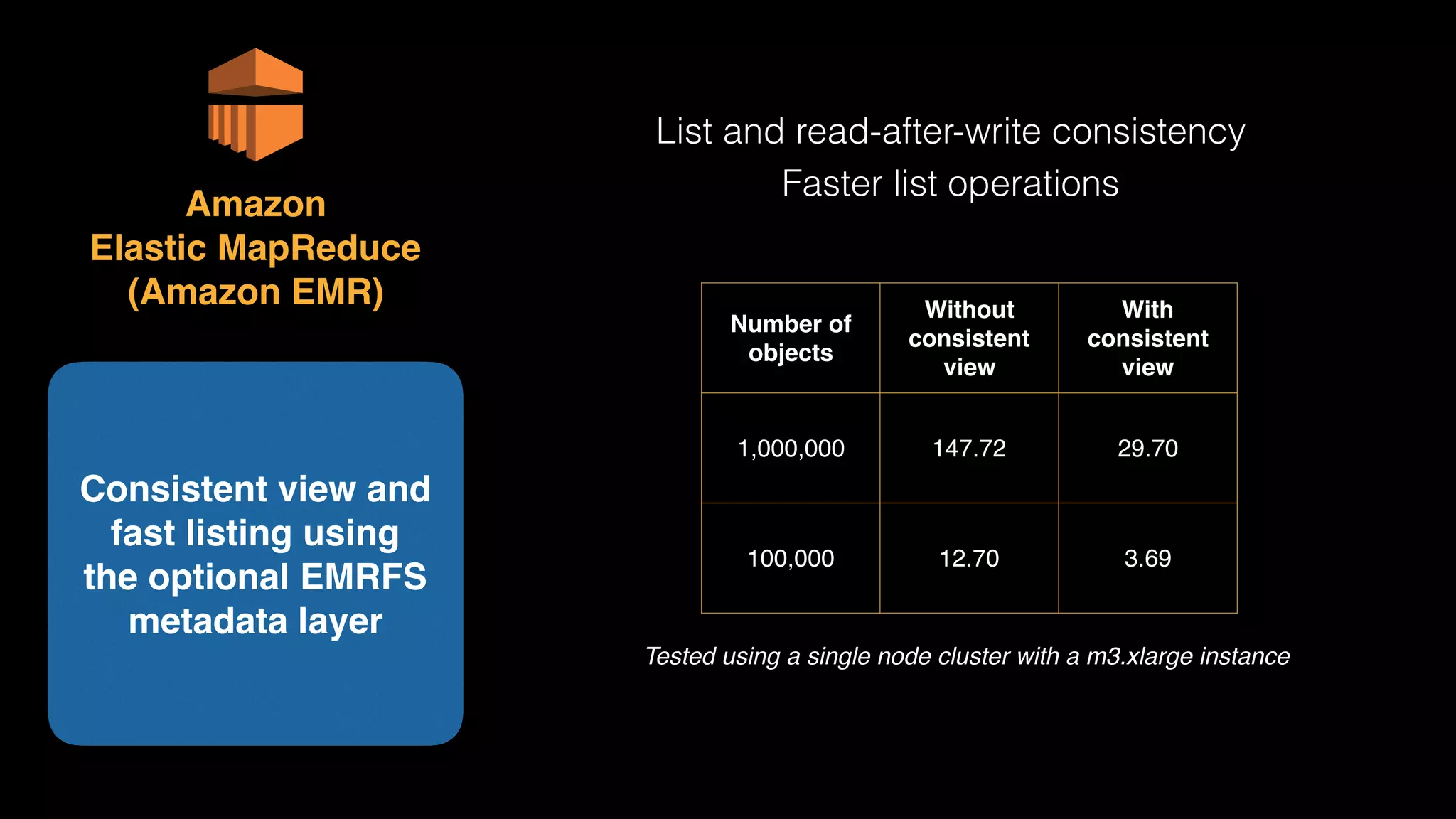
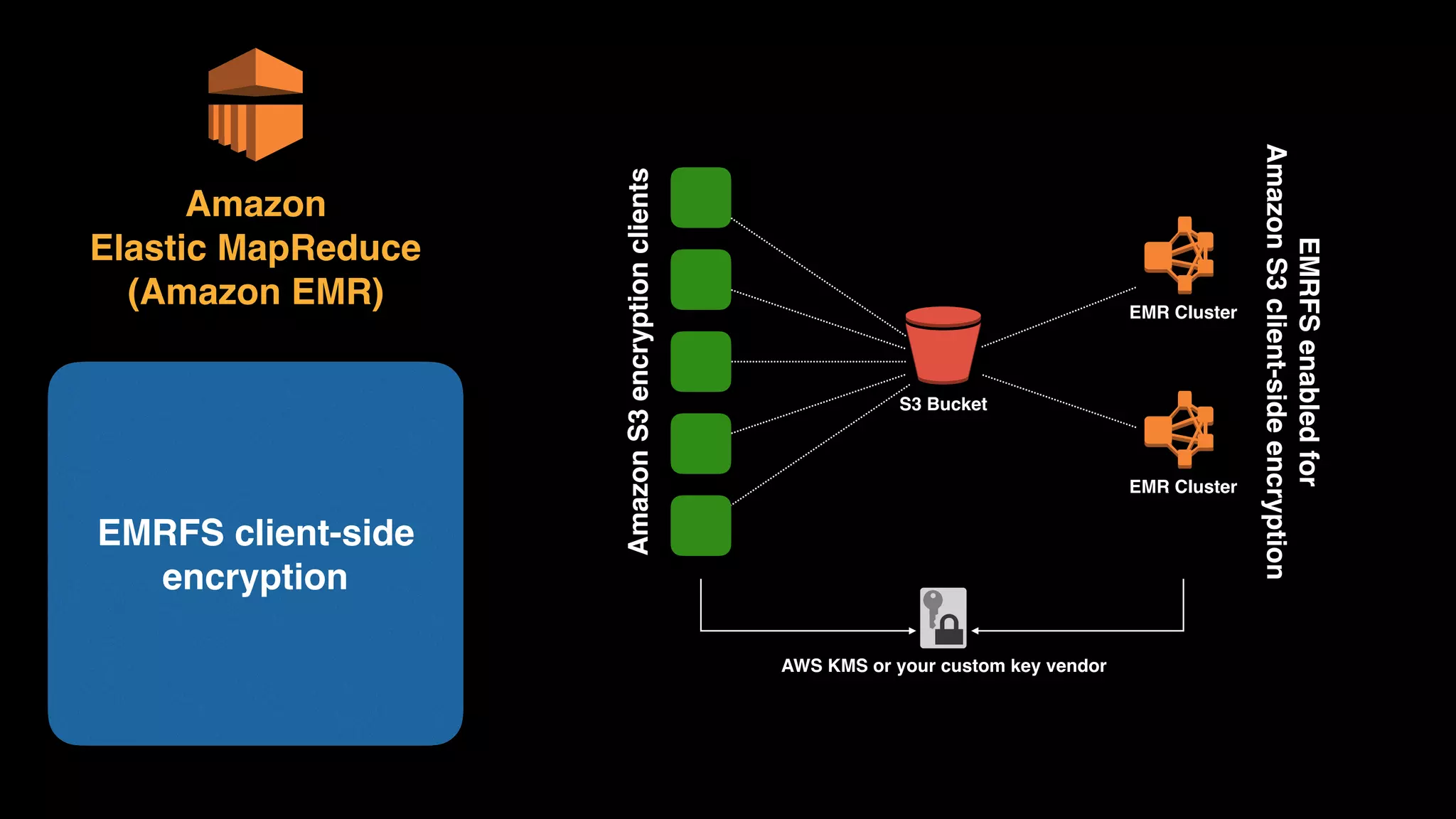



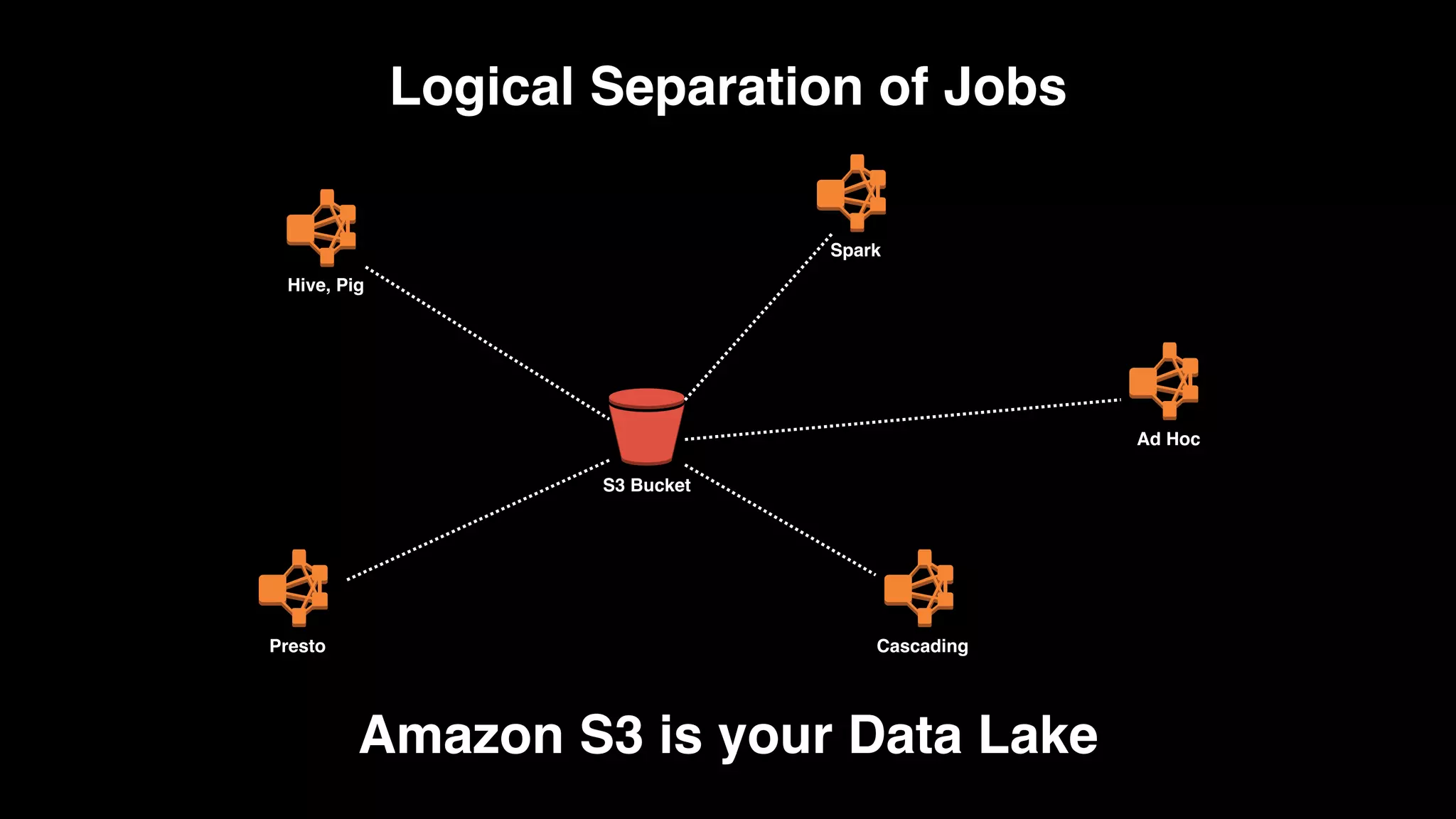
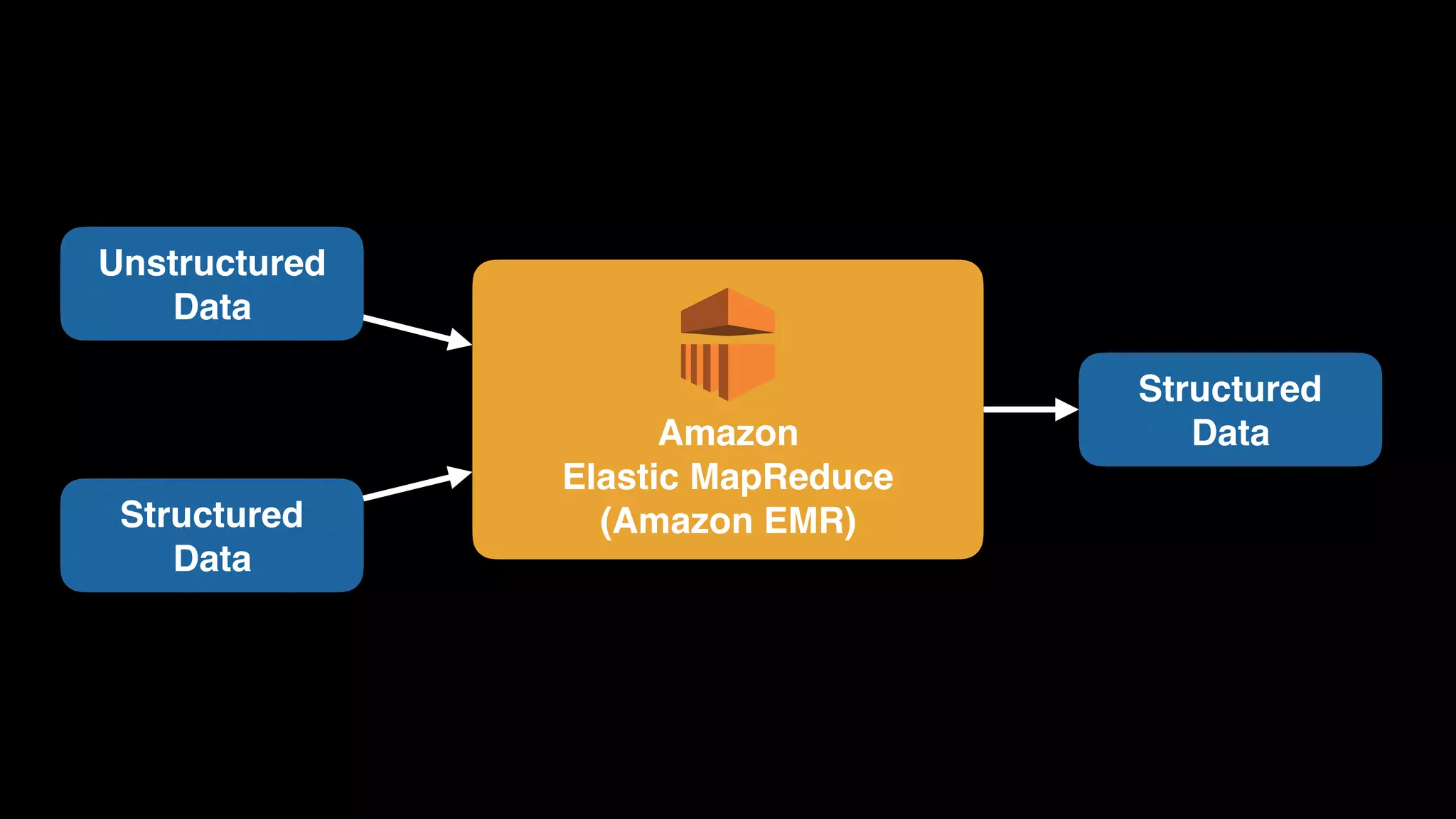

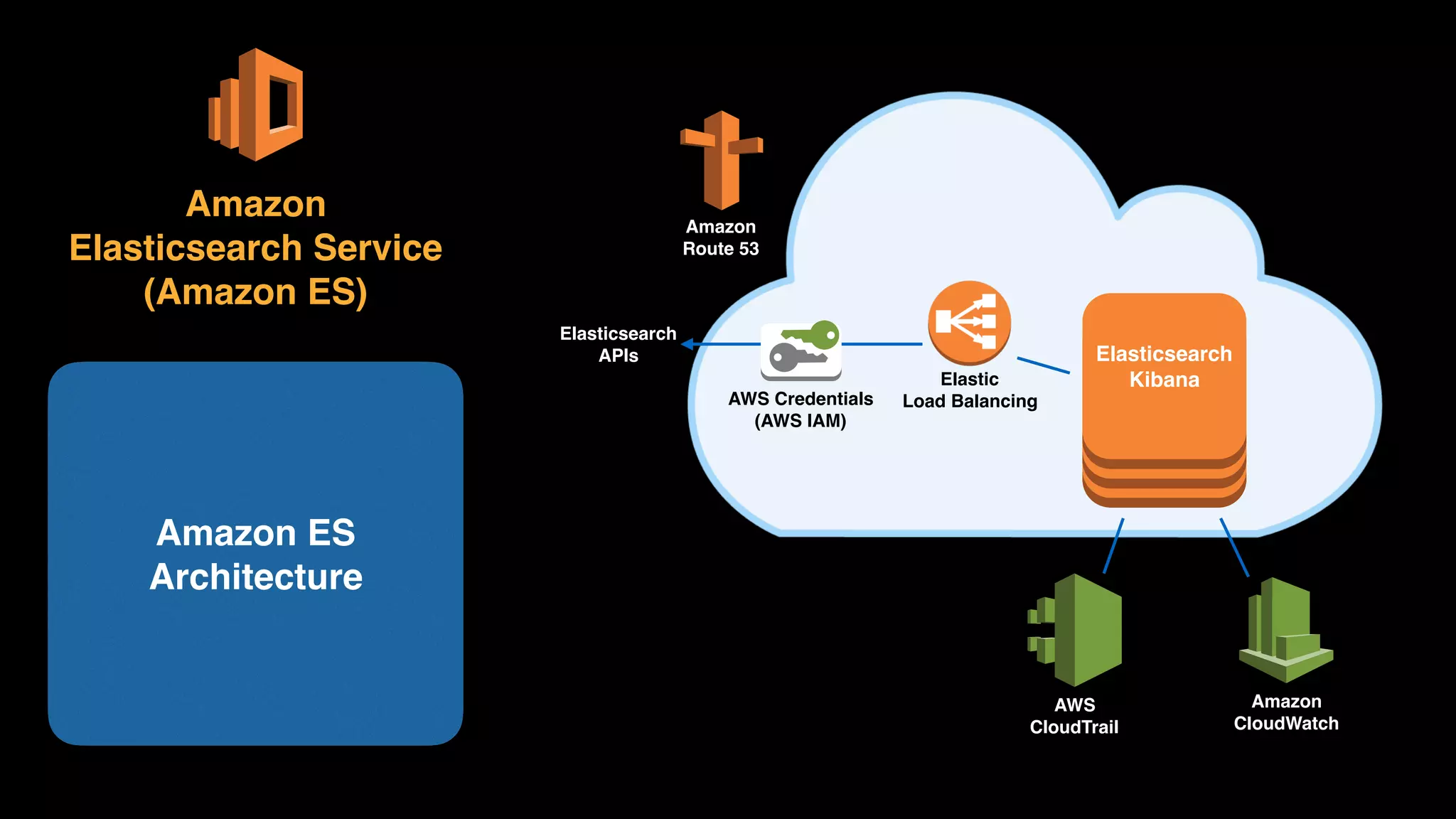

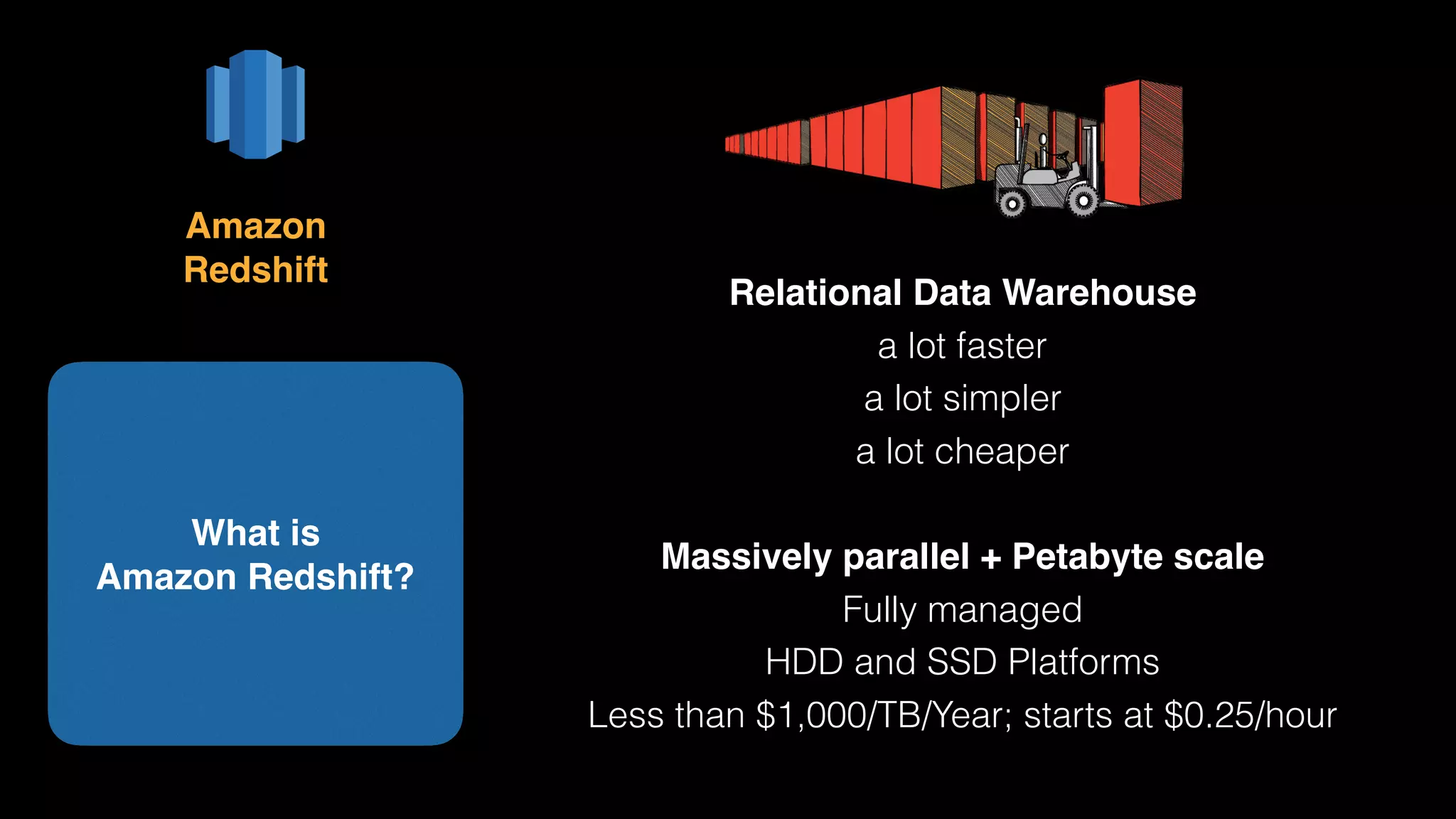
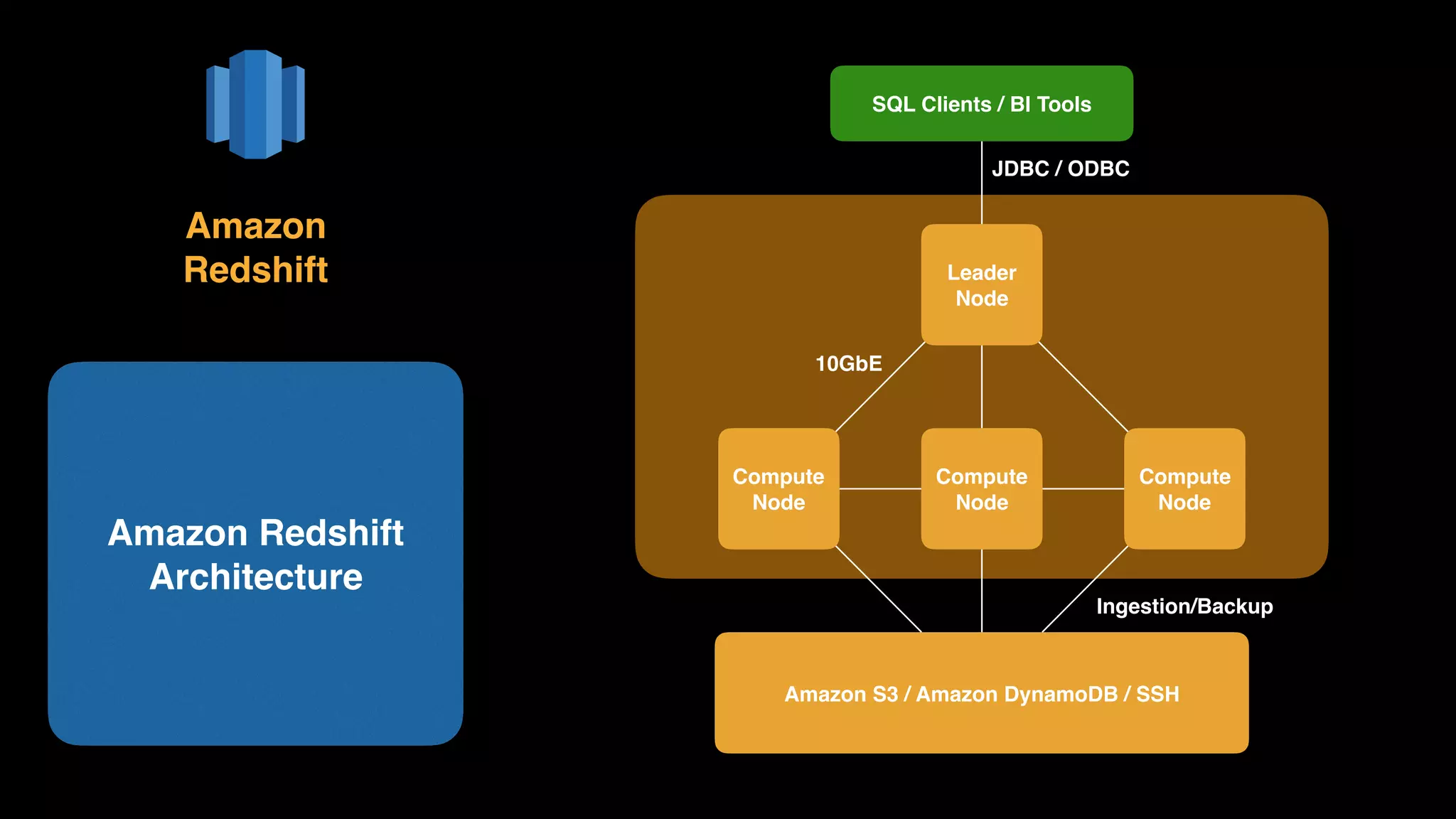


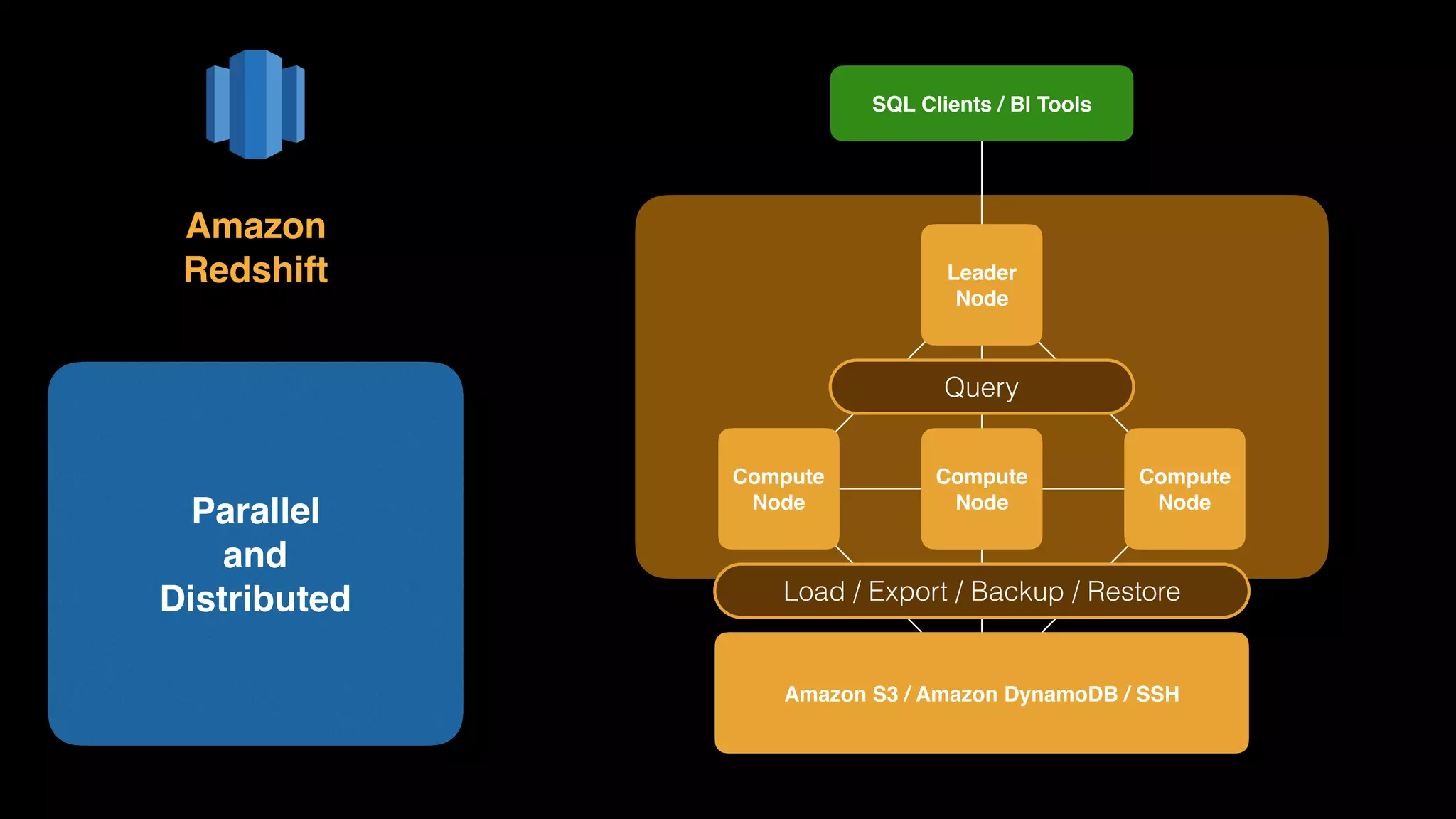
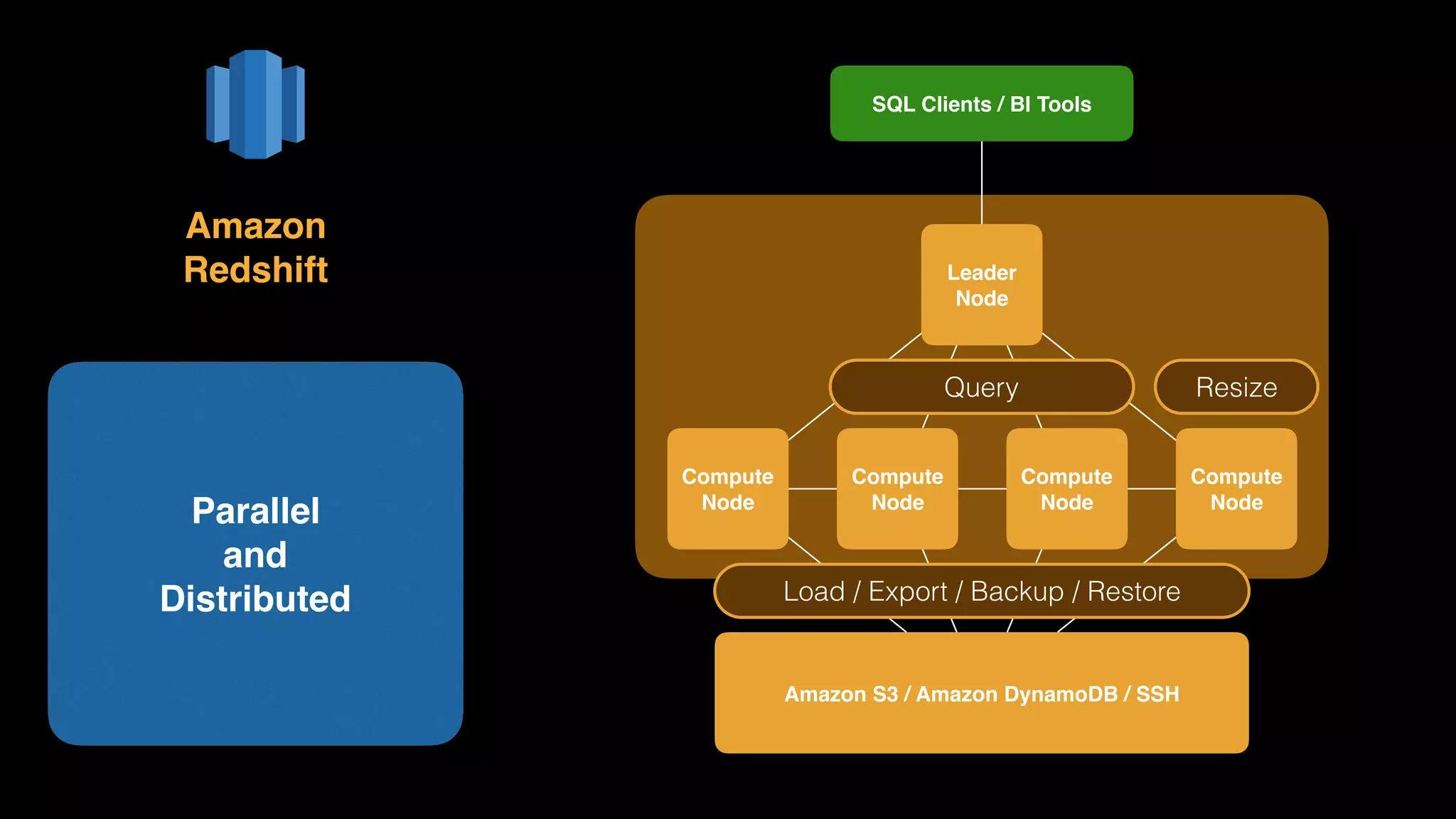

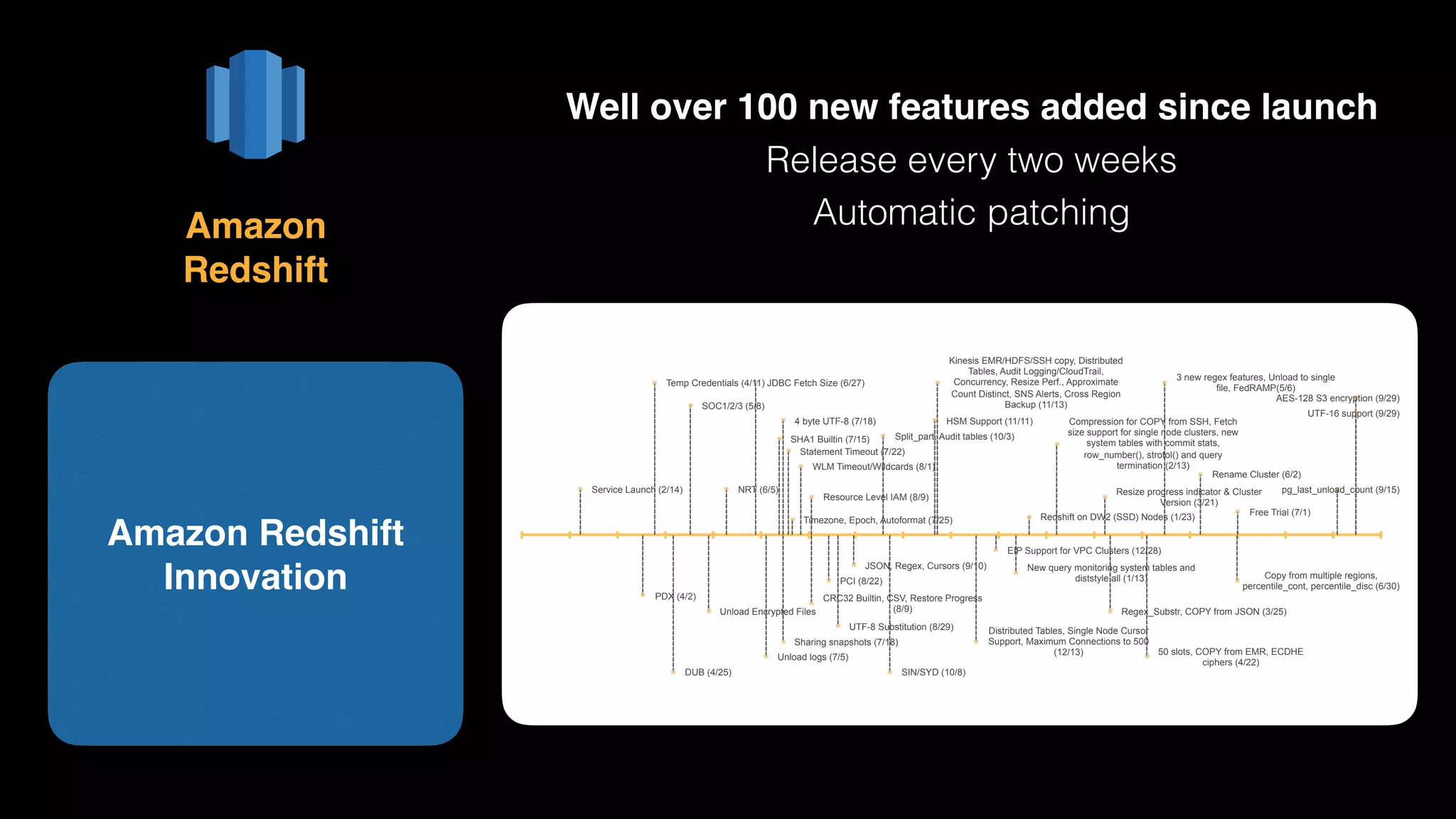



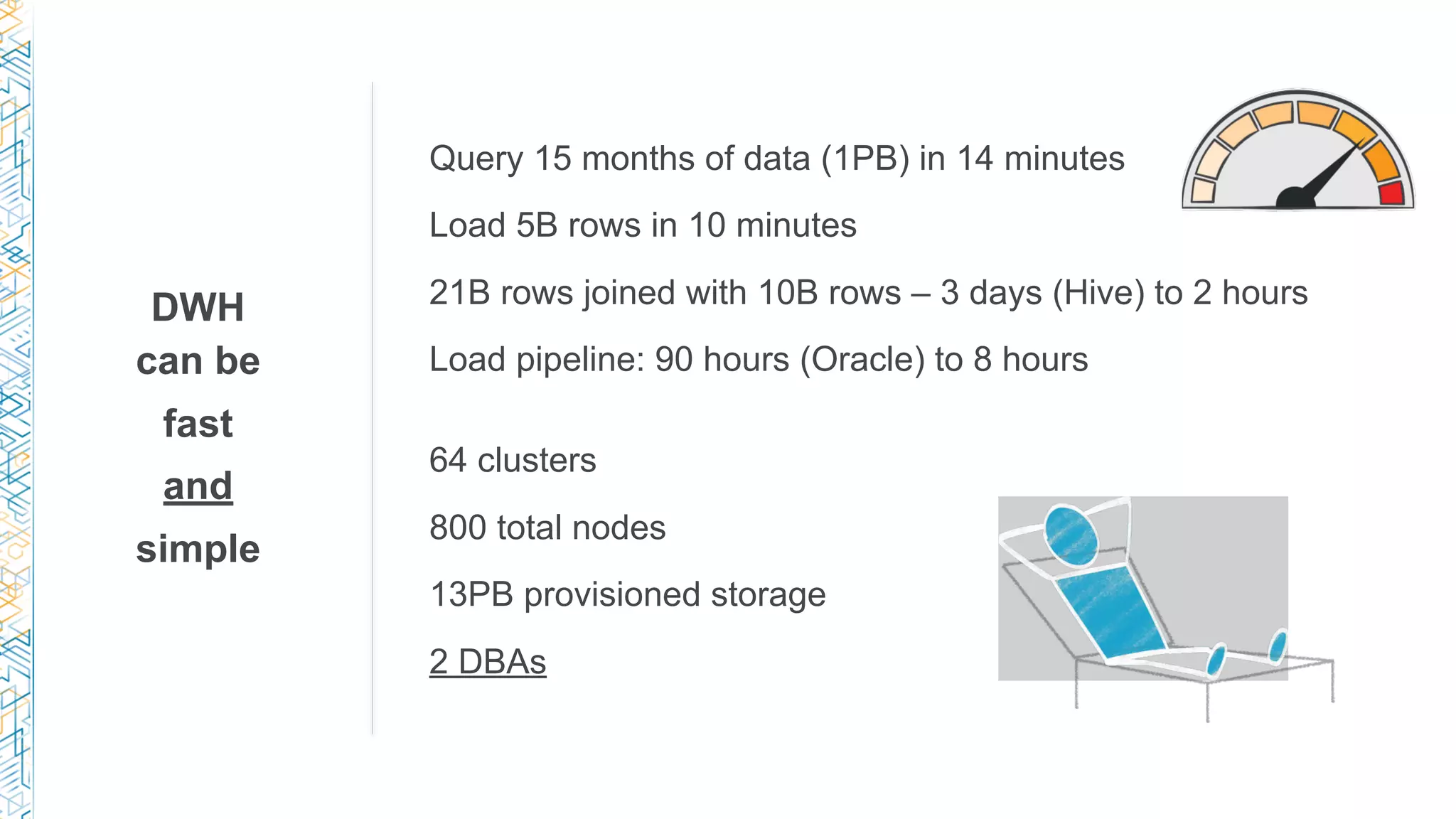
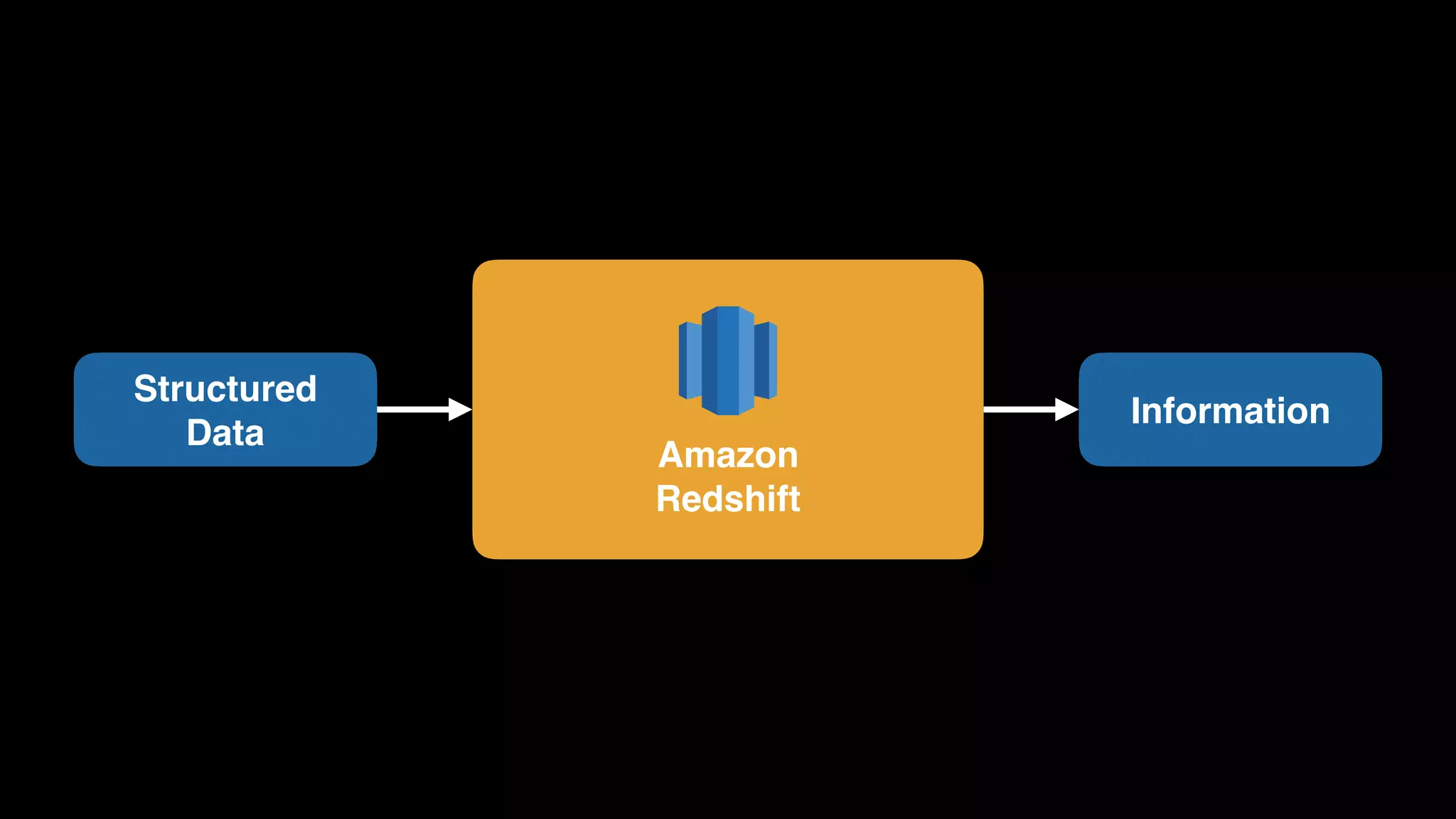

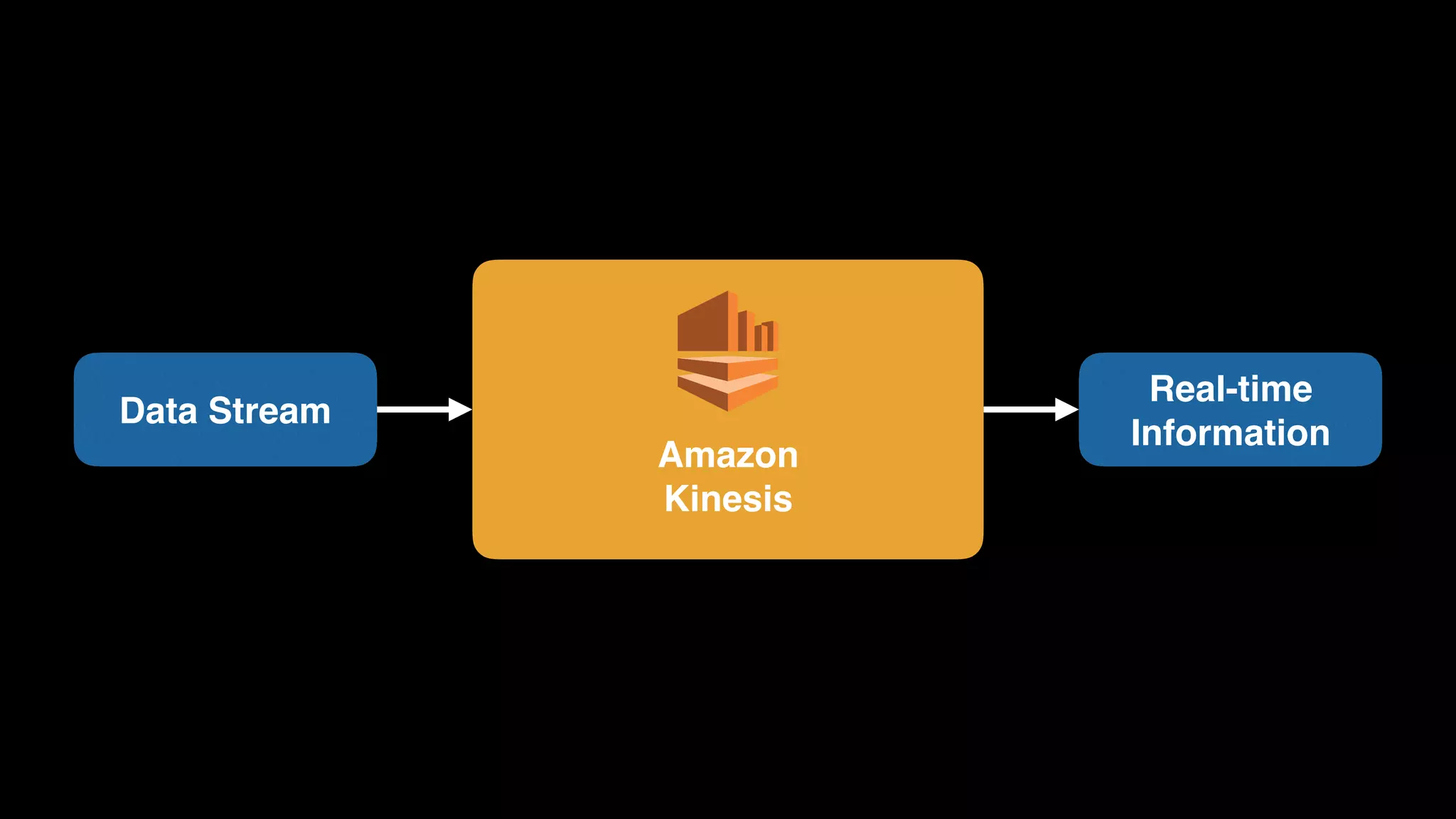
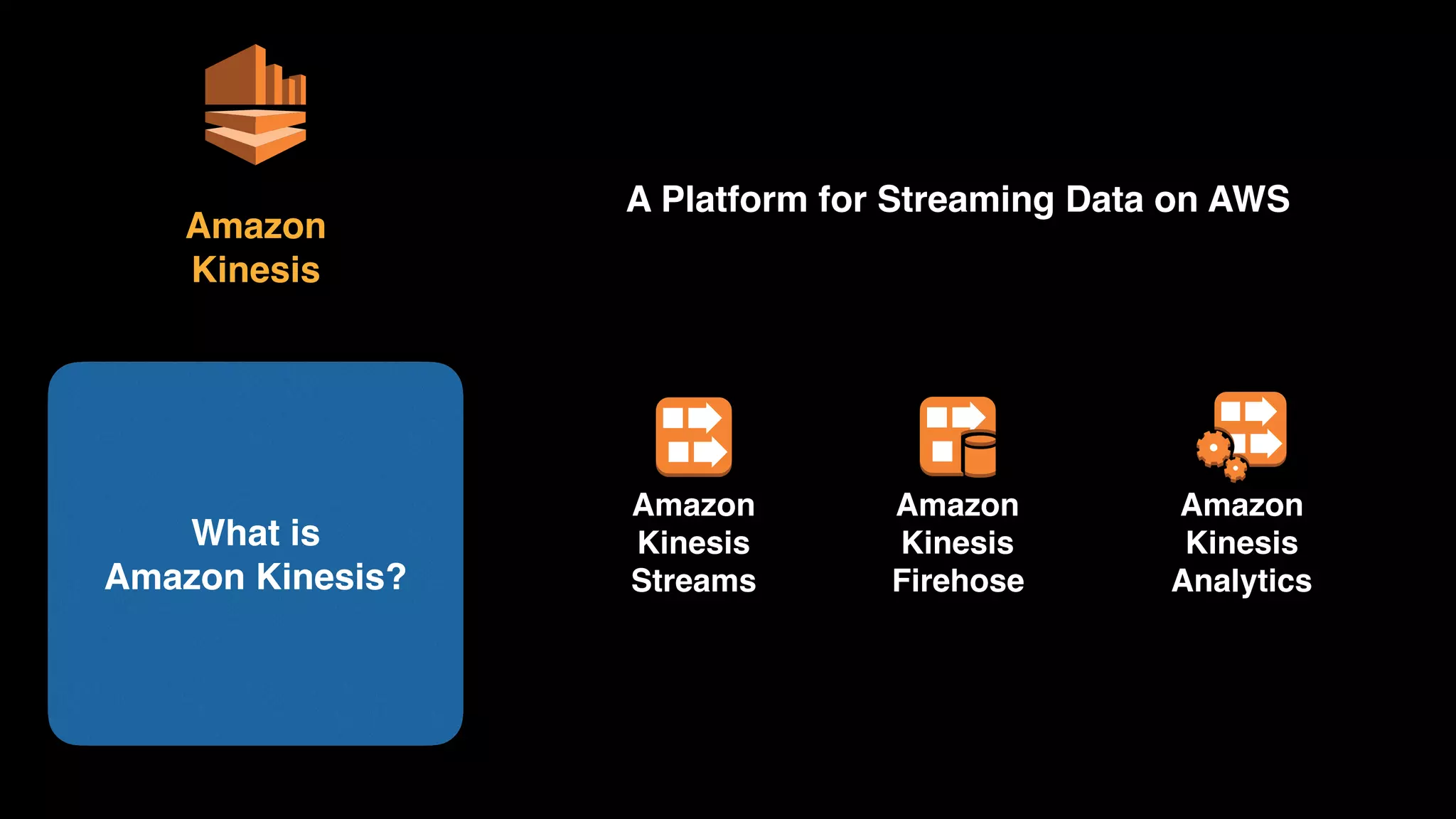
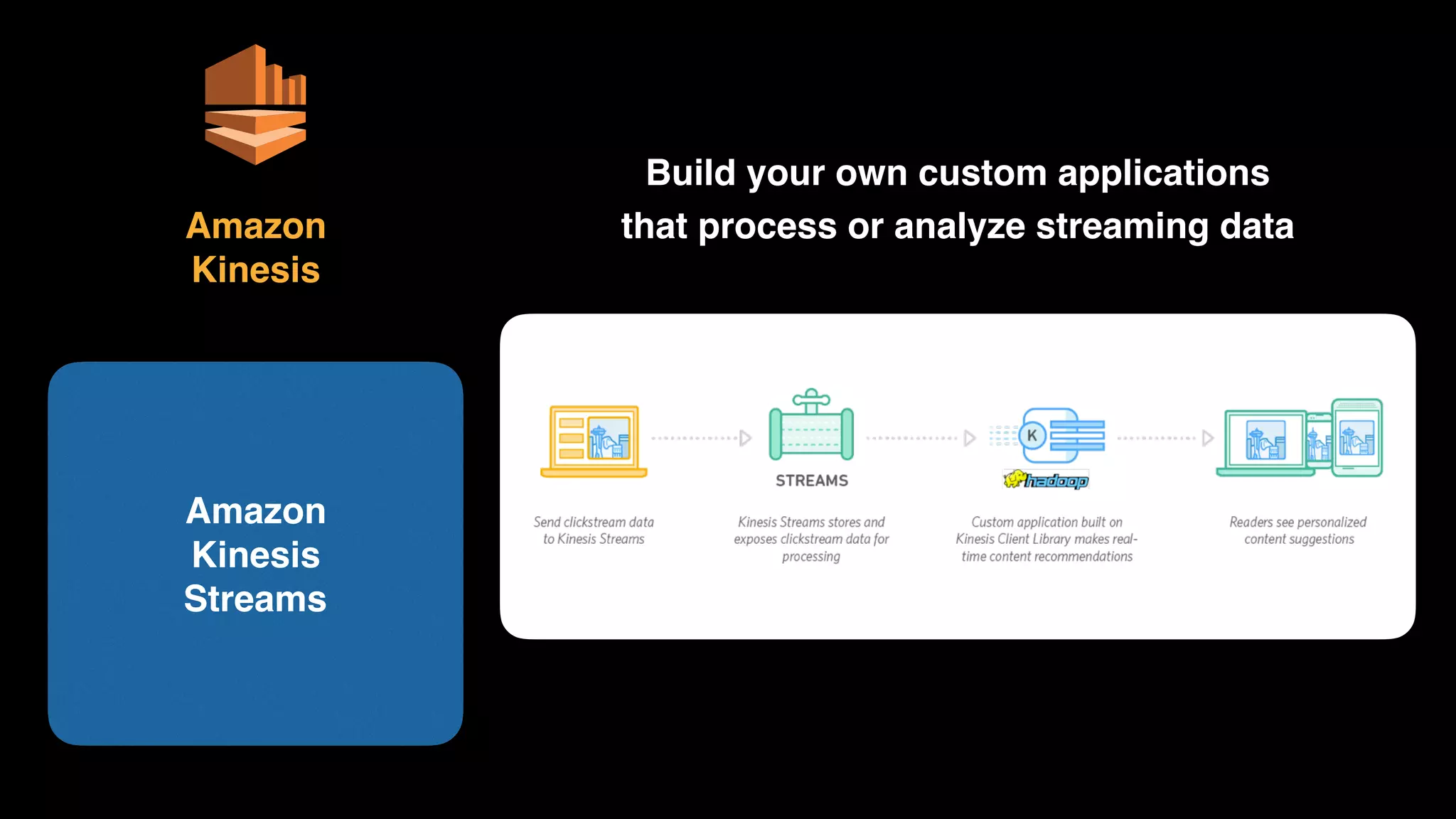
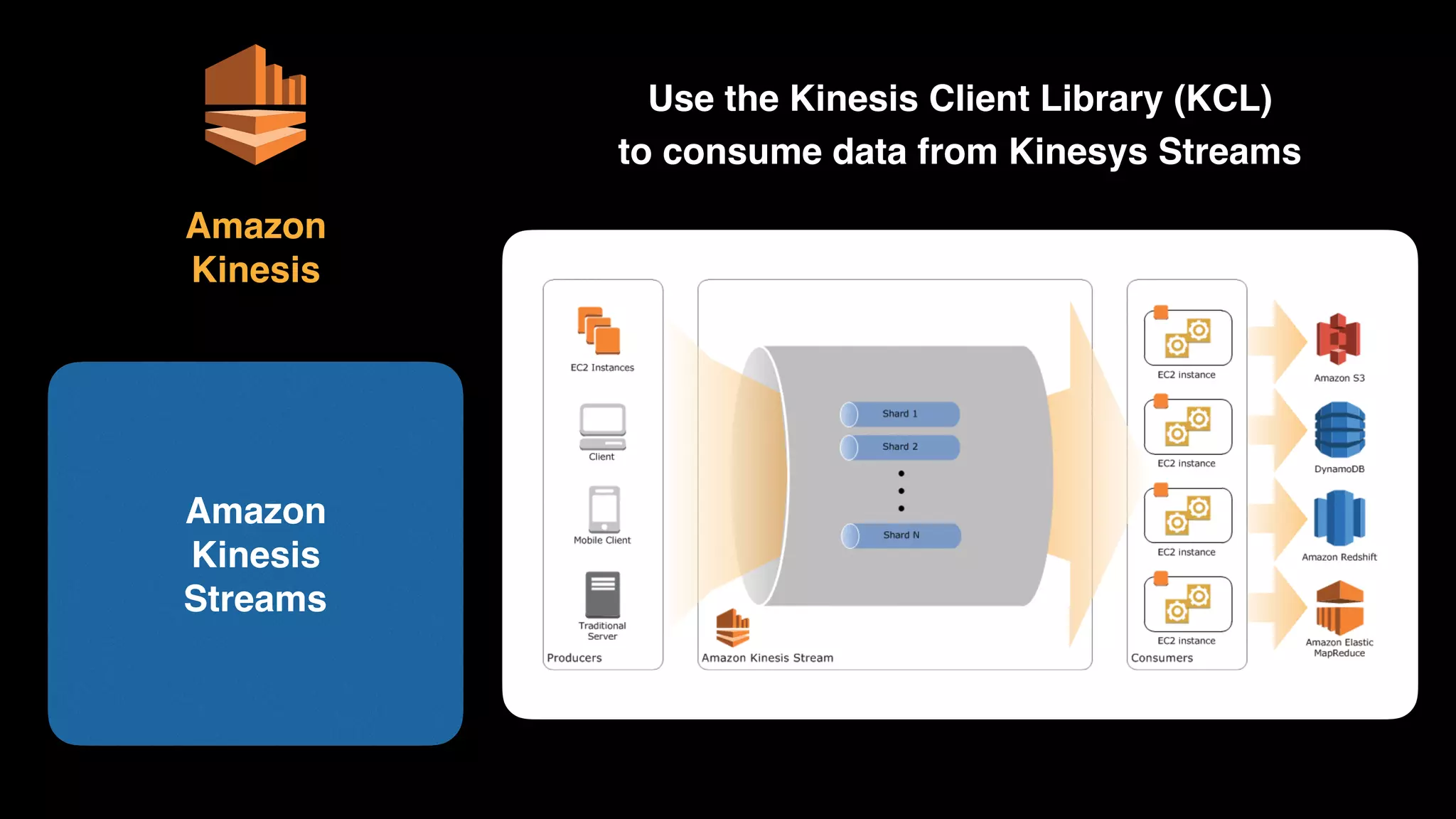
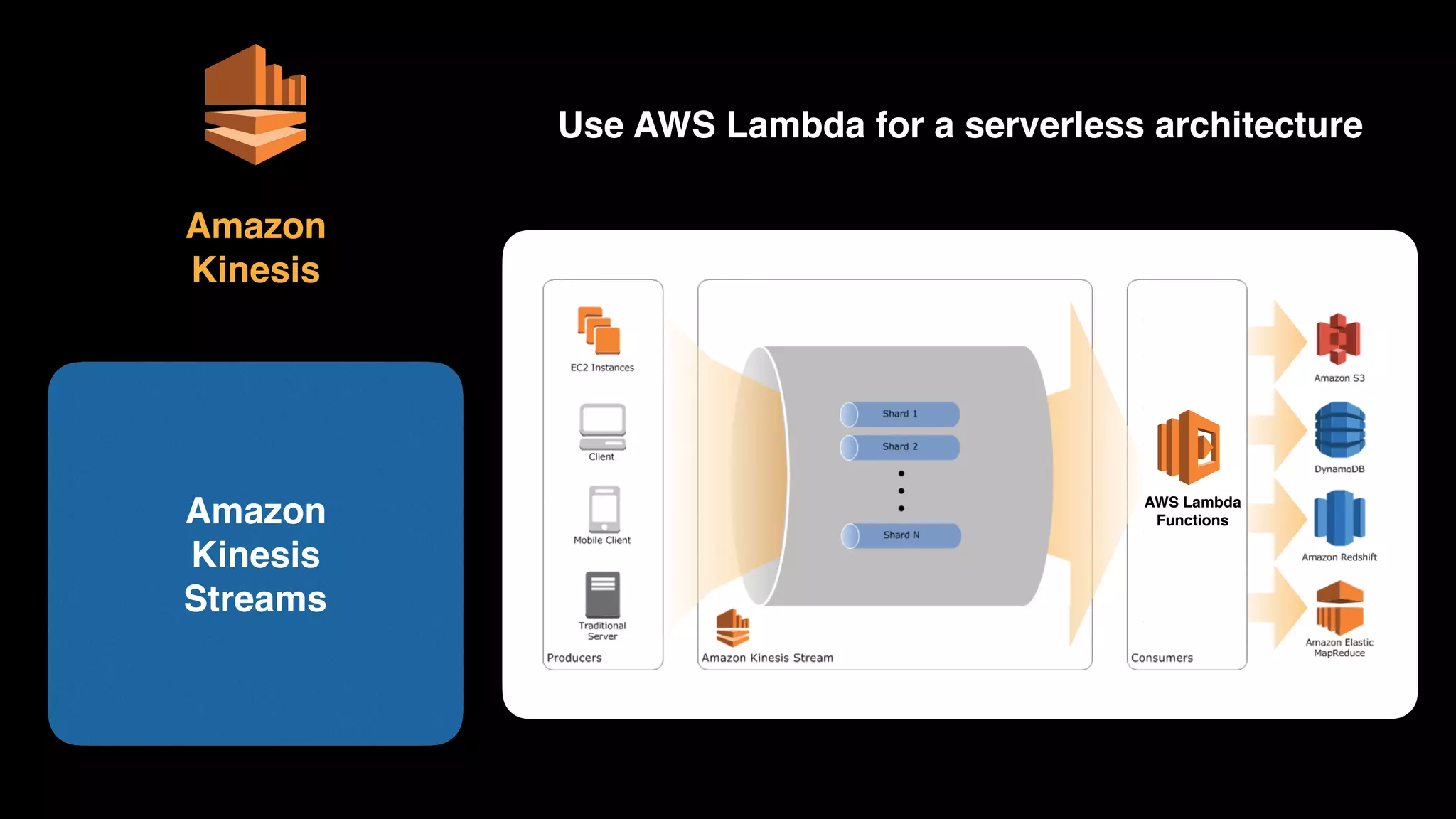

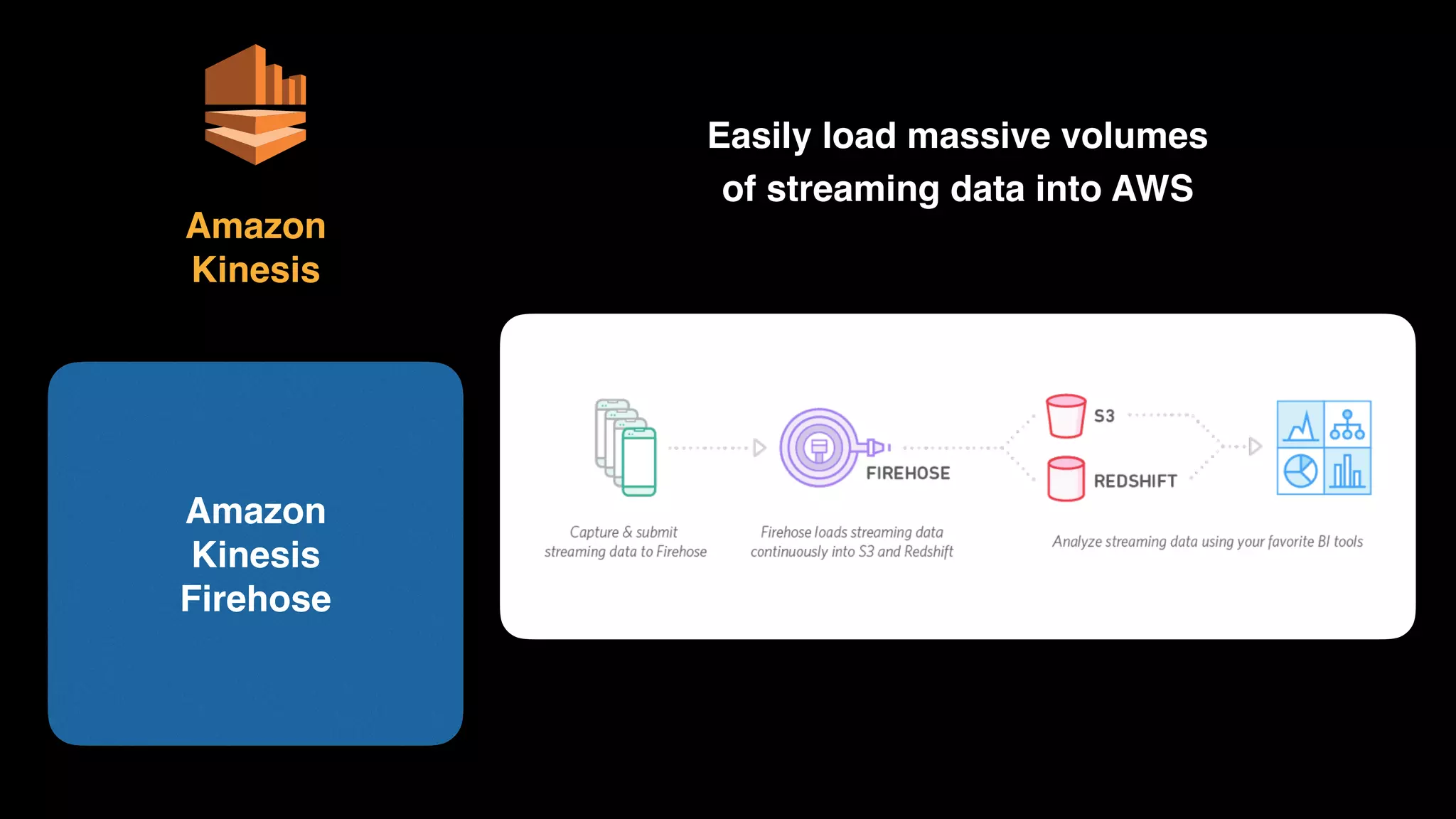
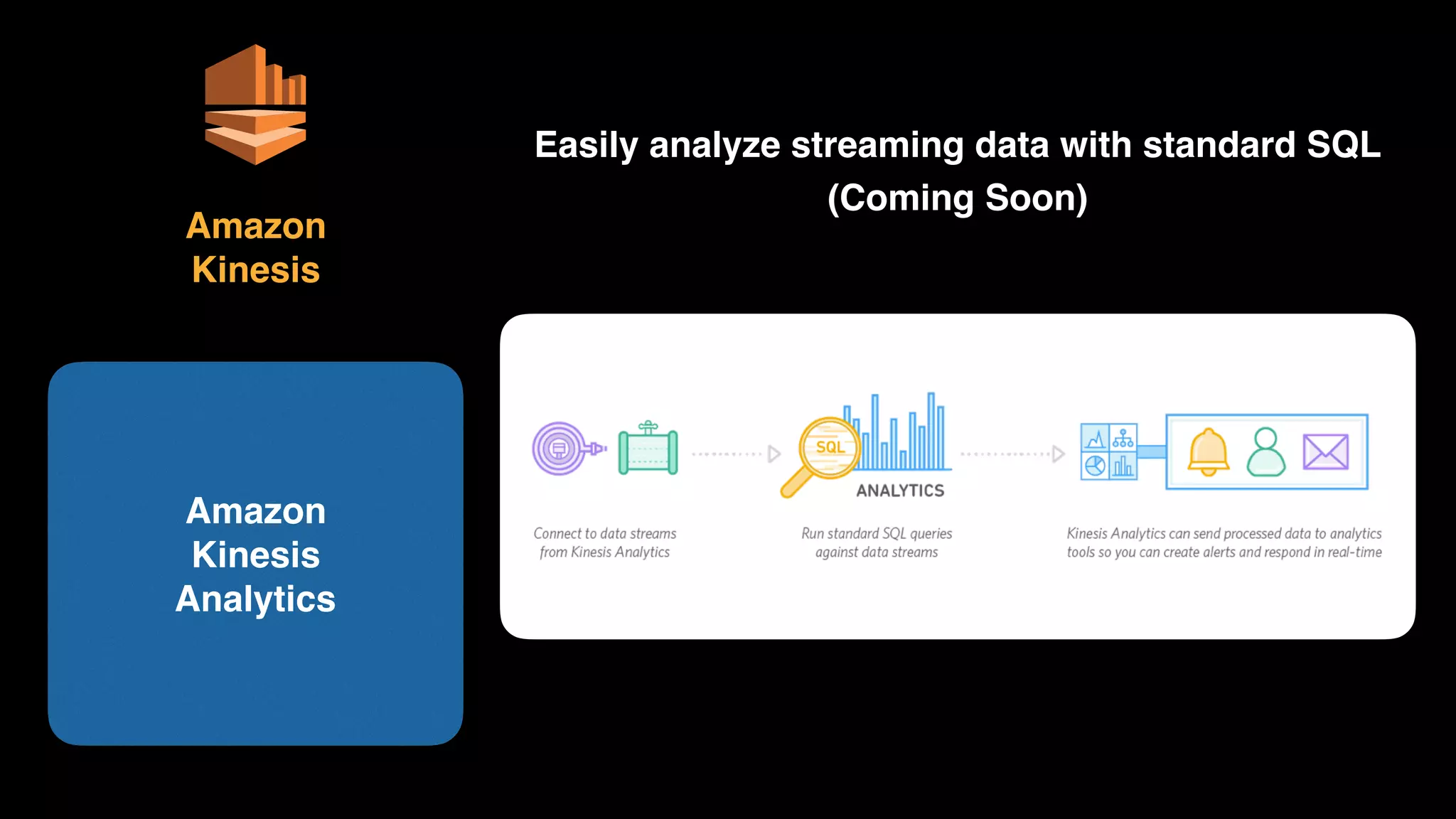
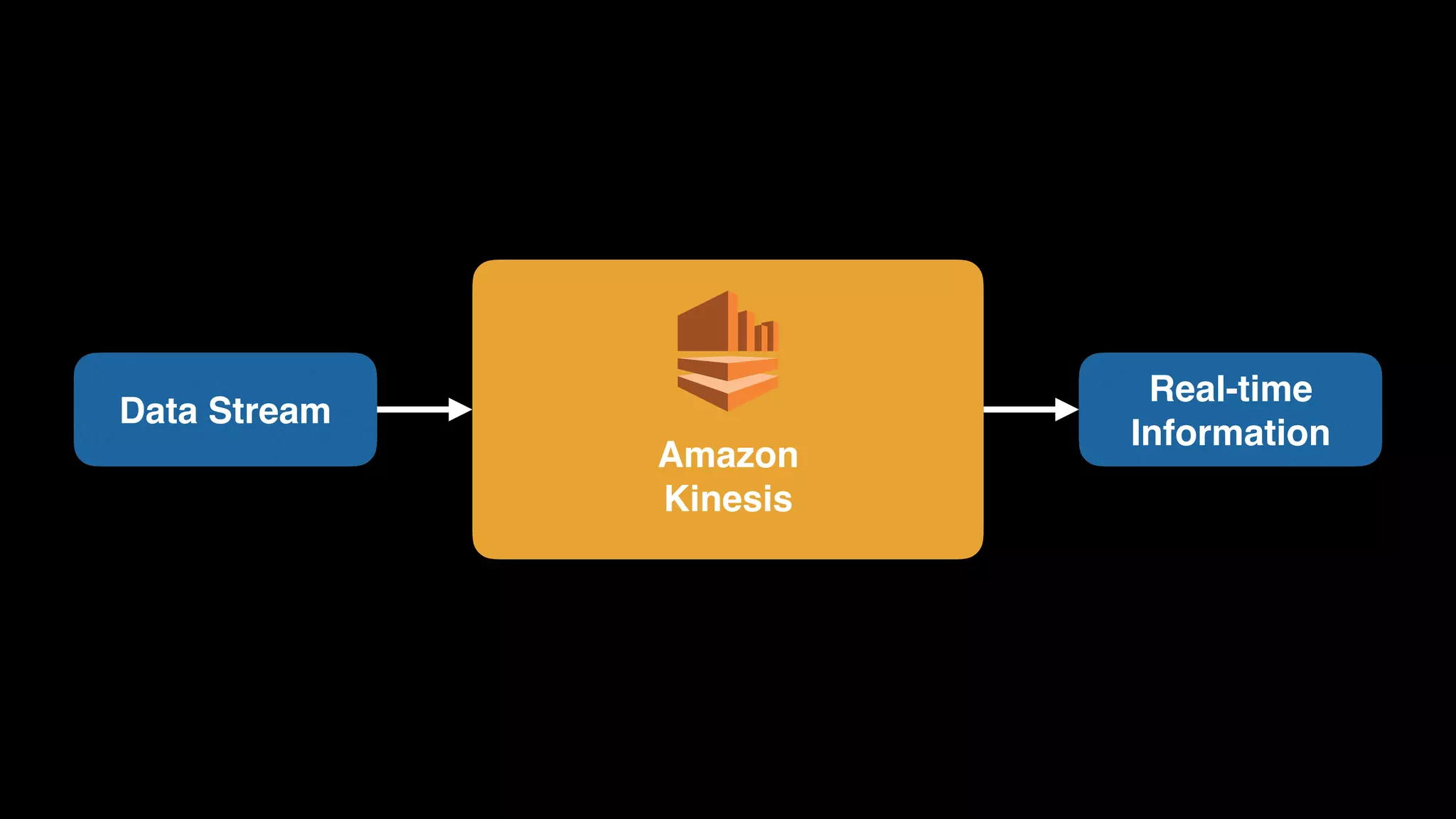

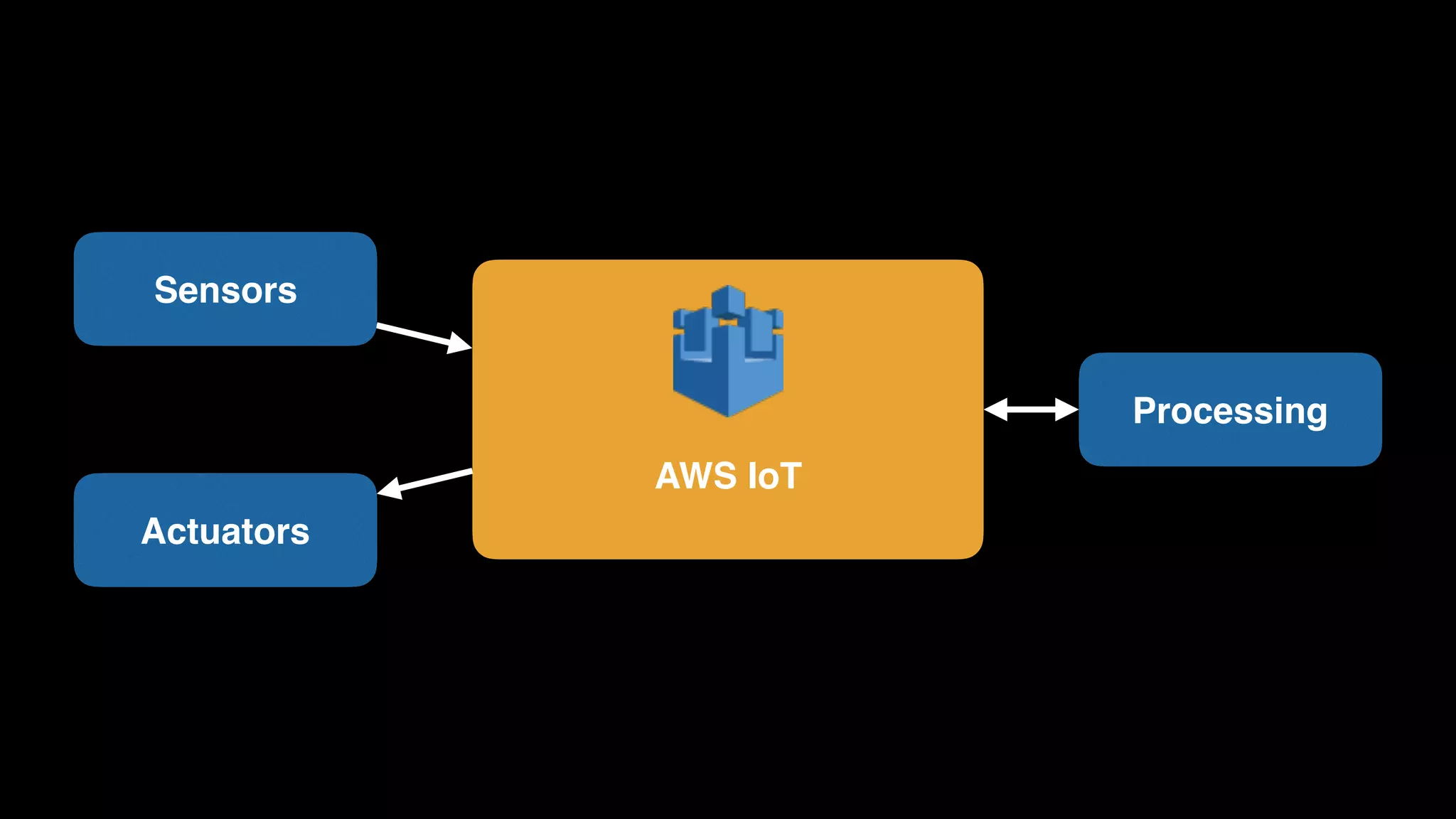
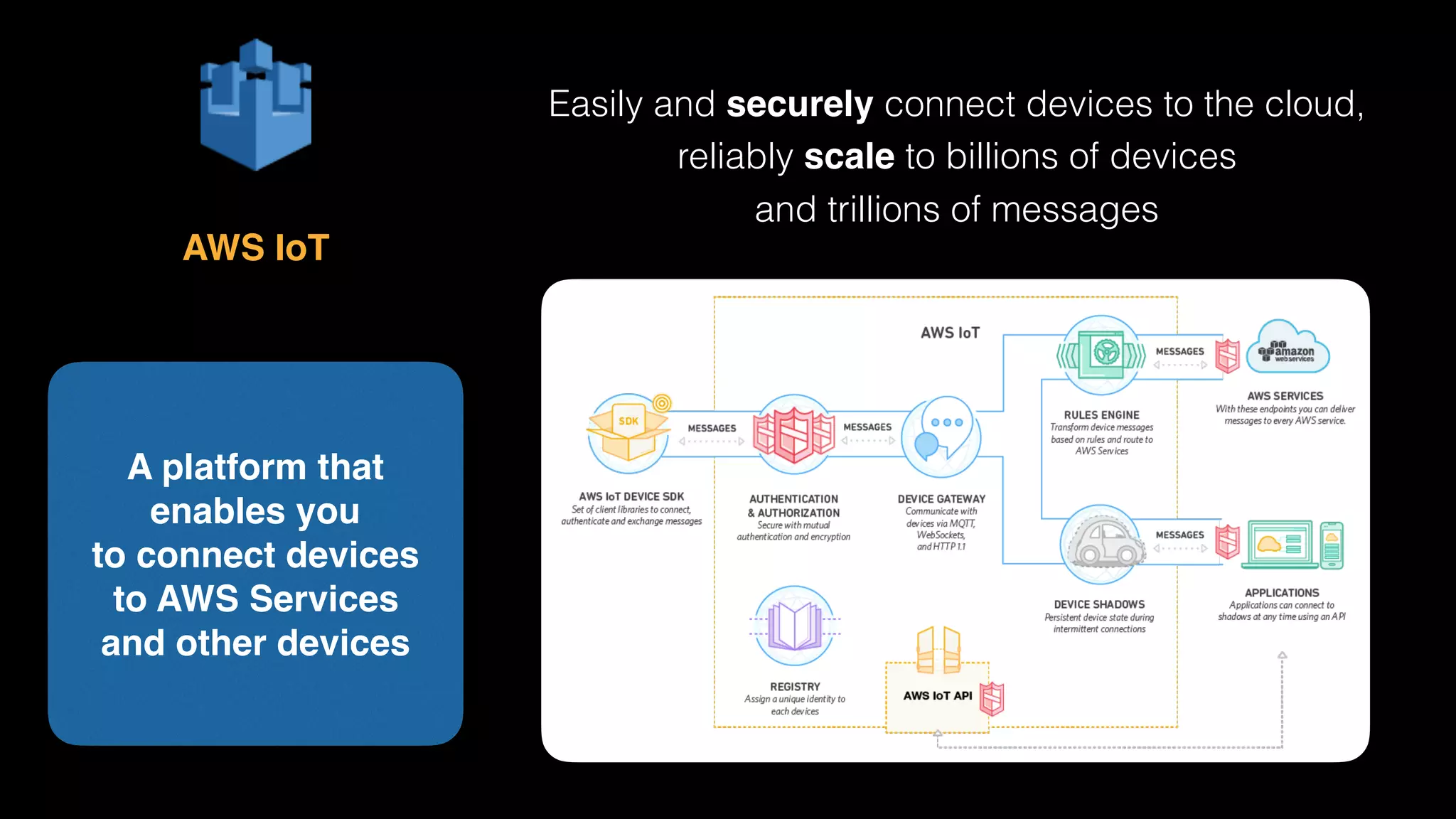
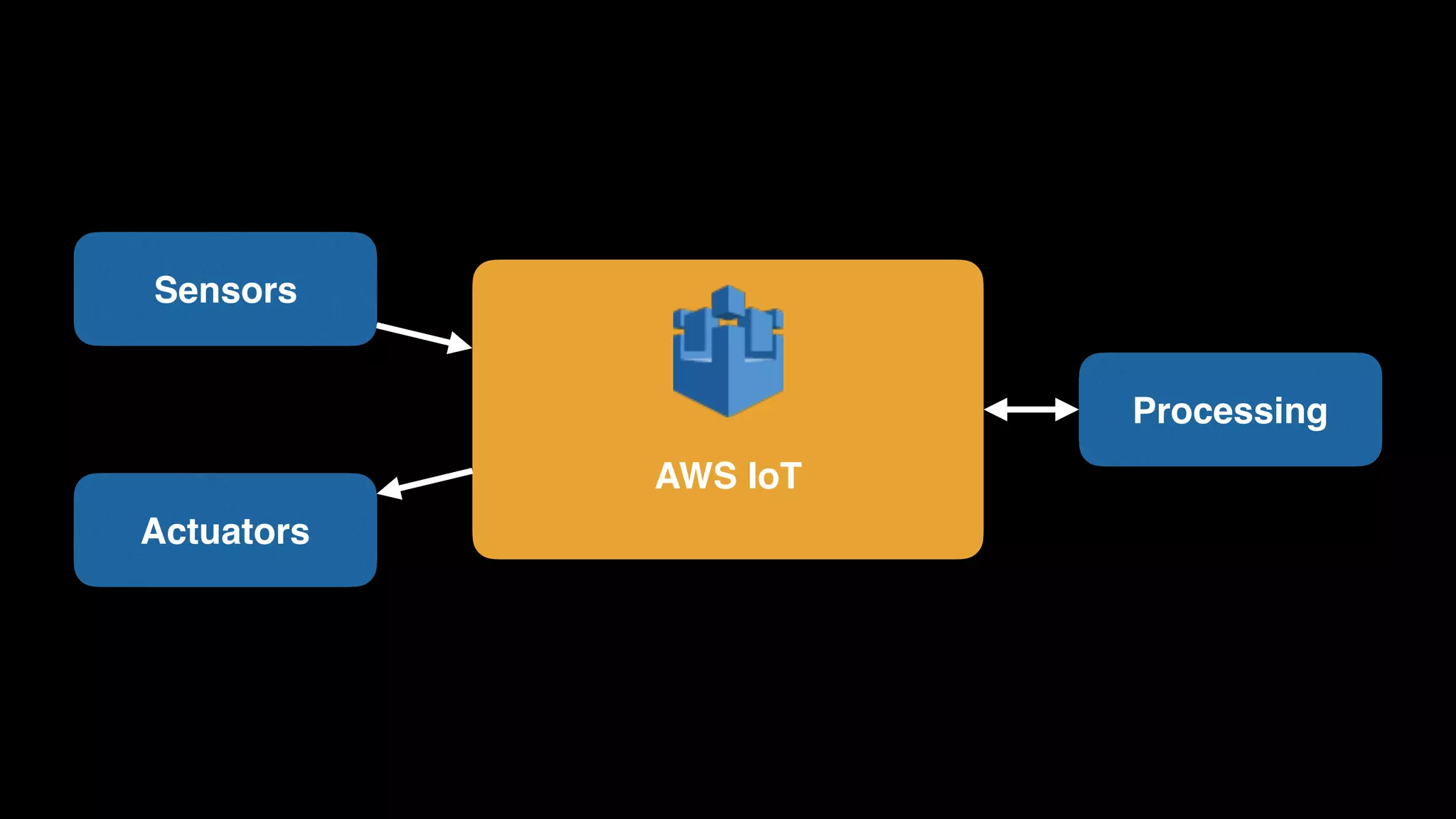


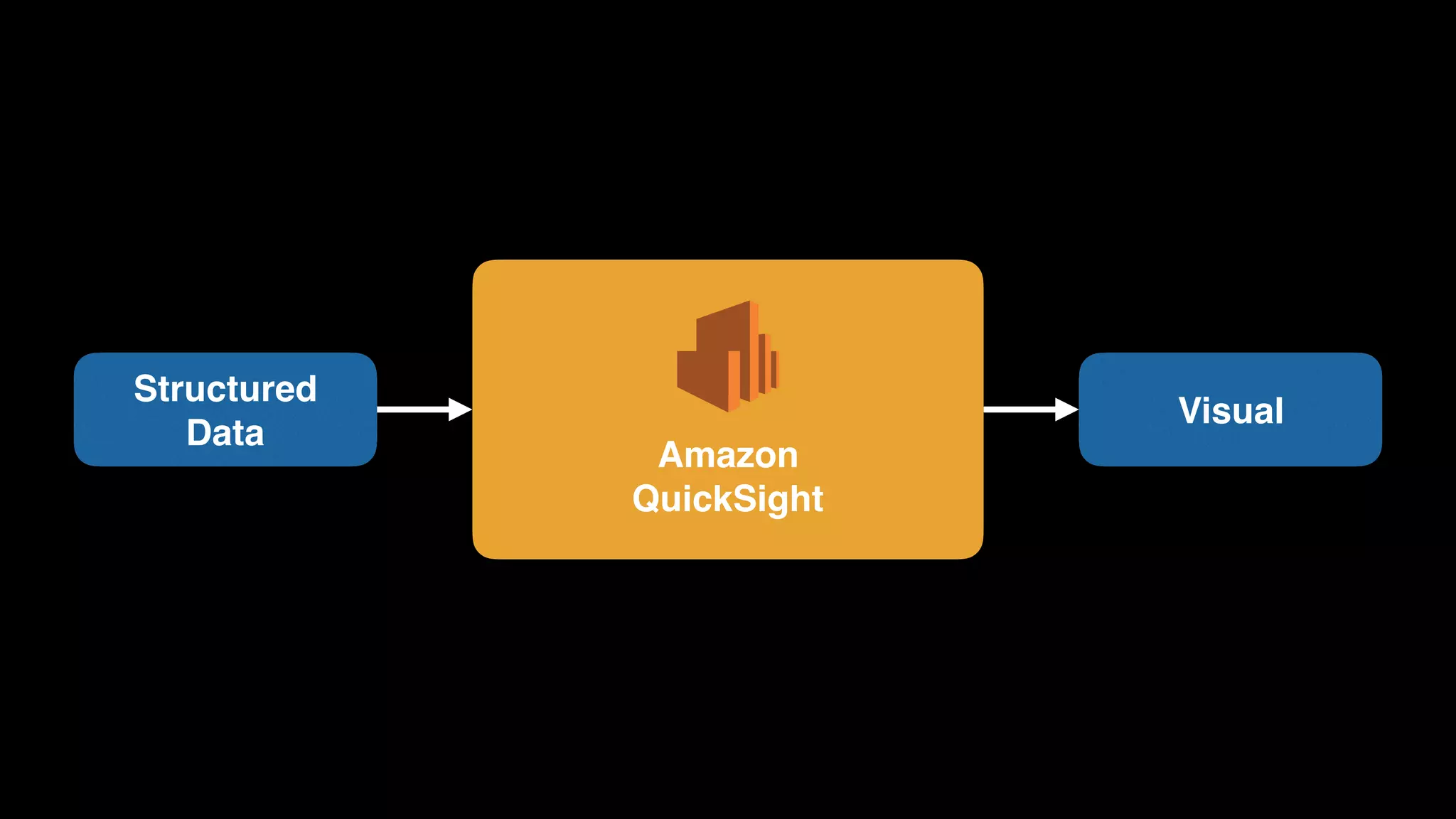

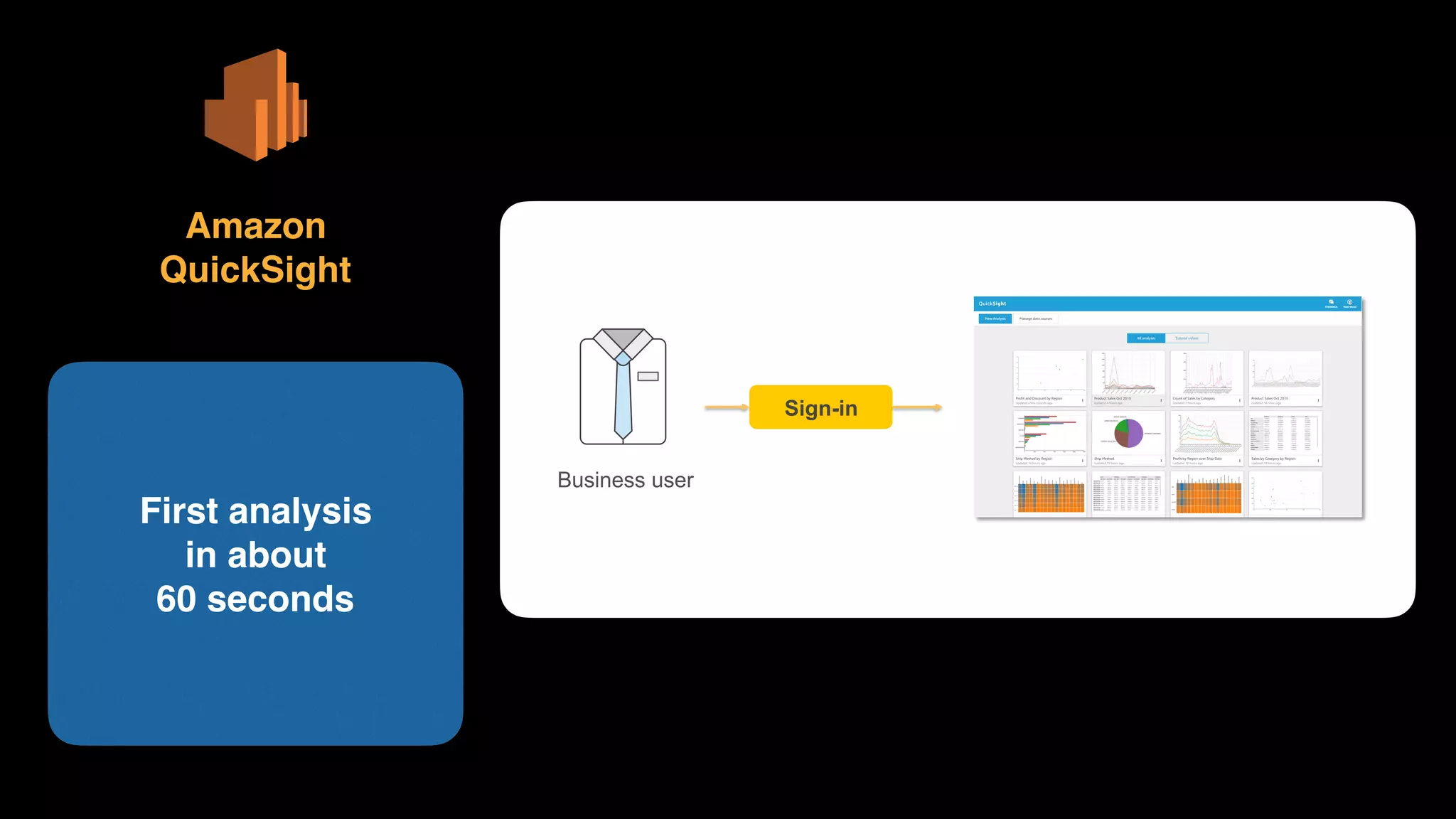
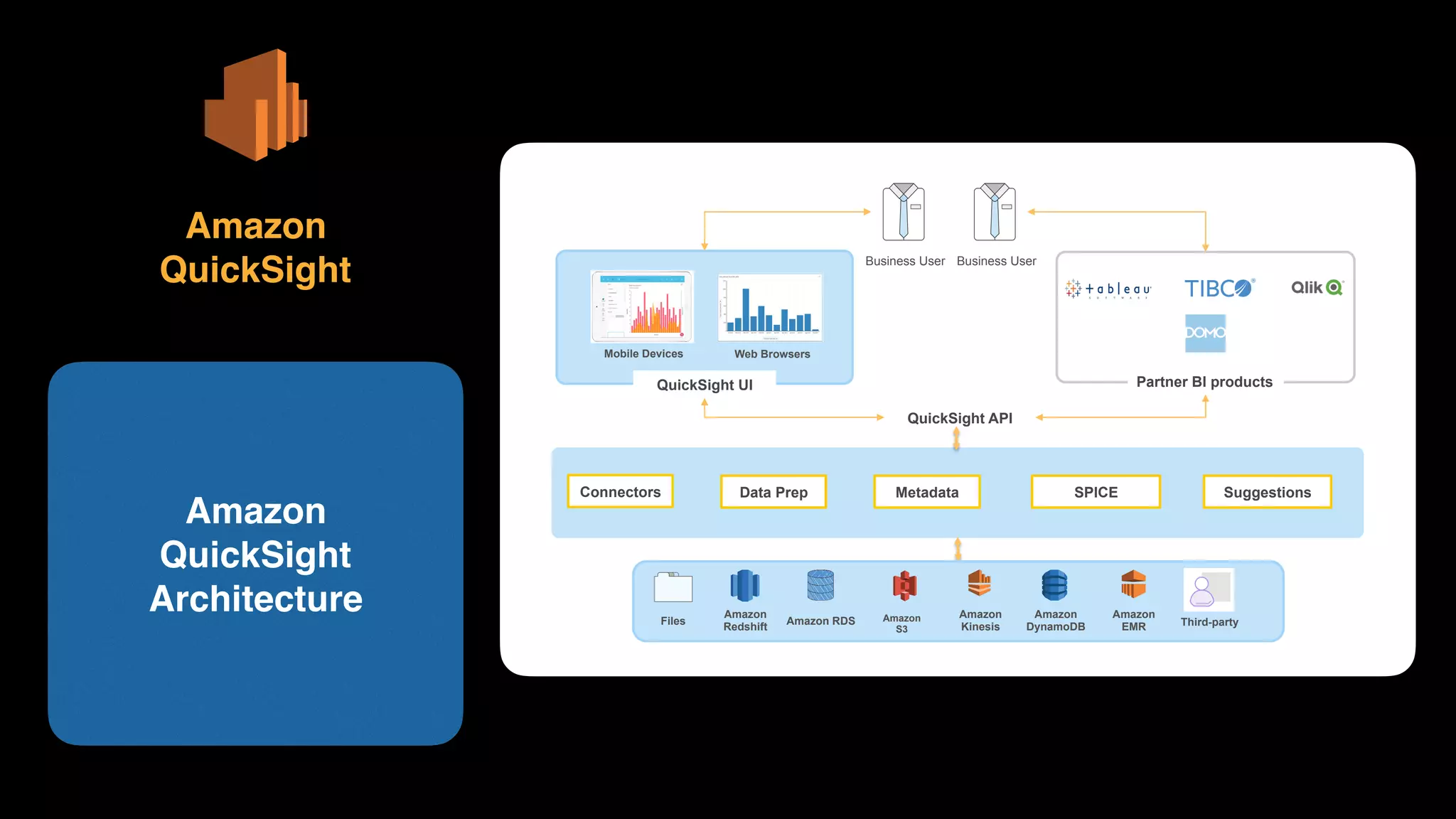
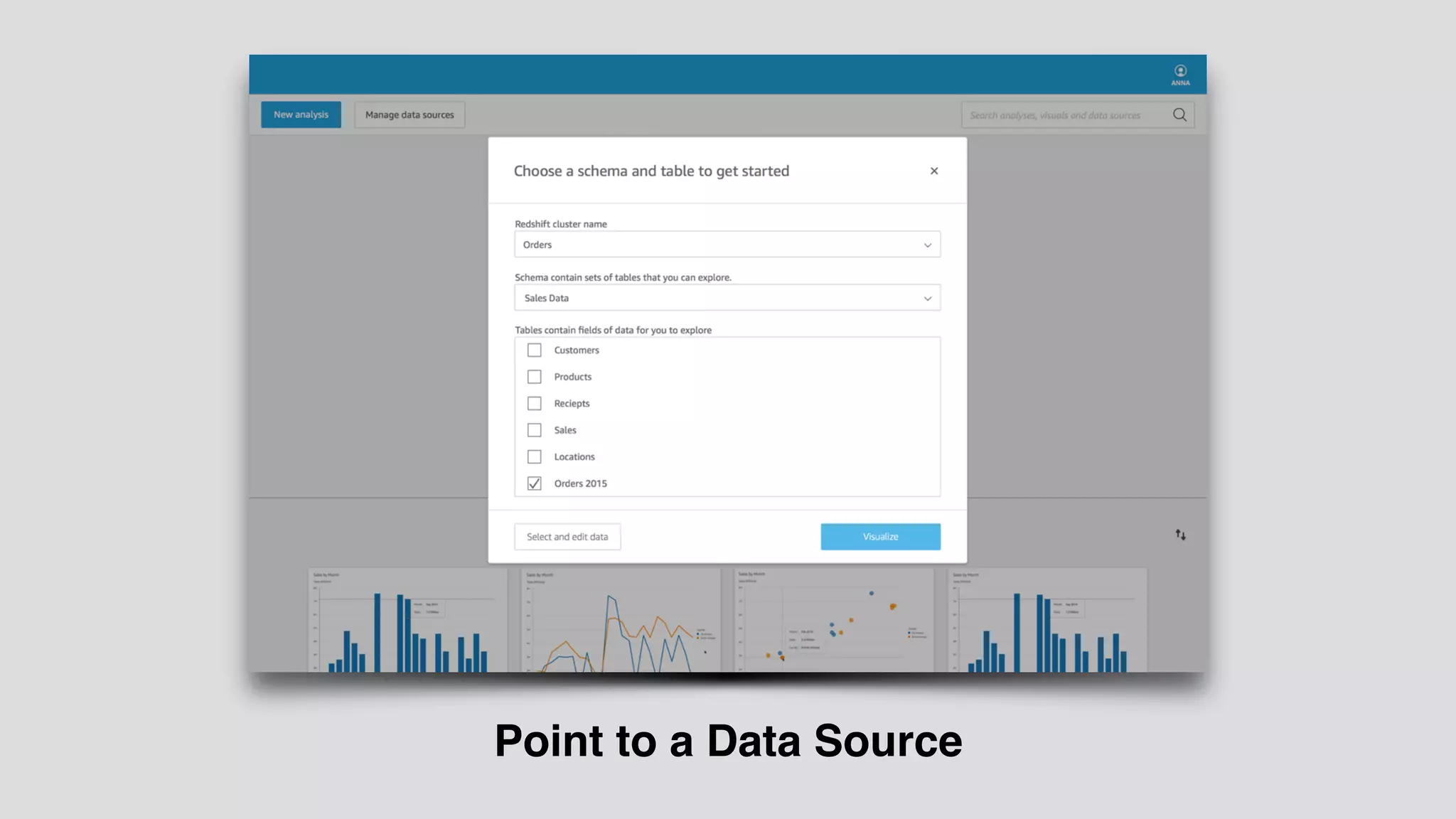
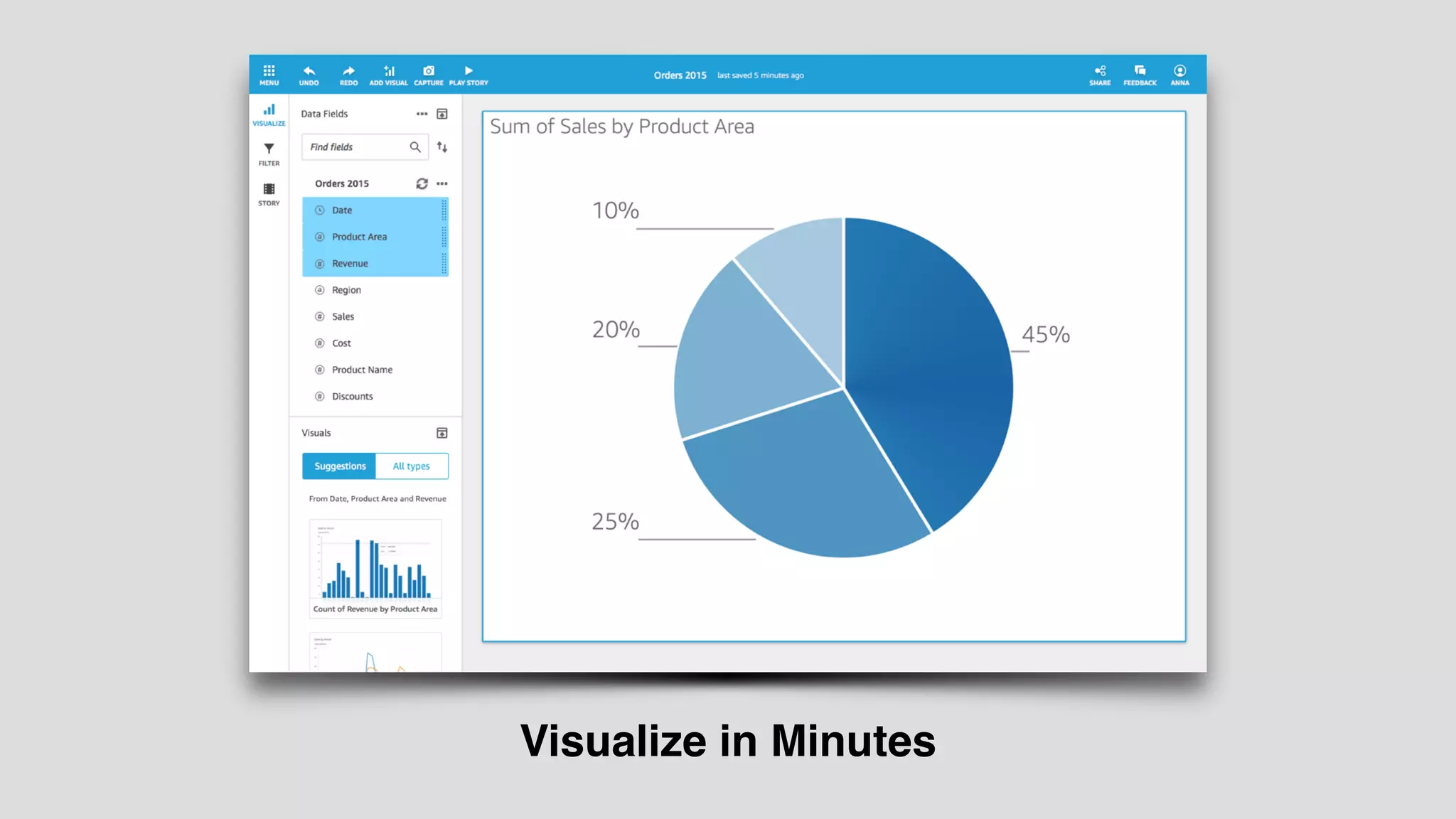
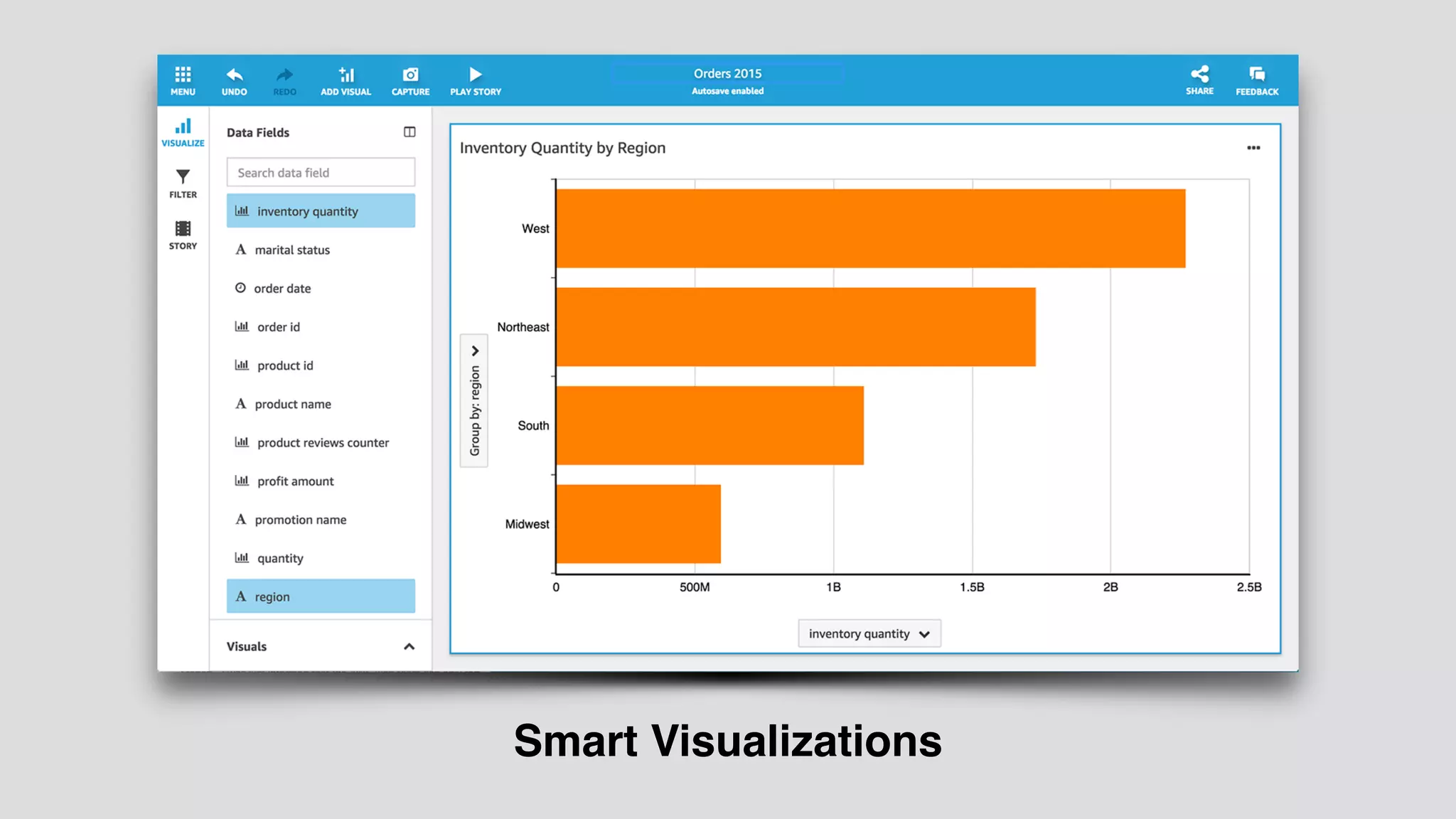
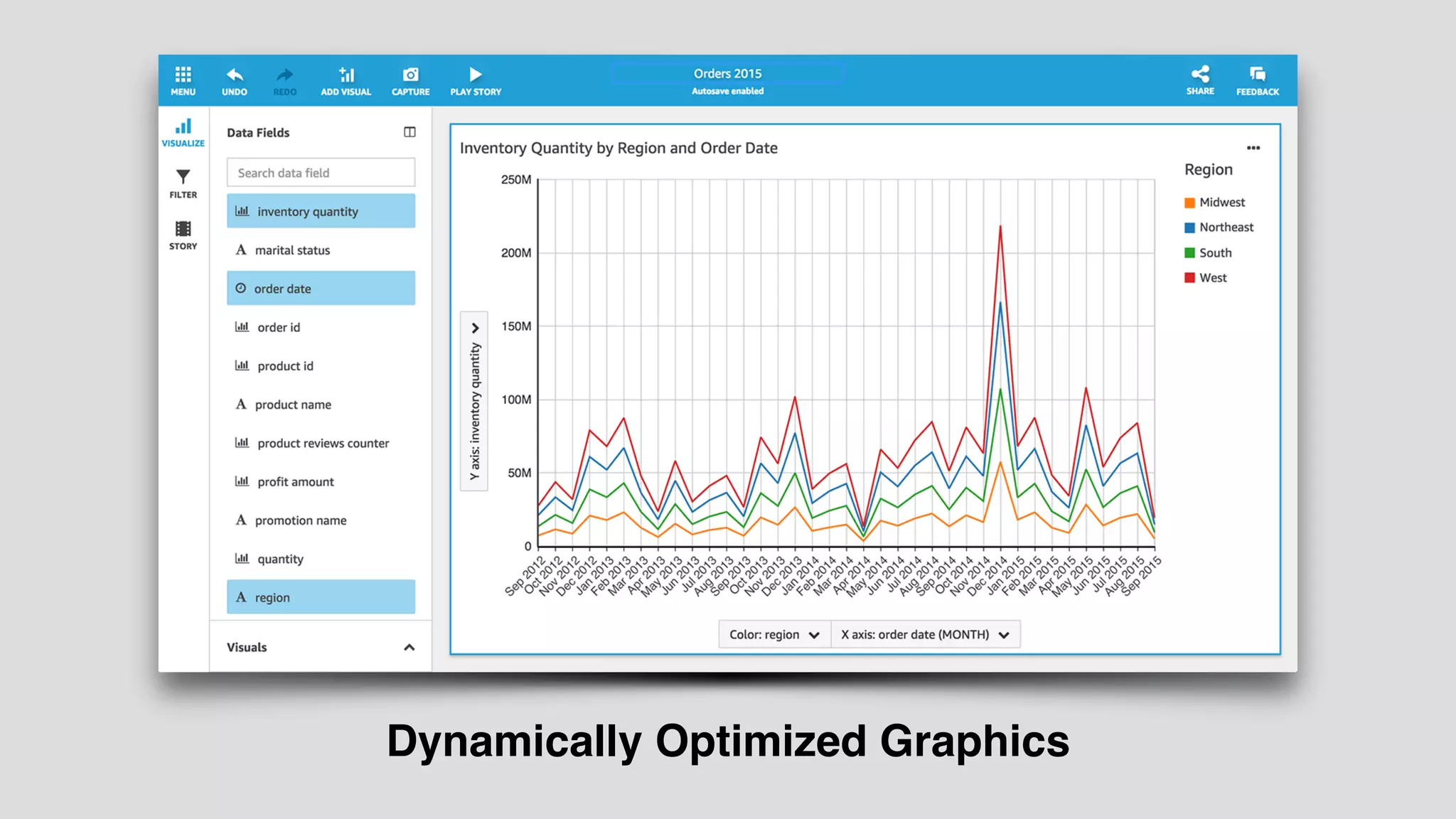
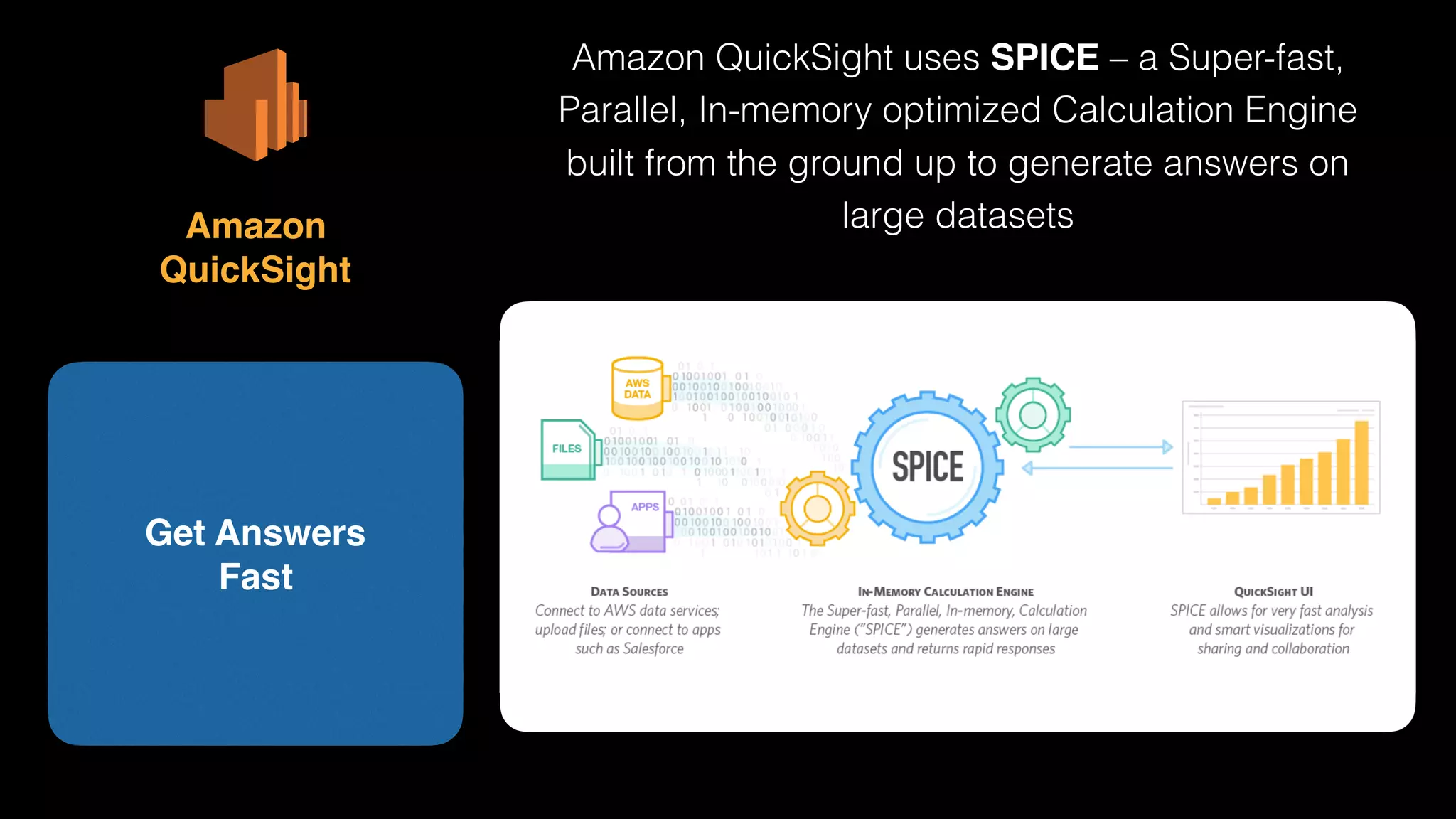
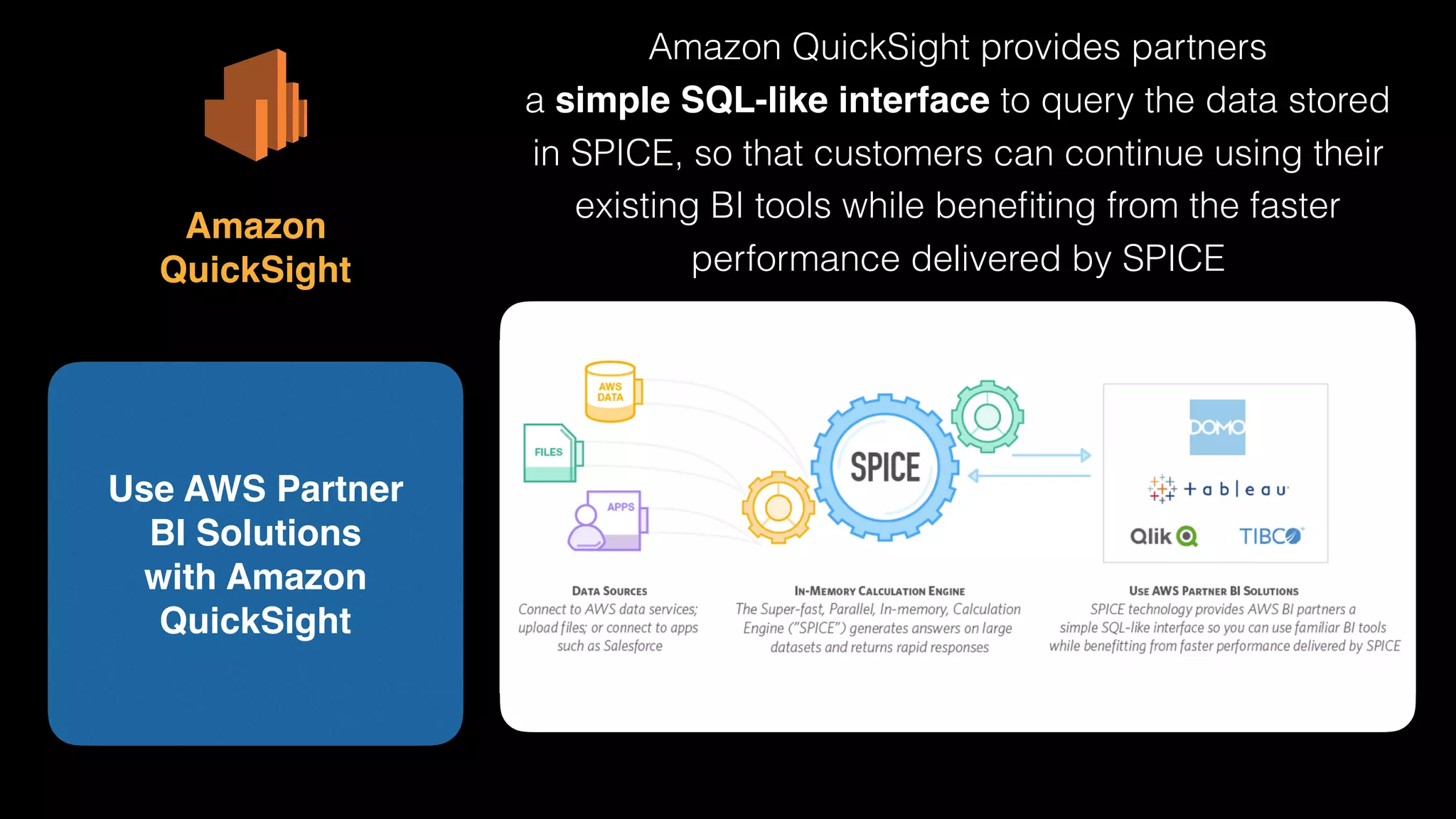
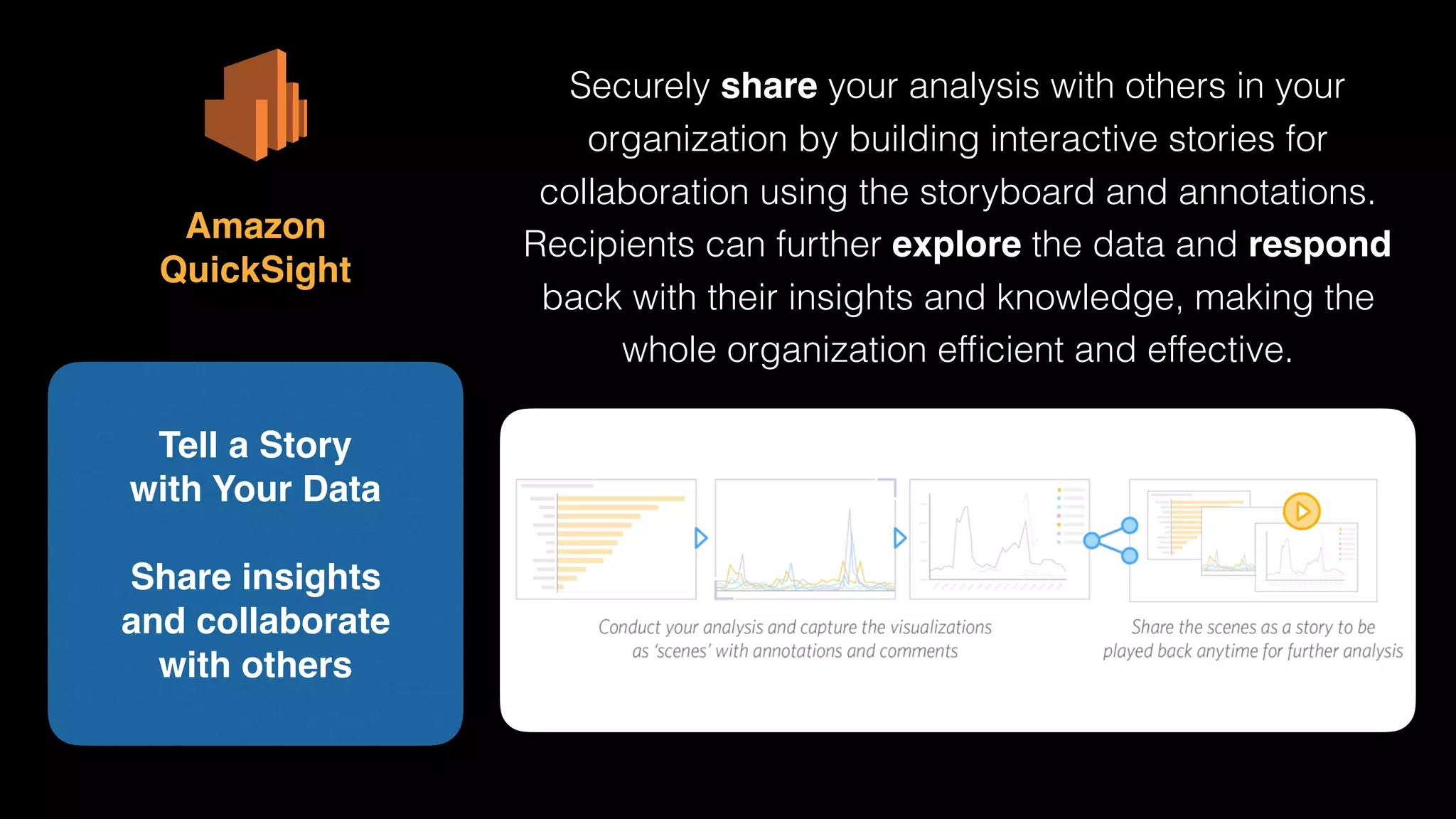
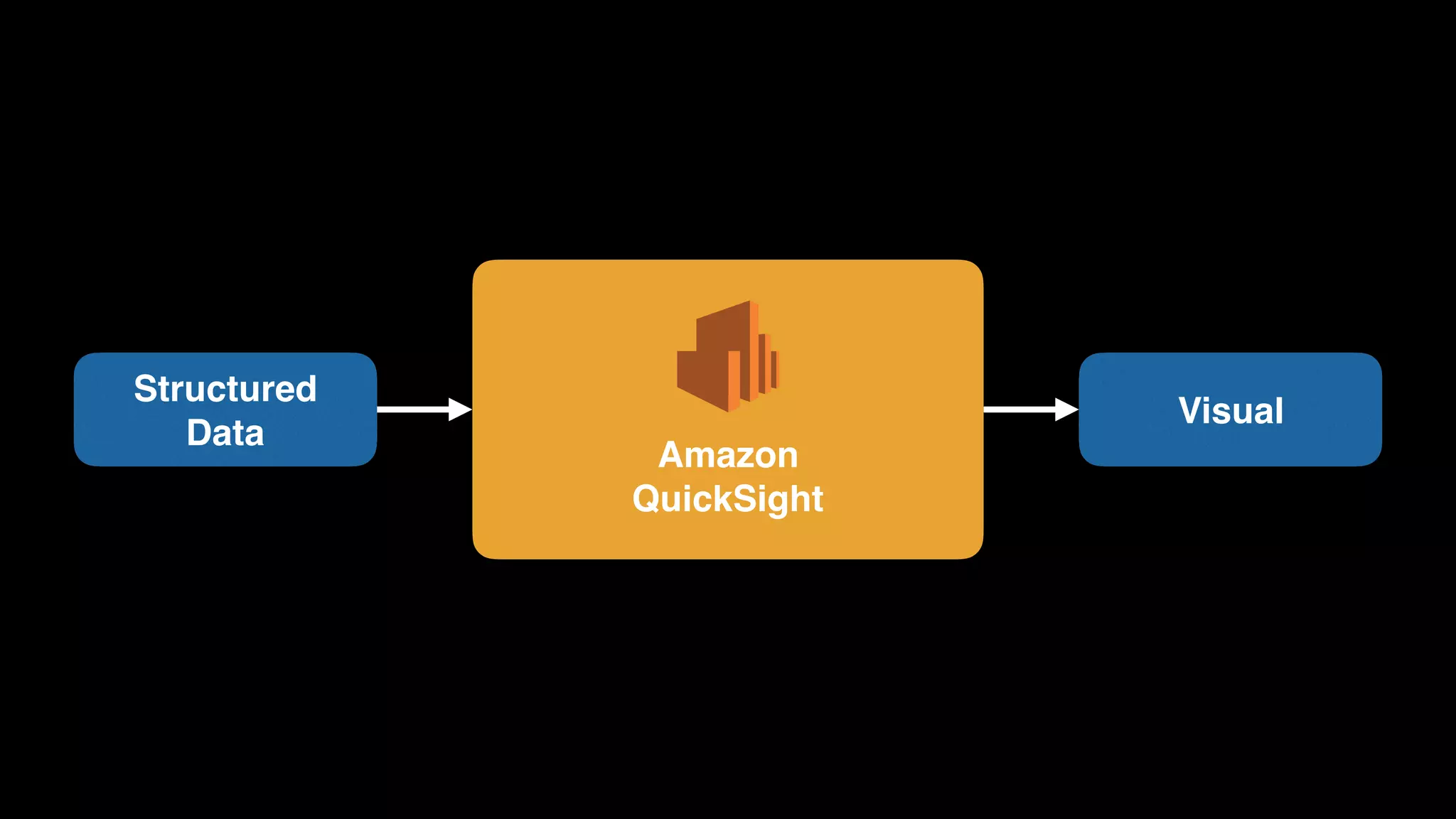

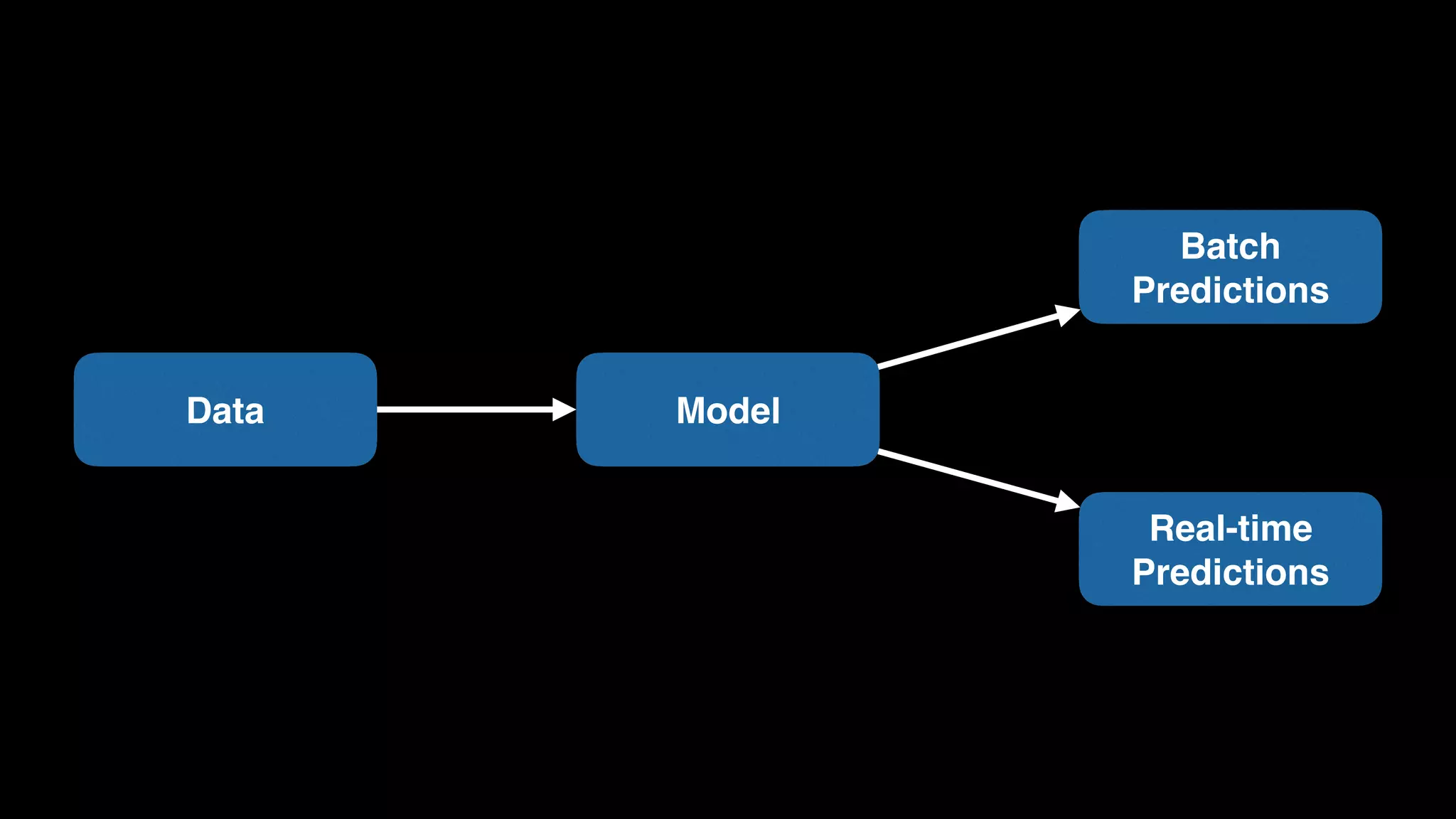

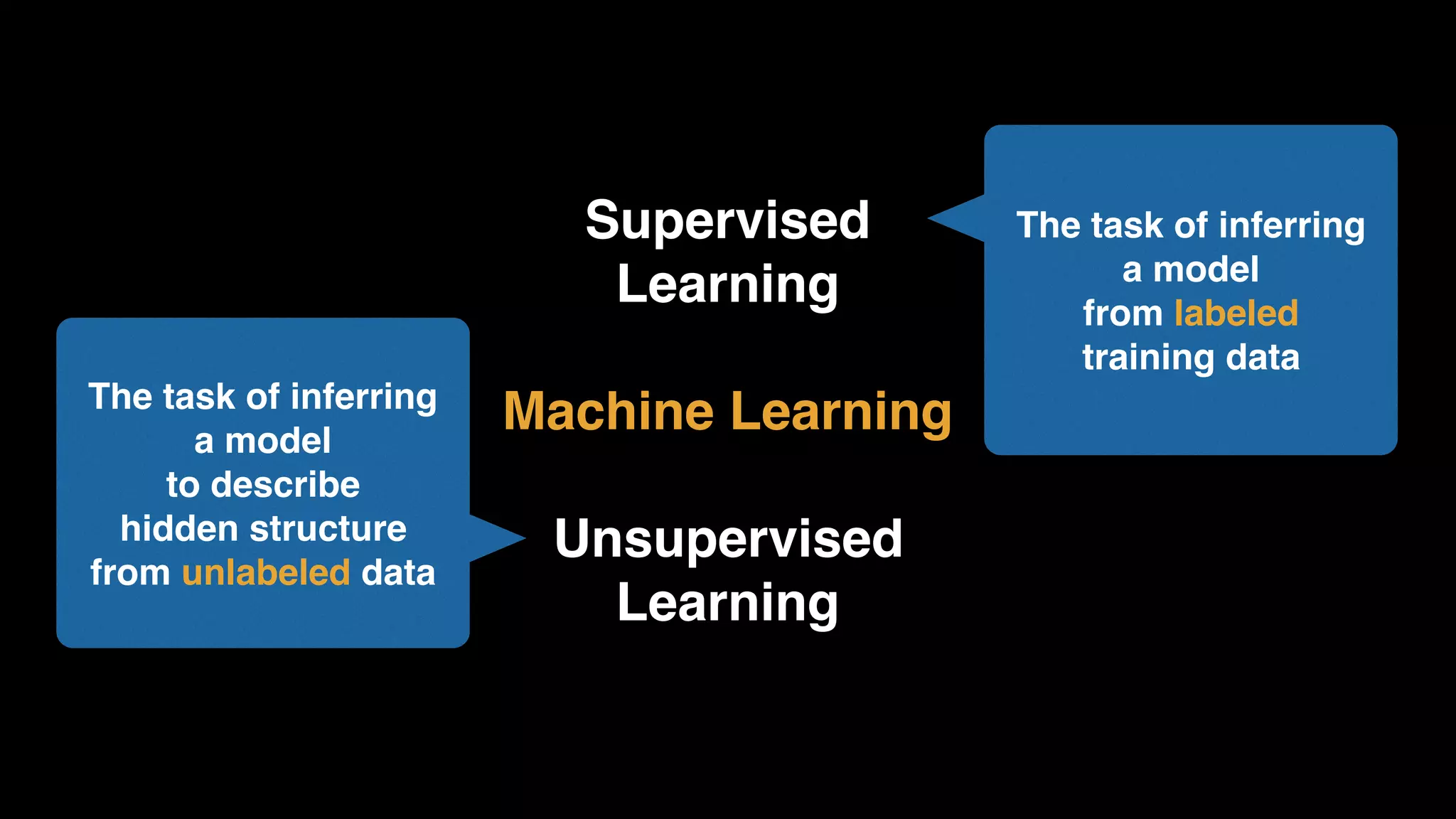
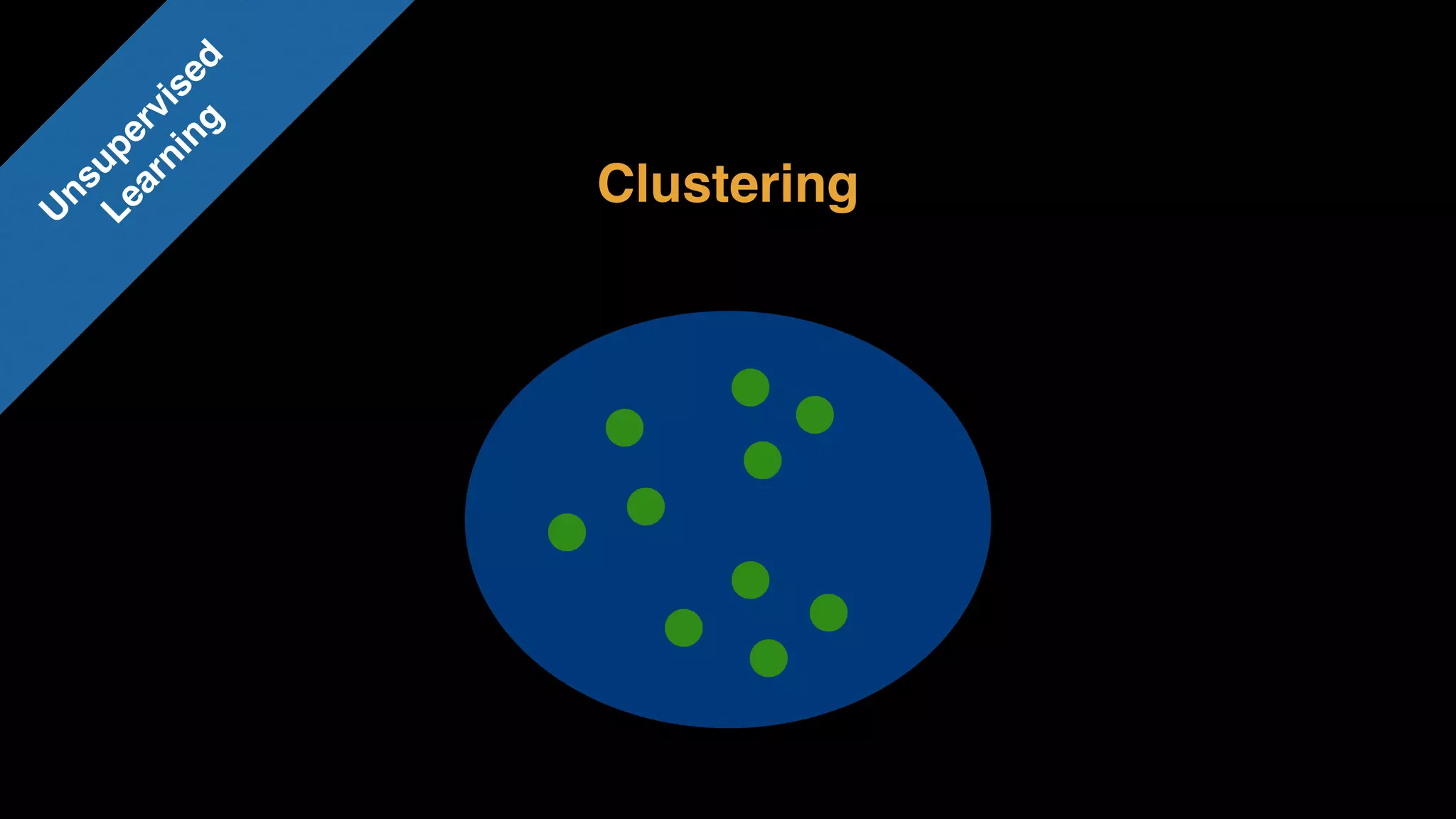
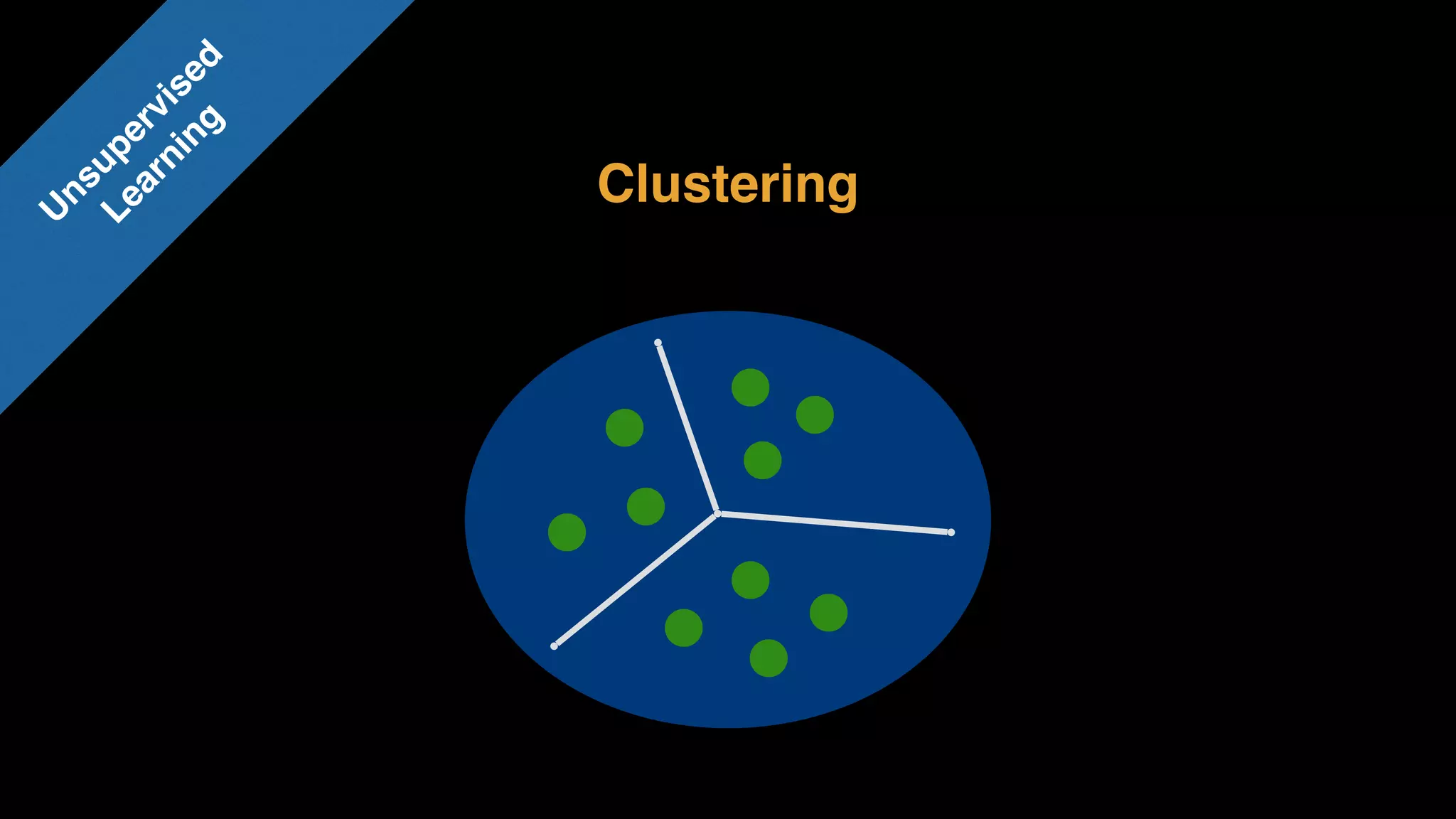
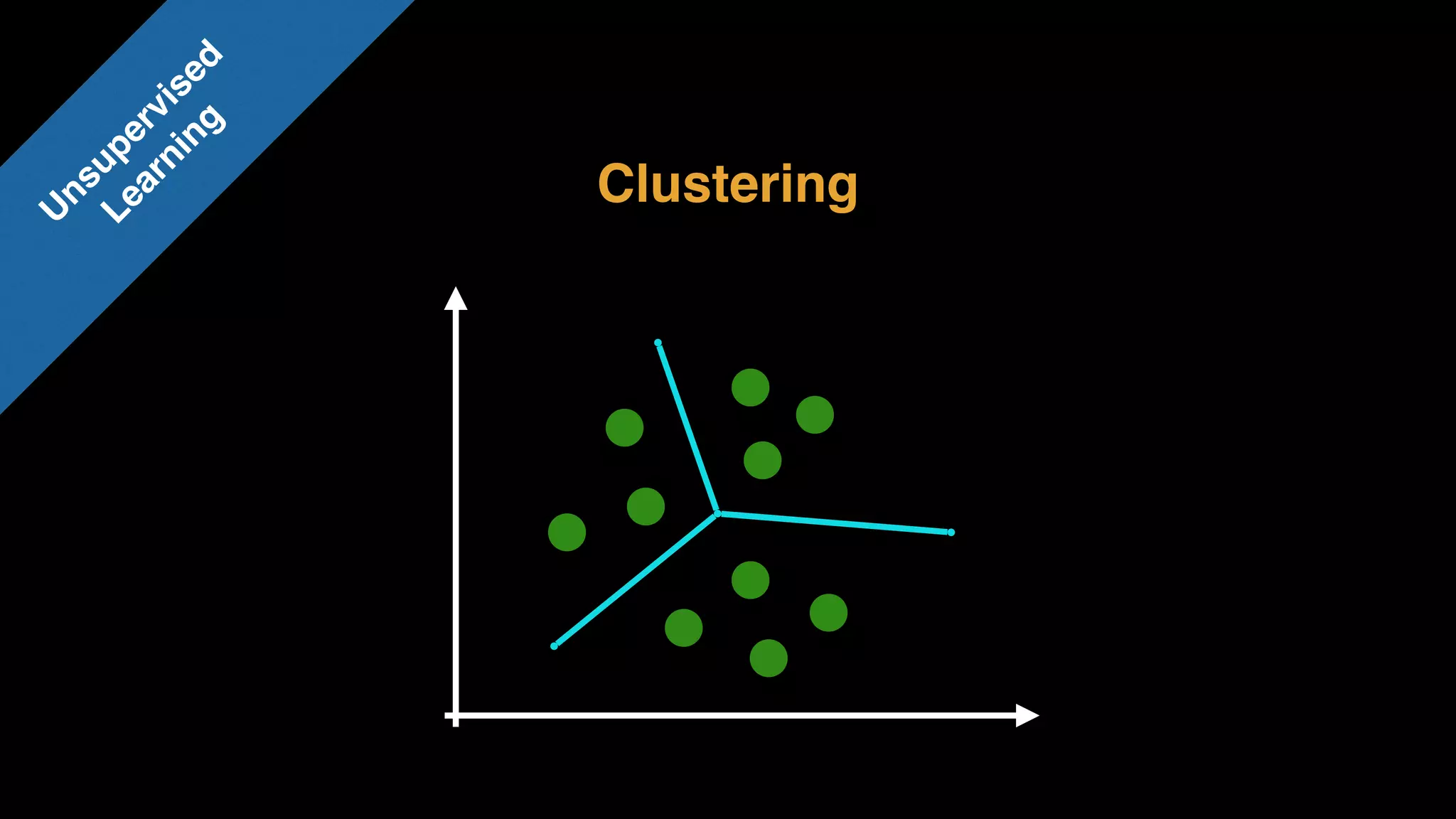


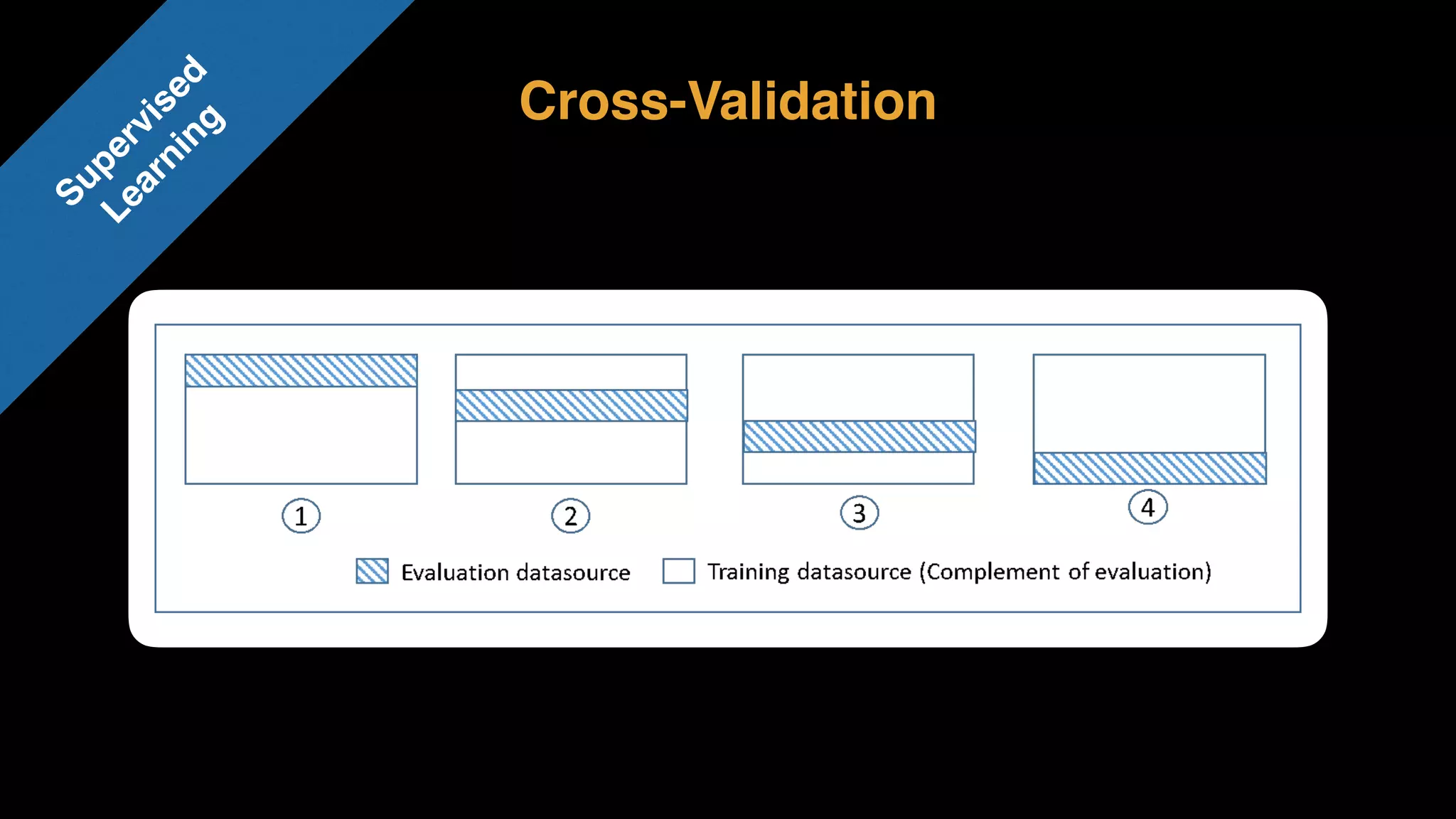
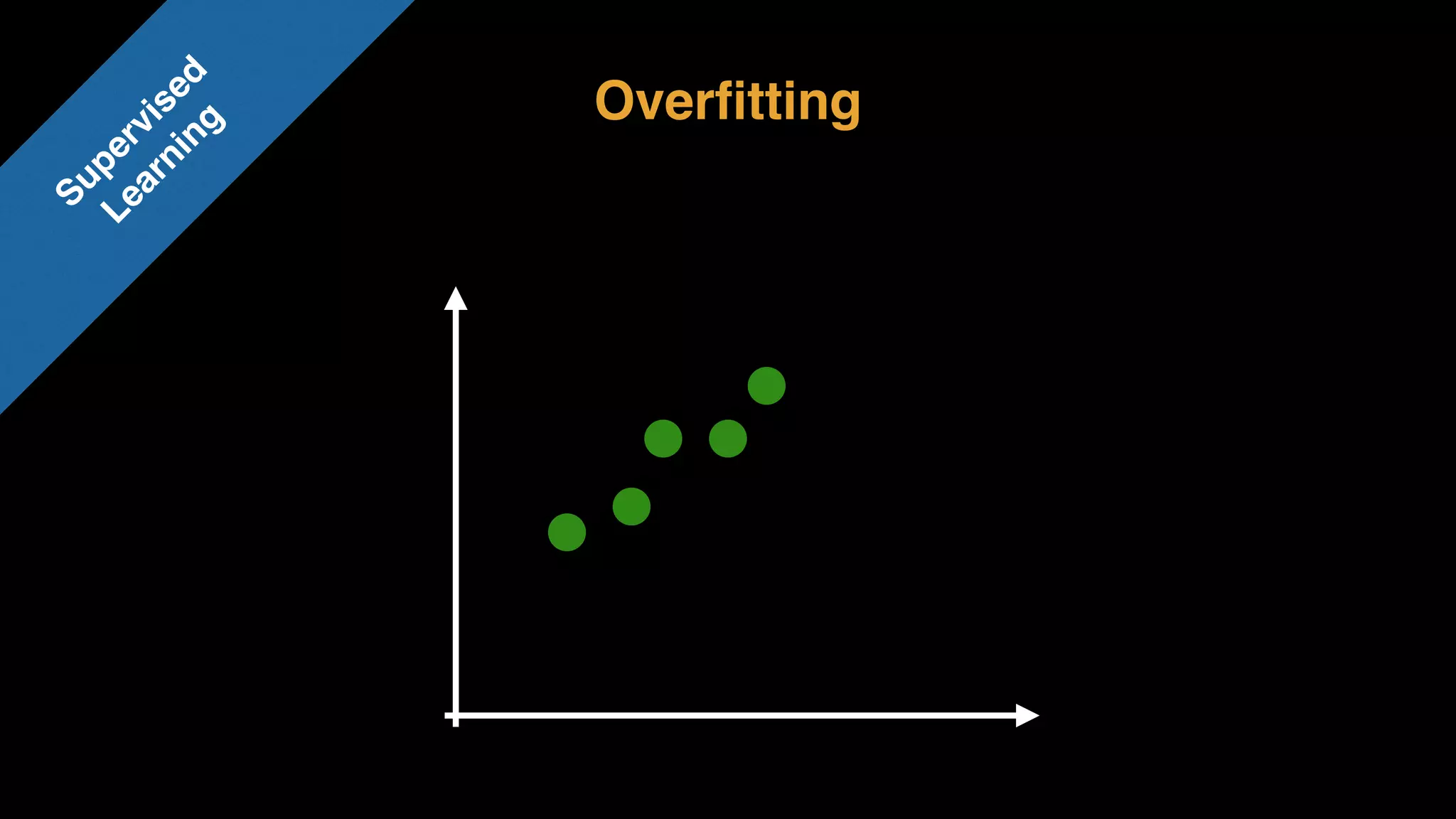
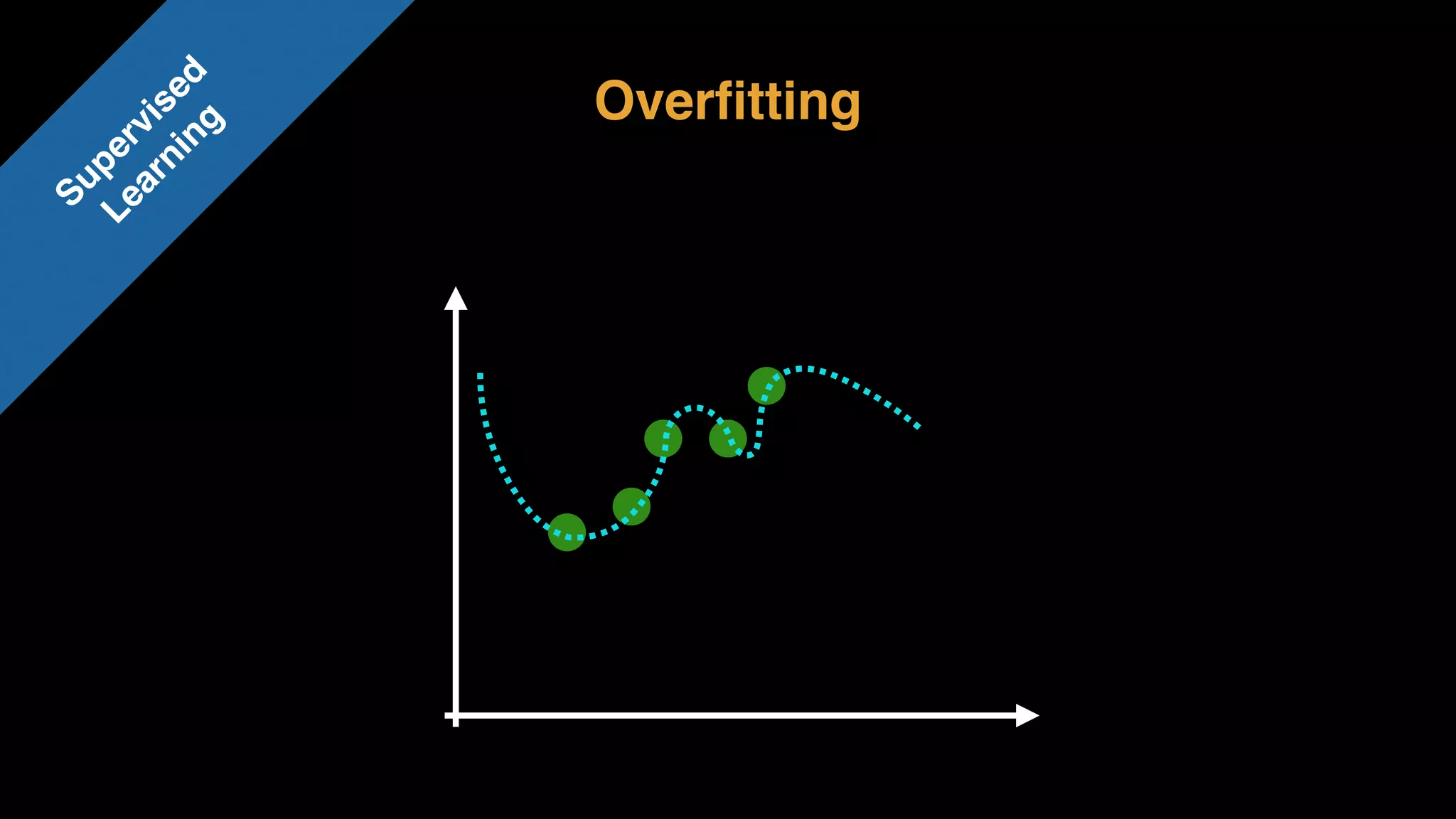
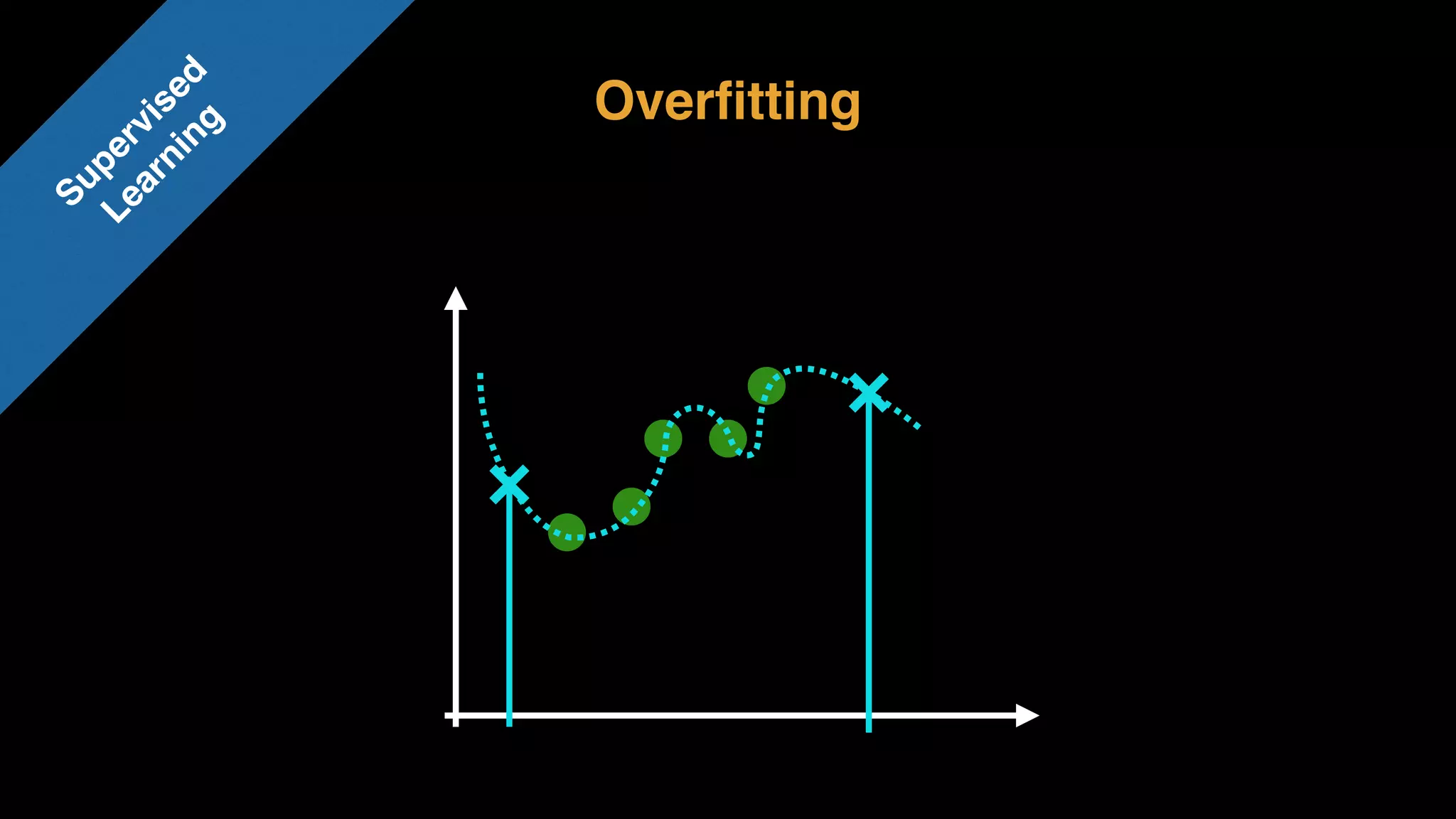
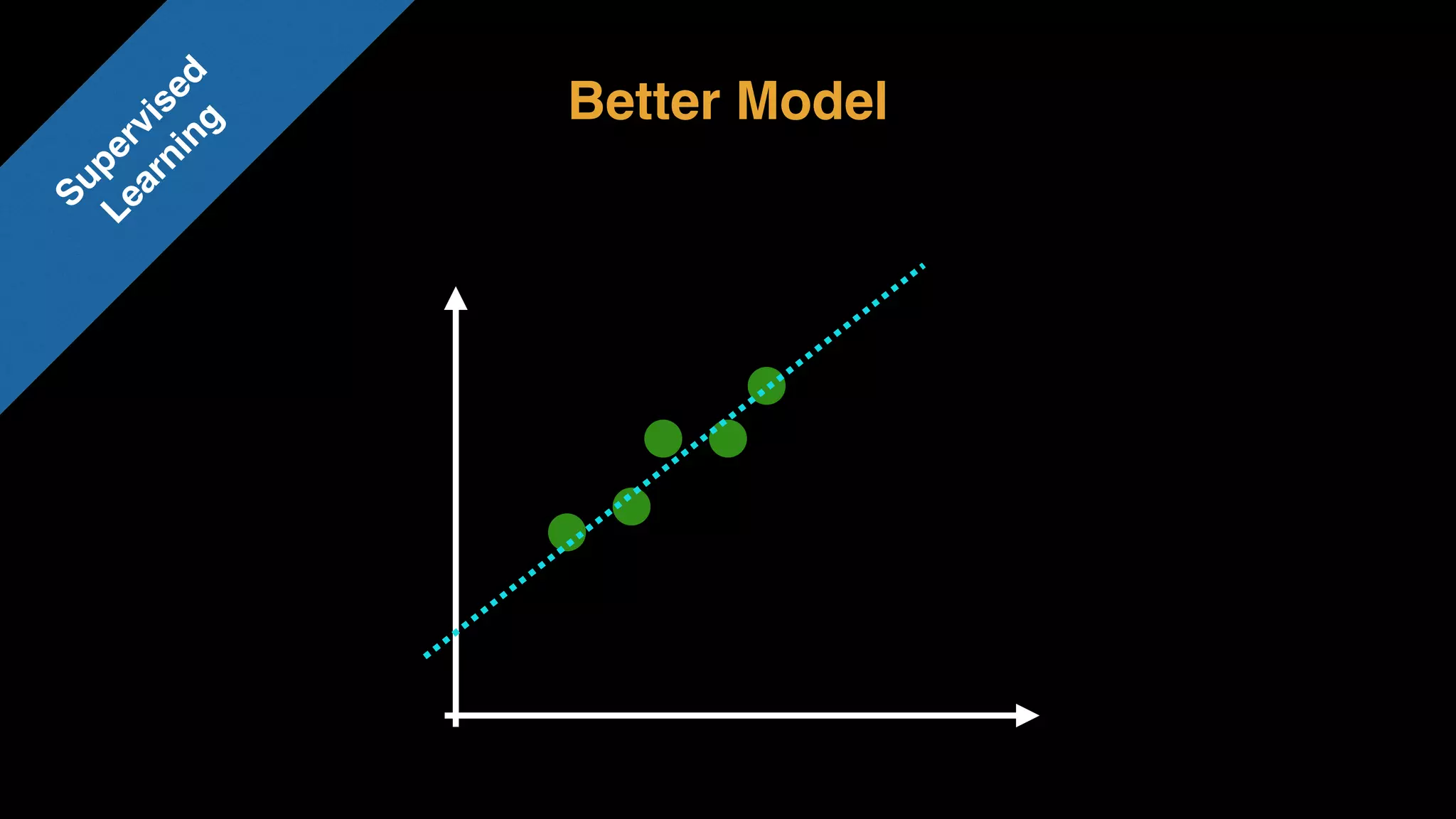
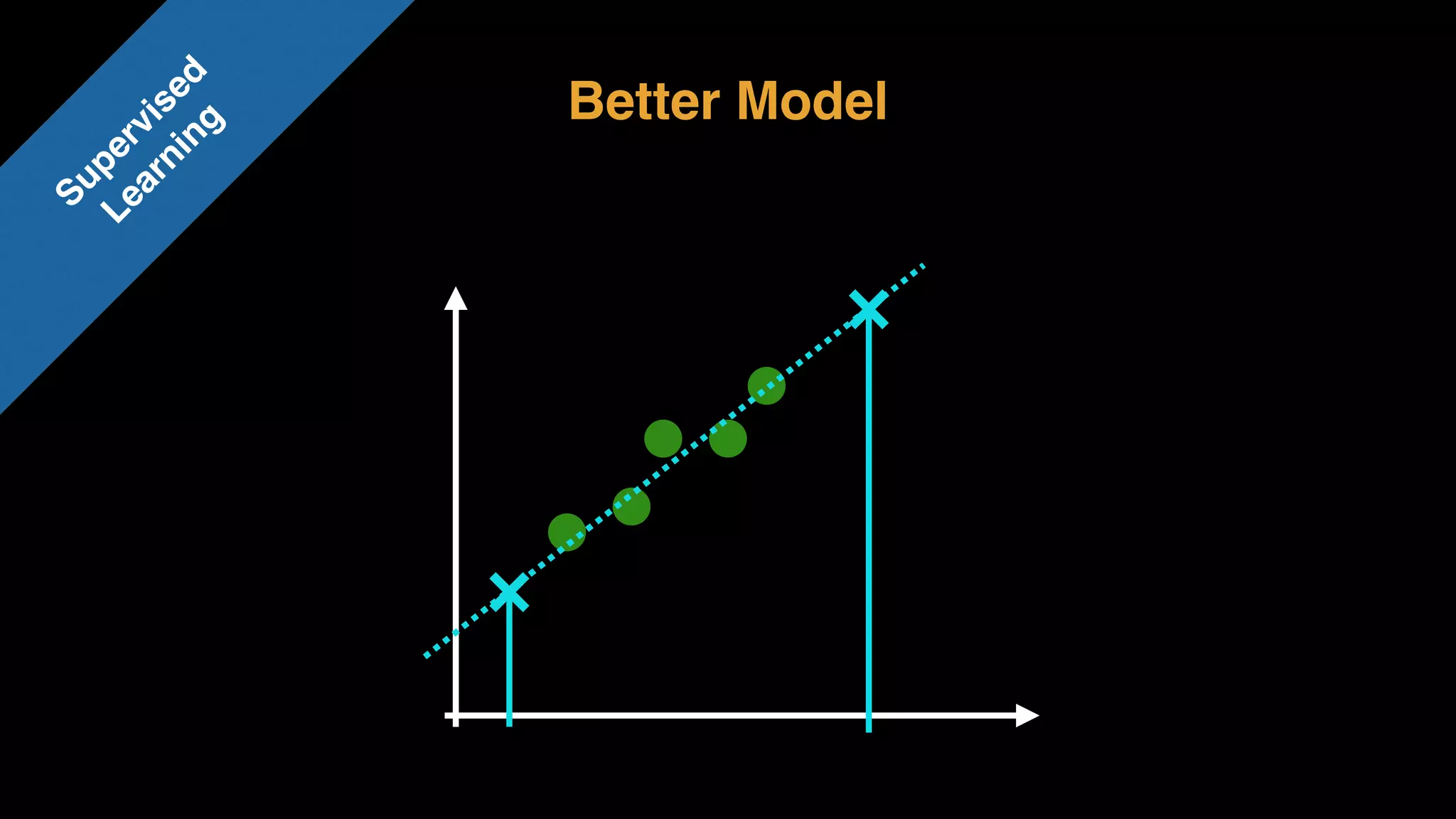

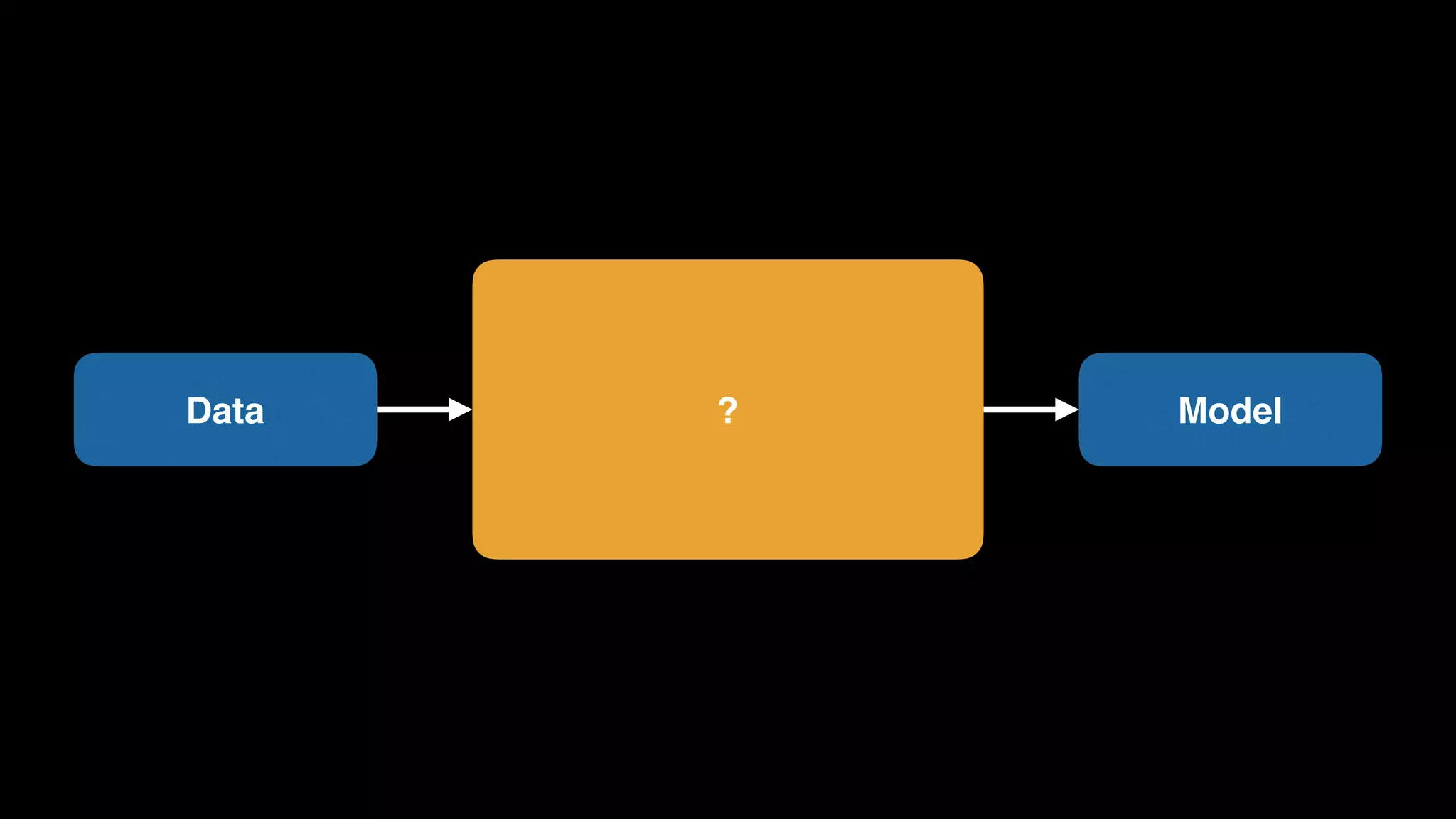
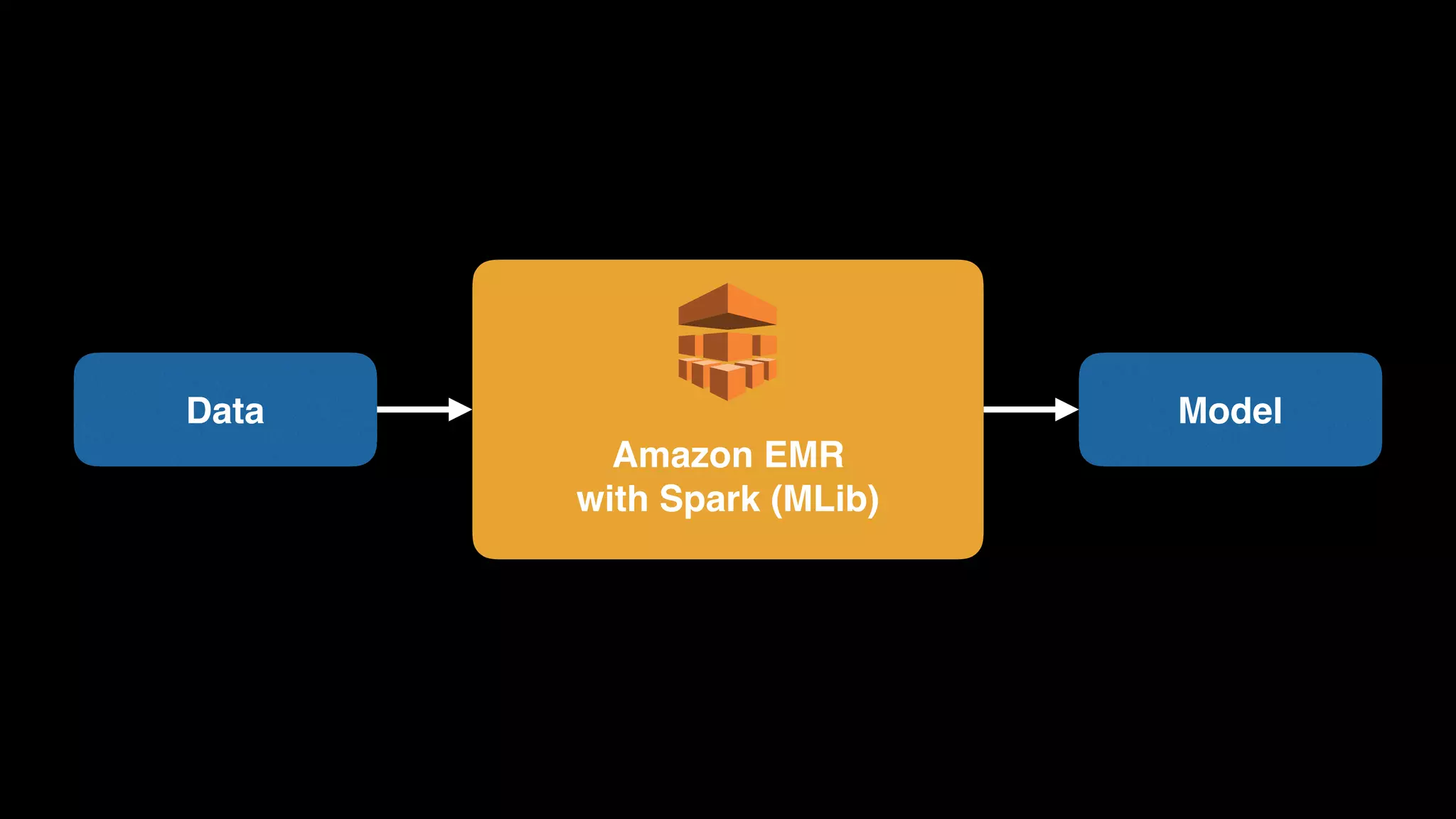
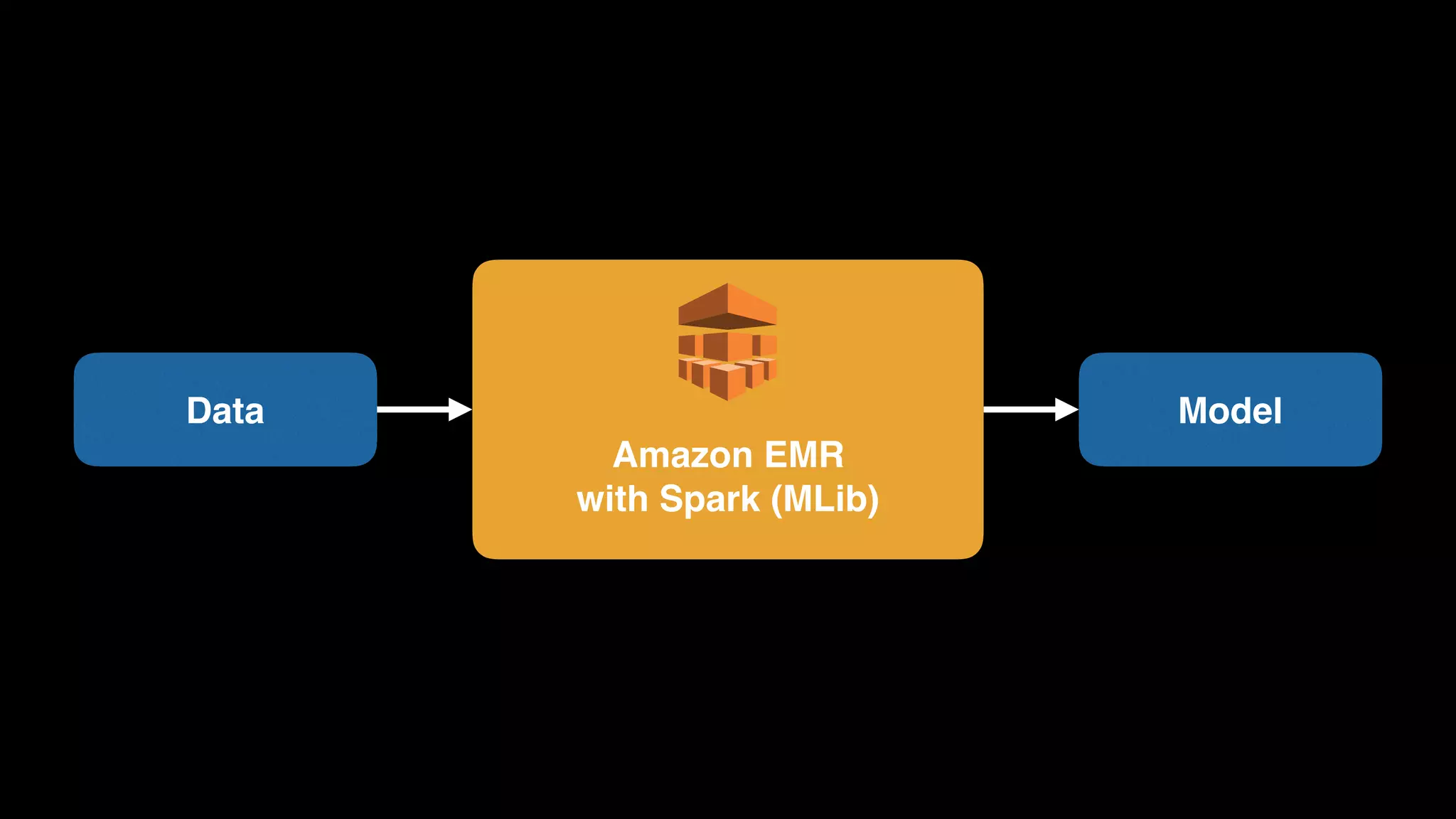

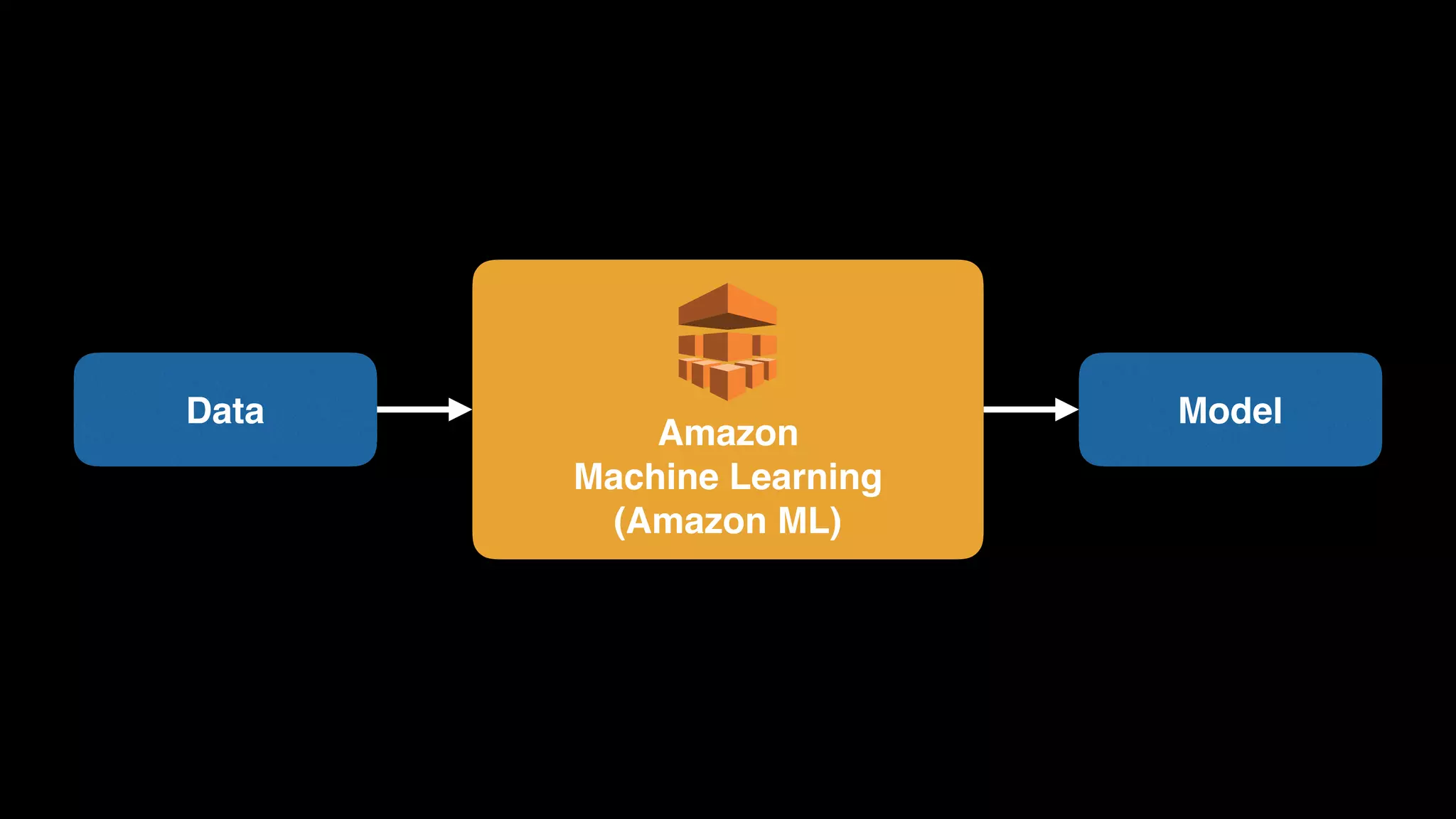
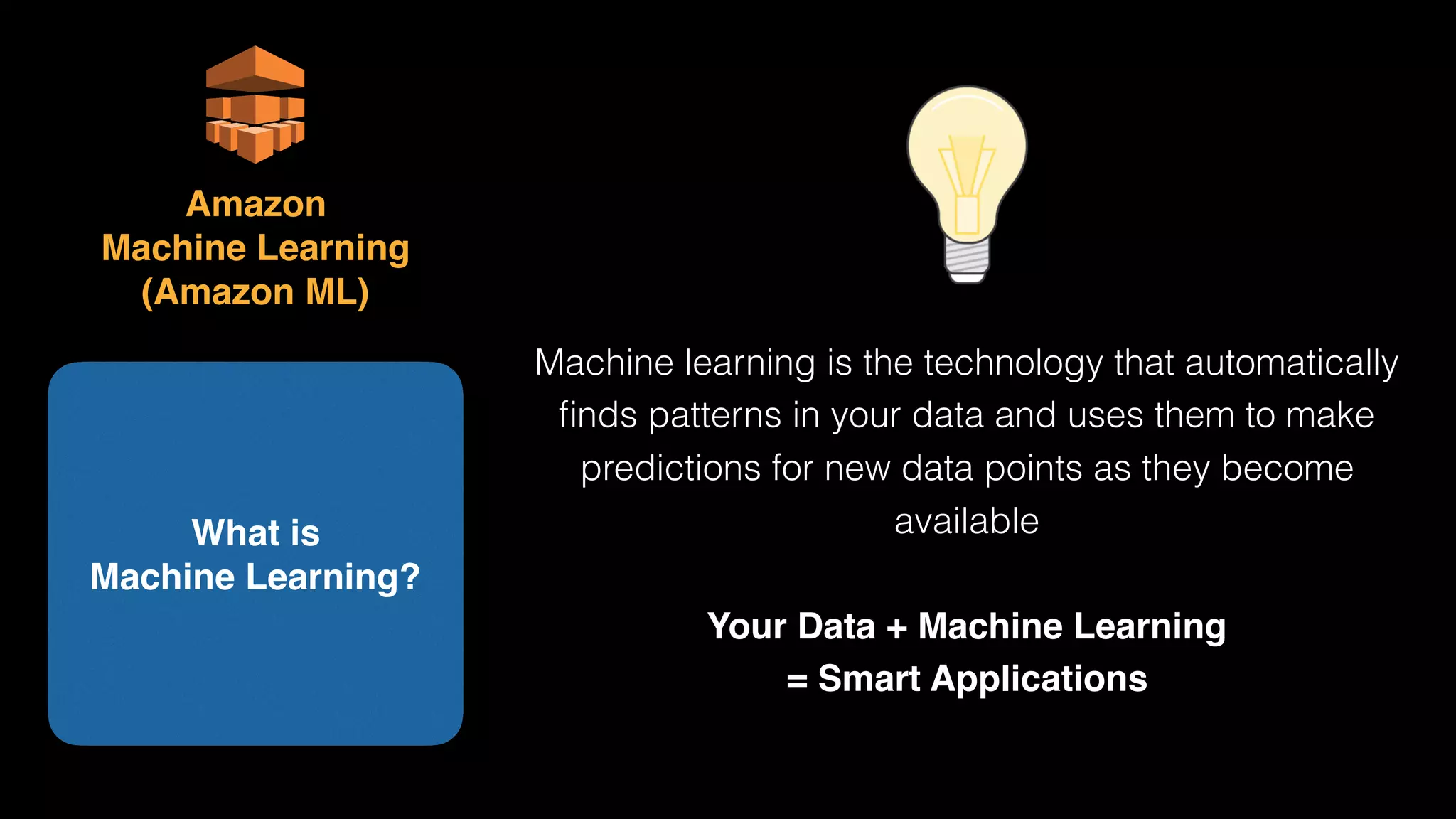
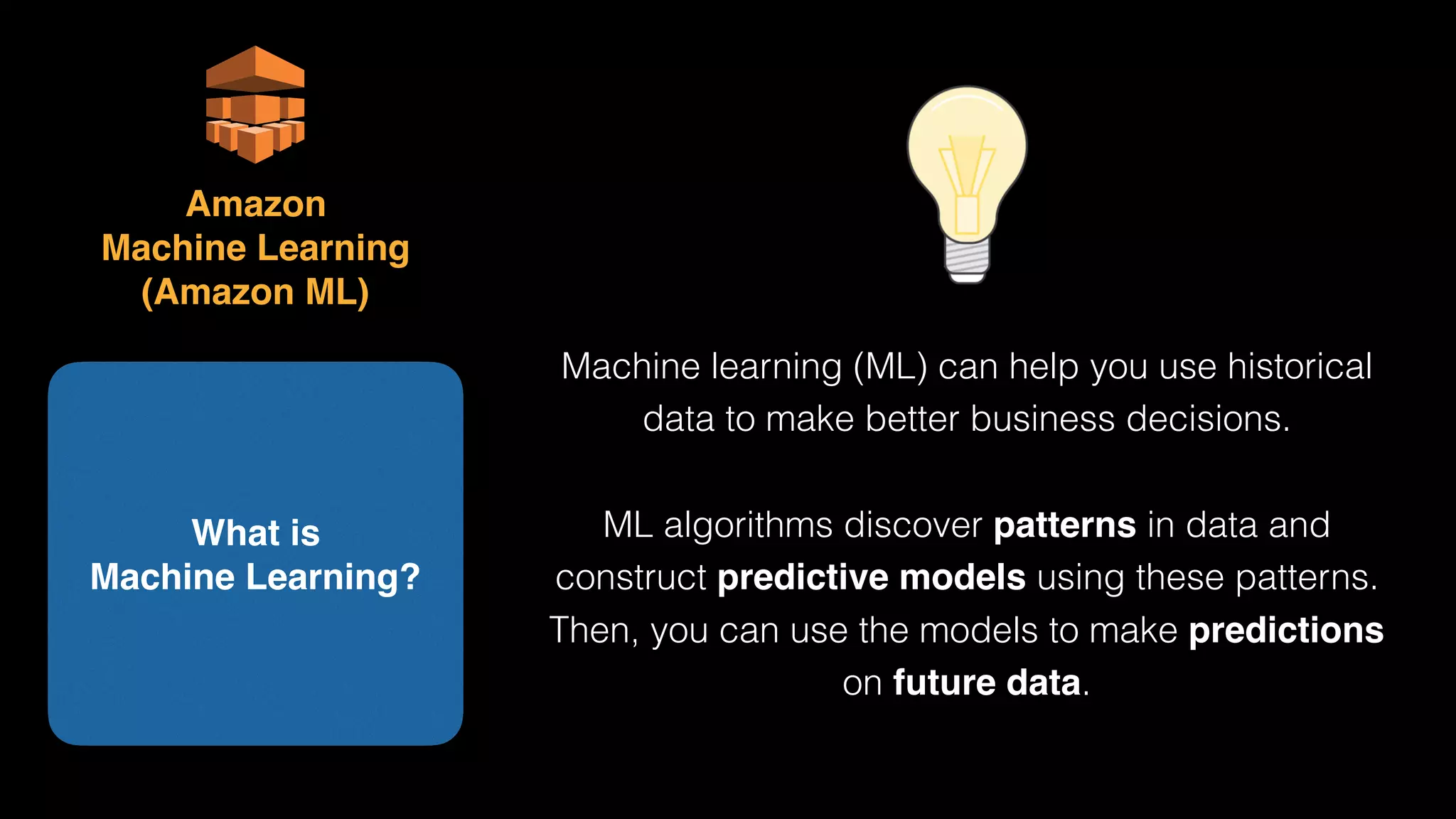

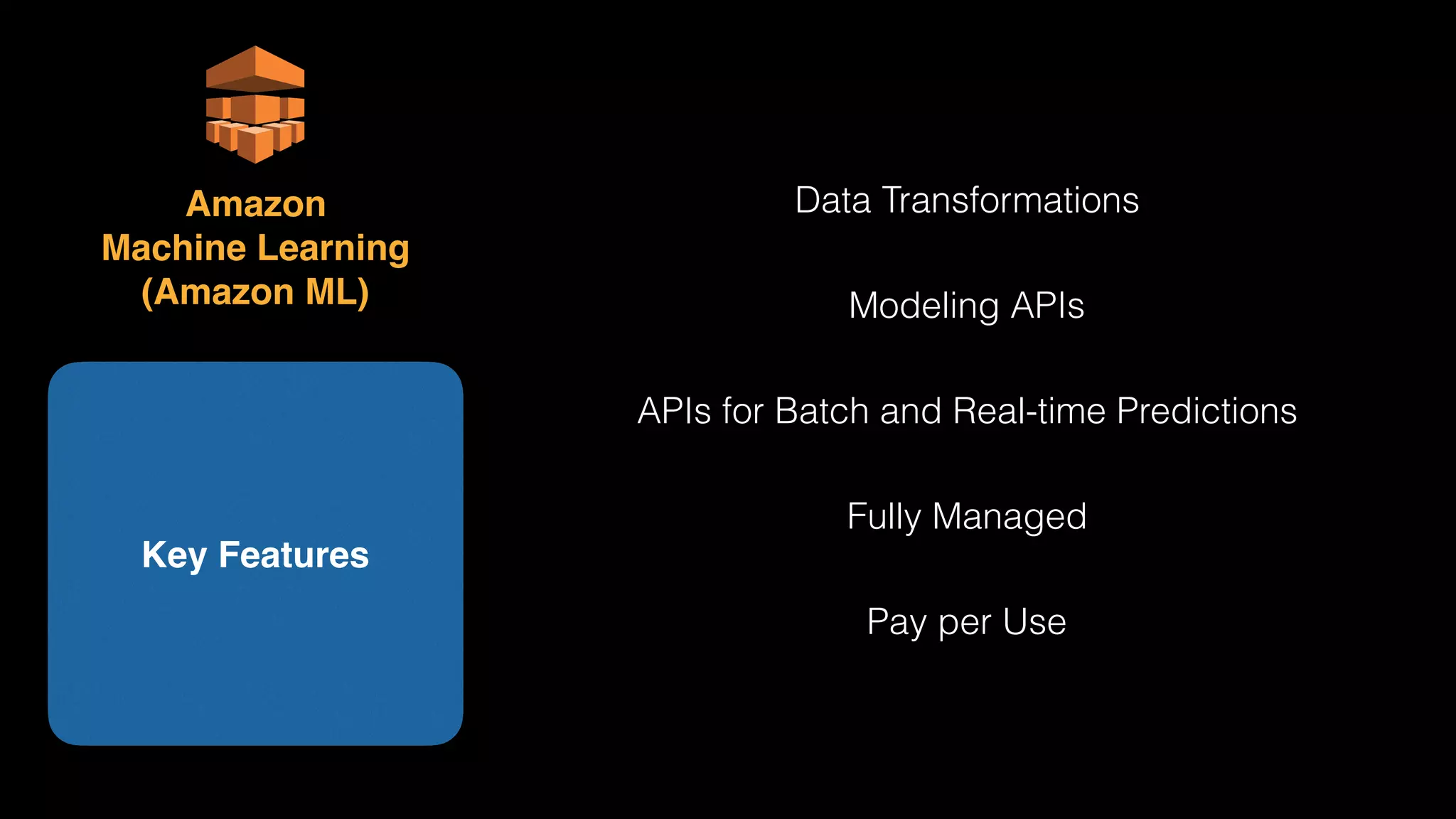
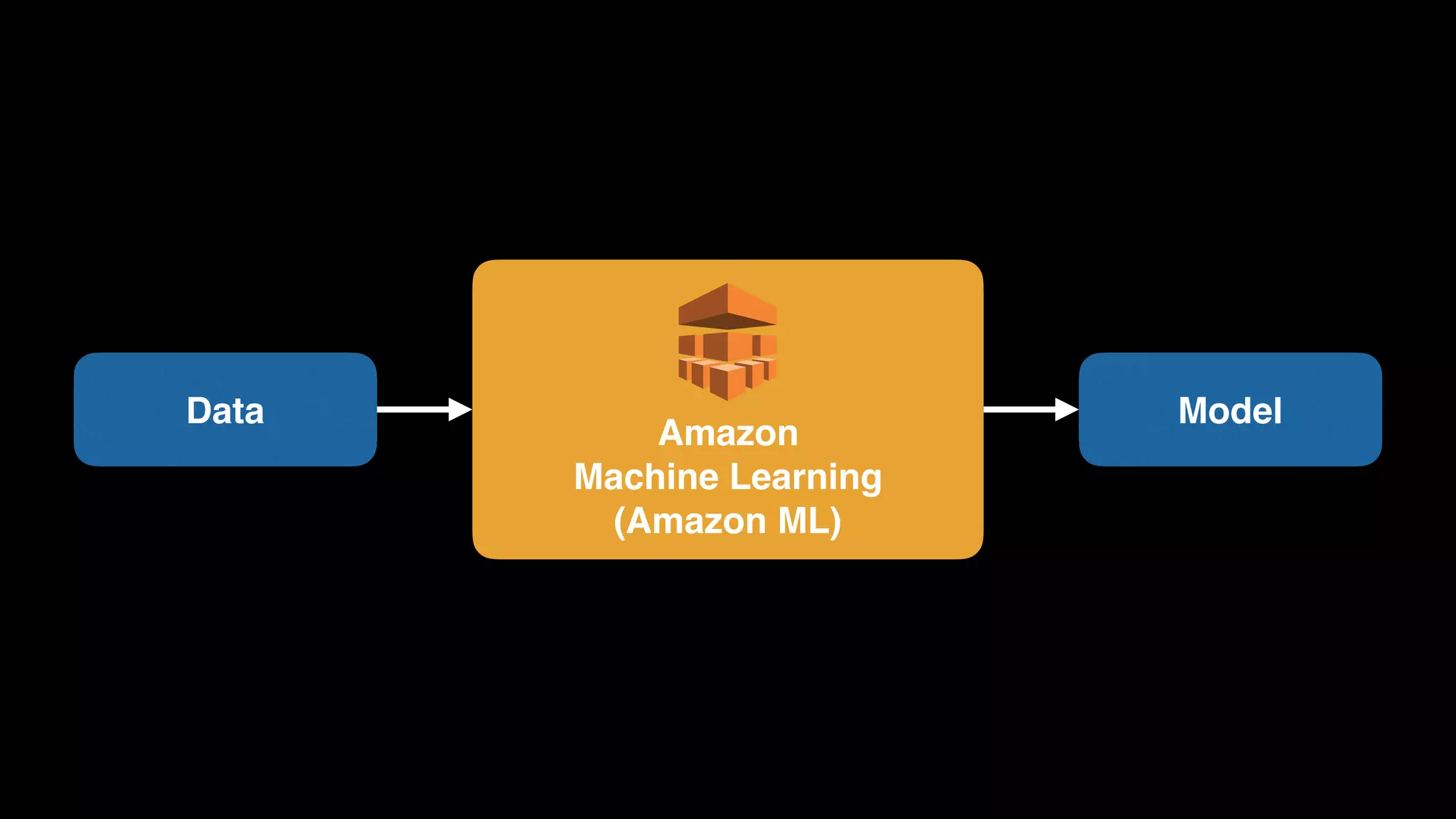
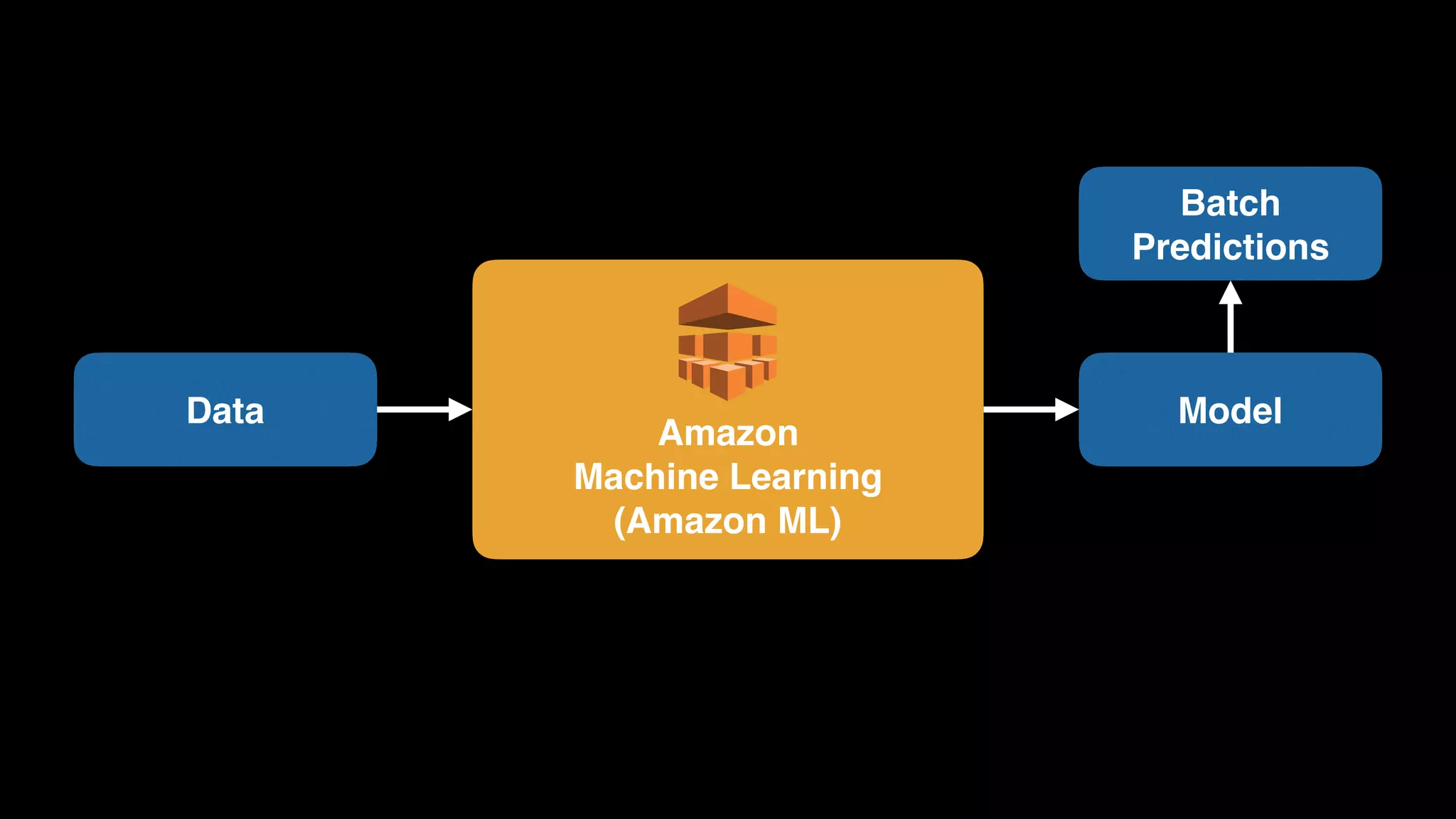
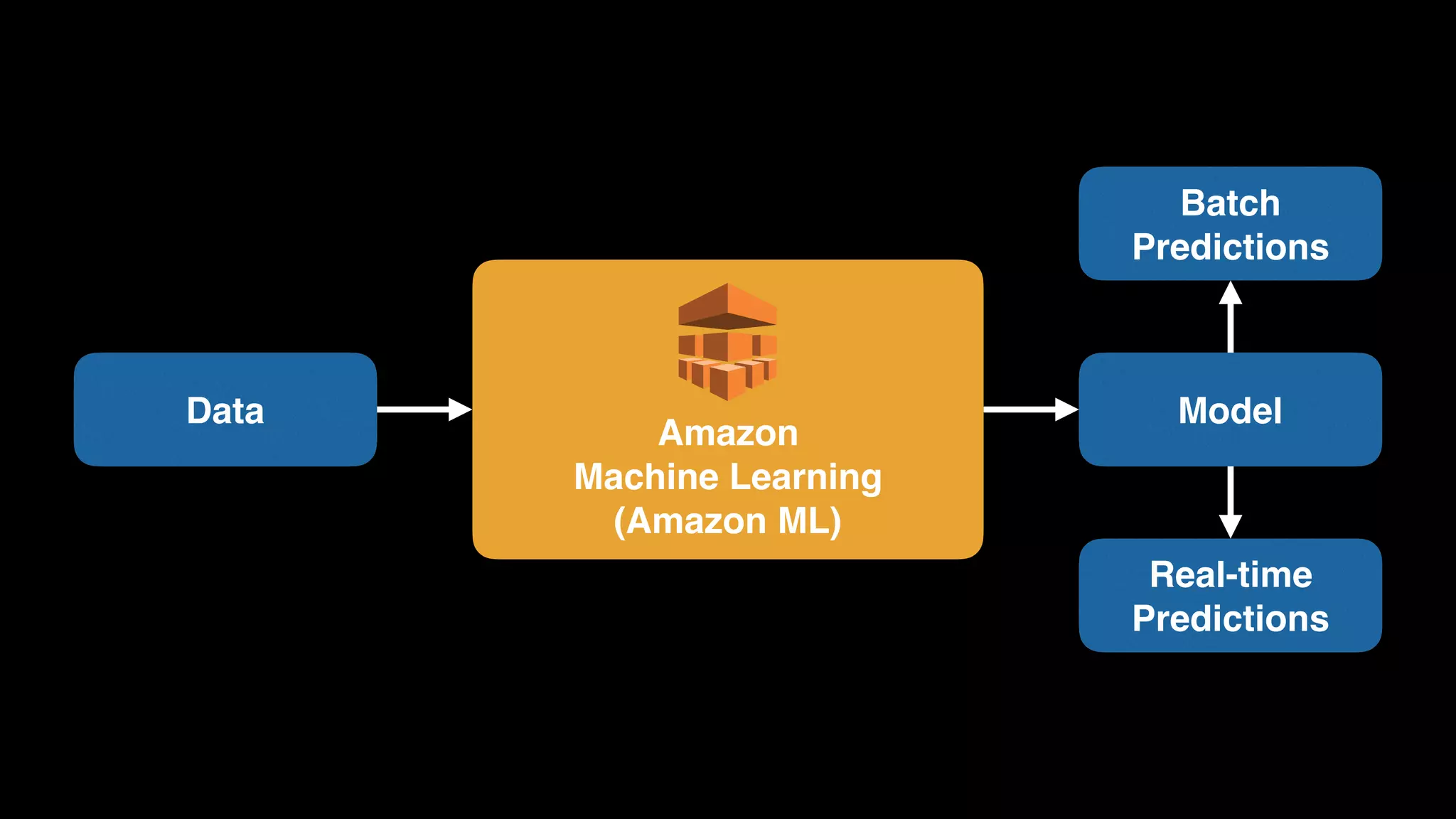
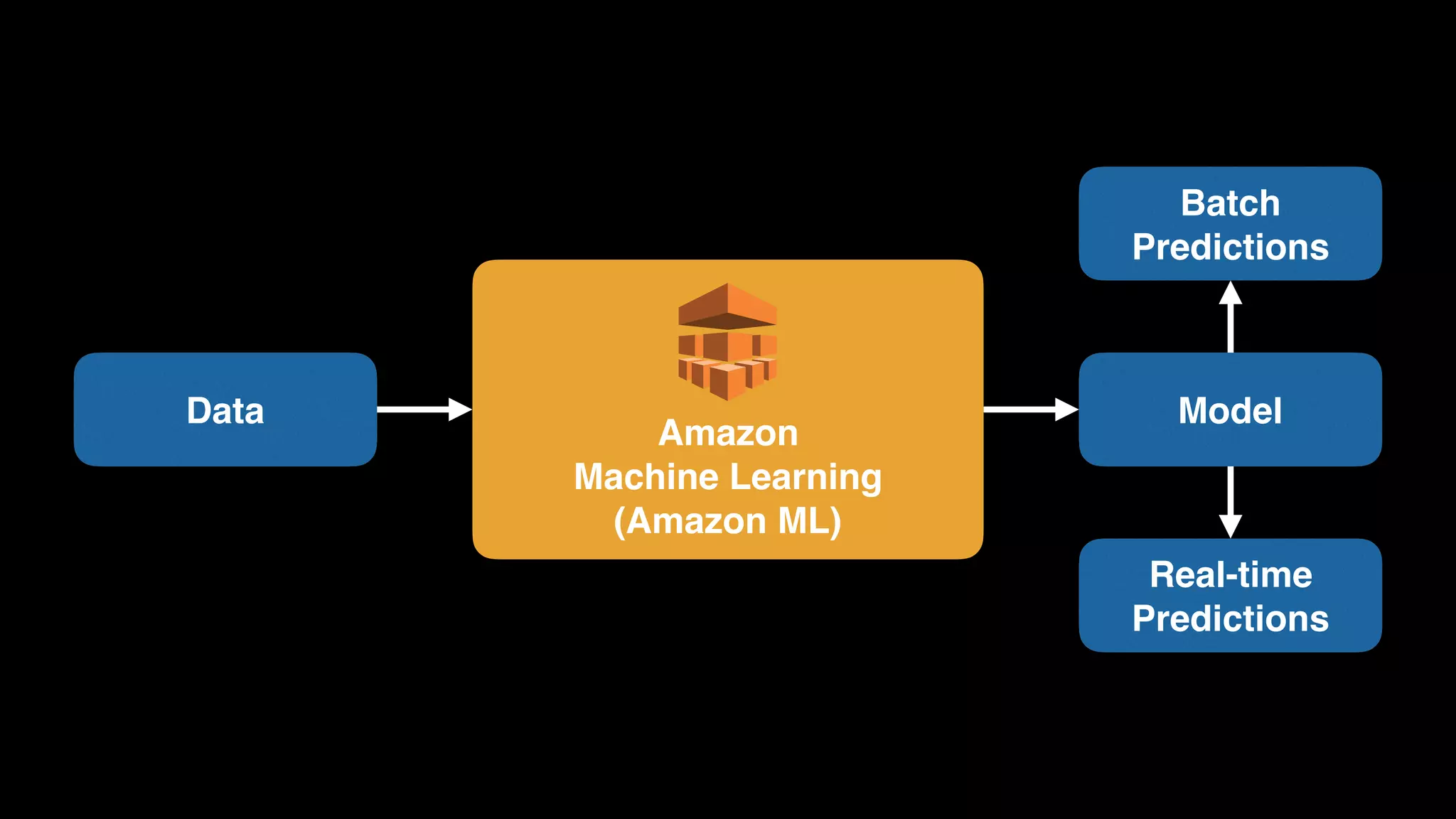
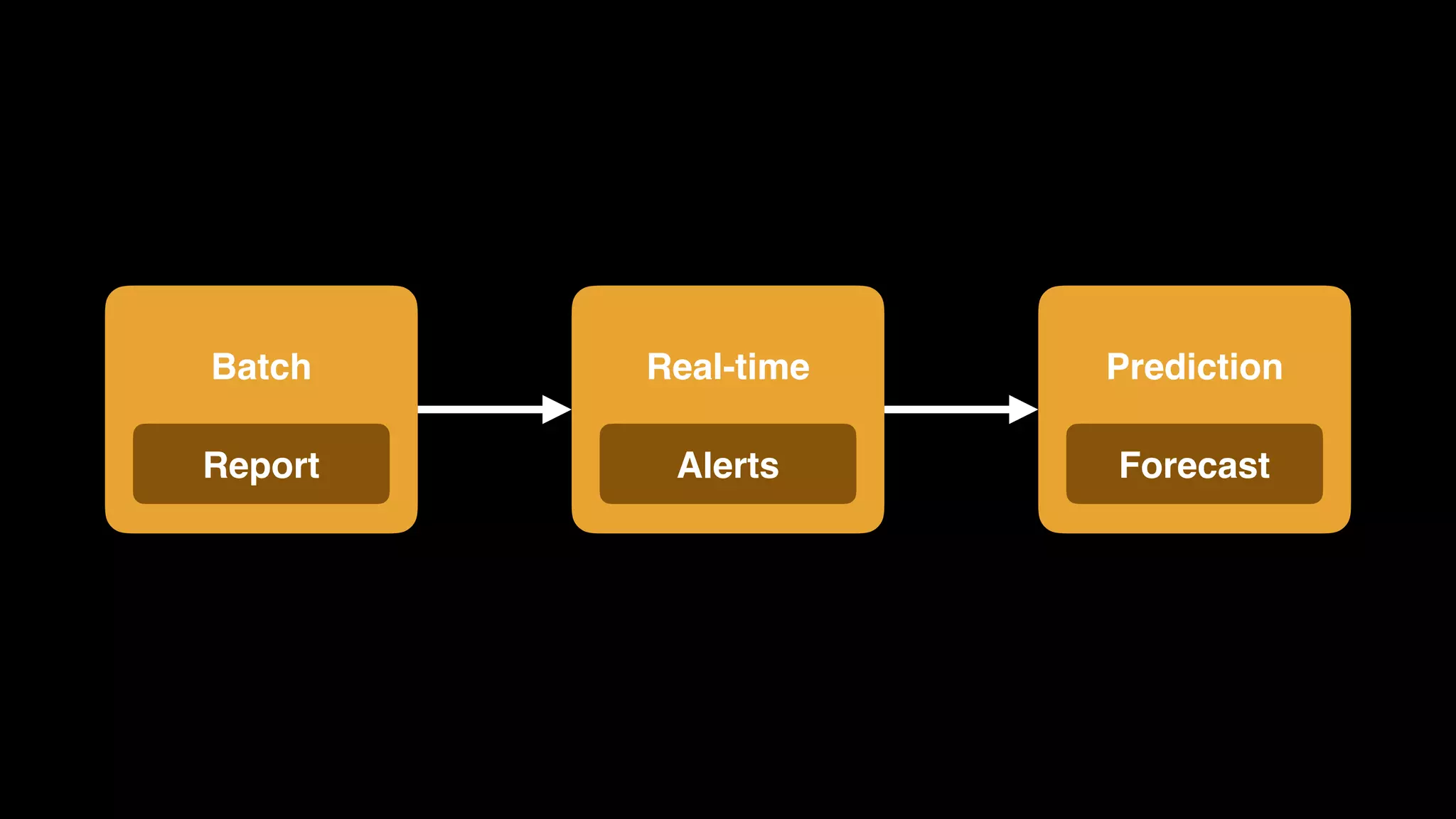


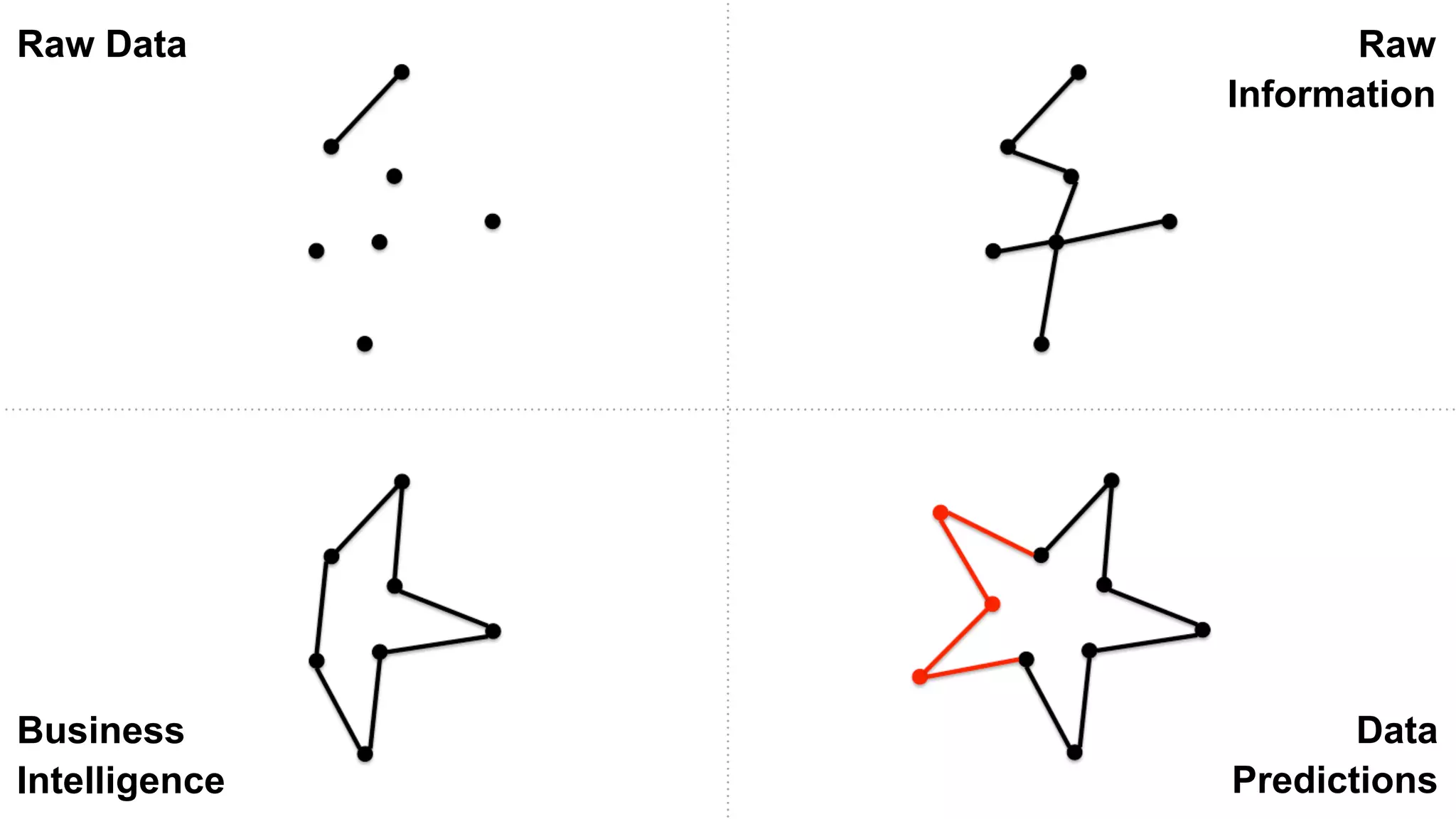


The document provides an extensive overview of AWS services like Amazon EMR, Amazon Redshift, Amazon Kinesis, and Amazon QuickSight, emphasizing their capabilities in data processing, analytics, and machine learning. It discusses the architecture, cost-saving tips, and how these services interact with structured and unstructured data. Additionally, it outlines the importance of real-time data and analytics for better business insights.


































![[よくわかるAmazon Redshift in 大阪]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140221redshiftupdatesv2osaka-140224010309-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[よくわかるAmazon Redshift]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140219redshiftupdatesv1tokyo-140224010117-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[DSC Europe 25] Marko Krstic - Understanding the AI Threat Landscape - Risks,...](https://cdn.slidesharecdn.com/ss_thumbnails/tiyim1ins5jvbrvzpzla-2-251209104645-c69d3553-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Hans Kleinsman - The Compliance Gearbox: How Tax Tech Mediate...](https://cdn.slidesharecdn.com/ss_thumbnails/dxdytie1toel0hr90bjs-2-251212103250-174fdbe7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Branko Dzakula - From Defense to Attack: How AI Redefines Cyb...](https://cdn.slidesharecdn.com/ss_thumbnails/80bdzdxpr3ky2g0qvyk9-8-251211083048-ce5fc1ee-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Milan Zdravkovic - The road less traveled in District Heating...](https://cdn.slidesharecdn.com/ss_thumbnails/nfaboniqwsz4ucyctnmy-2-milan-zdravkovic-dsc2025-the-road-less-traveled-in-district-heating-operation-251208151905-f56388a5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milan Sekuloski - Data, Defence, and Development: Cybersecuri...](https://cdn.slidesharecdn.com/ss_thumbnails/dfrkwwx4qly6atqpbl4z-4-251209104645-c3d4b0ca-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Aleksandra Dragicevic - AI-Boosted Research in Healthcare: Fr...](https://cdn.slidesharecdn.com/ss_thumbnails/iqwngszurf2r7pi1lnnj-4-aleksandra-dragicevic-ad-dsc-europe-conference-20-251208151905-37c3238a-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Sara Polak - The Ancient Operating System: What Archaeology T...](https://cdn.slidesharecdn.com/ss_thumbnails/3vch2p6tttdnwhsgazoz-3-sara-polak-smart-cities-251208152532-64404202-thumbnail.jpg?width=640&height=640&fit=bounds)
