Downloaded 59 times





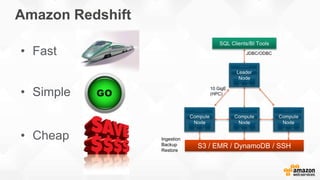
















![Compound Sort Keys Illustrated
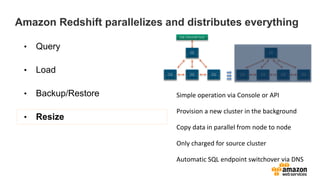
• Records in Redshift
are stored in blocks.
• For this illustration,
let’s assume that
four records fill a
block
• Records with a given
cust_id are all in one
block
• However, records
with a given prod_id
are spread across
four blocks
1
1
1
1
2
3
4
1
4
4
4
2
3
4
4
1
3
3
3
2
3
4
3
1
2
2
2
2
3
4
2
1
1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
cust_id prod_id other columns blocks](https://image.slidesharecdn.com/awssummitgruredshiftoverview-150608174326-lva1-app6892/85/Redshift-overview-27-320.jpg)
![1 [1,1] [1,2] [1,3] [1,4]
2 [2,1] [2,2] [2,3] [2,4]
3 [3,1] [3,2] [3,3] [3,4]
4 [4,1] [4,2] [4,3] [4,4]
1 2 3 4
prod_id
cust_id
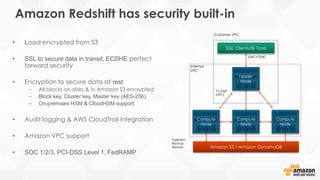
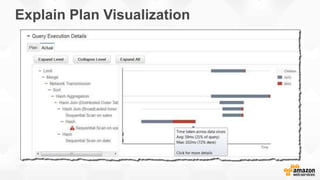
Interleaved Sort Keys Illustrated
• Records with a given
cust_id are spread
across two blocks
• Records with a given
prod_id are also
spread across two
blocks
• Data is sorted in equal
measures for both
keys
1
1
2
2
2
1
2
3
3
4
4
4
3
4
3
1
3
4
4
2
1
2
3
3
1
2
2
4
3
4
1
1
cust_id prod_id other columns blocks](https://image.slidesharecdn.com/awssummitgruredshiftoverview-150608174326-lva1-app6892/85/Redshift-overview-28-320.jpg)
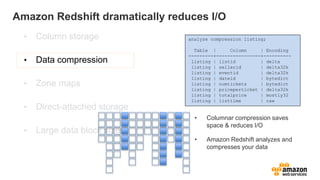
![How to use the feature
• New keyword ‘INTERLEAVED’ when defining sort keys
– Existing syntax will still work and behavior is unchanged
– You can choose up to 8 columns to include and can query with any or all of
them
• No change needed to queries
• Benefits are significant
[[ COMPOUND | INTERLEAVED ] SORTKEY ( column_name [, ...] ) ]](https://image.slidesharecdn.com/awssummitgruredshiftoverview-150608174326-lva1-app6892/85/Redshift-overview-29-320.jpg)




Amazon Redshift provides a fast, simple, and cost-effective solution for petabyte-scale data warehousing, with key features including easy provisioning, built-in security, and automatic backups. The platform reduces I/O through smart data storage techniques, supports parallel processing for queries and data loads, and offers custom user-defined functions for flexibility. Additionally, Redshift enhances data management with improved sort keys and dense storage instances for better performance at scale.

































![[よくわかるAmazon Redshift]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140219redshiftupdatesv1tokyo-140224010117-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[よくわかるAmazon Redshift in 大阪]Amazon Redshift最新情報と導入事例のご紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20140221redshiftupdatesv2osaka-140224010309-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



















































