Download as PDF, PPTX


![6
np.array([1, 2, 3]) #rank1 array
b.Shape #rows,col
a[:2, 1:3] # first 2 rows, col1,2
x.Dtype #datatype- int64, float64
np.reshape(v, (3, 1)) * w
PROJECT
pd.read_csv('data.csv')
pandas.DataFrame(mydataset)
df.head(10)
df.tail()
df.dropna()
df.corr()
df.plot()](https://image.slidesharecdn.com/mlmodule1slideshare-220810033519-c8fd624a/75/ML-MODULE-1_slideshare-pdf-6-2048.jpg)






















![S U M M A R Y ( S U M M AT I V E A S S E S S M E N T )
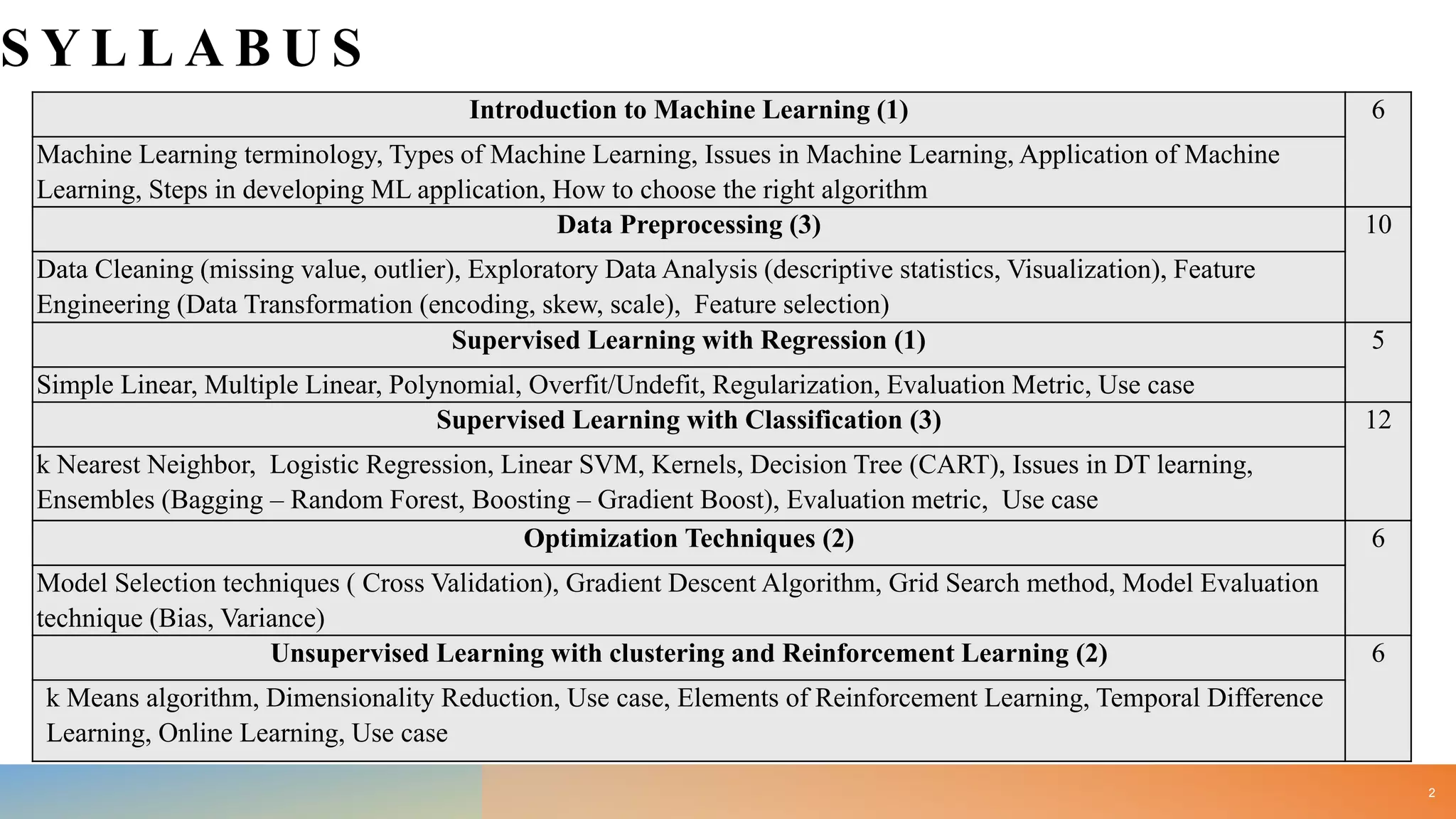
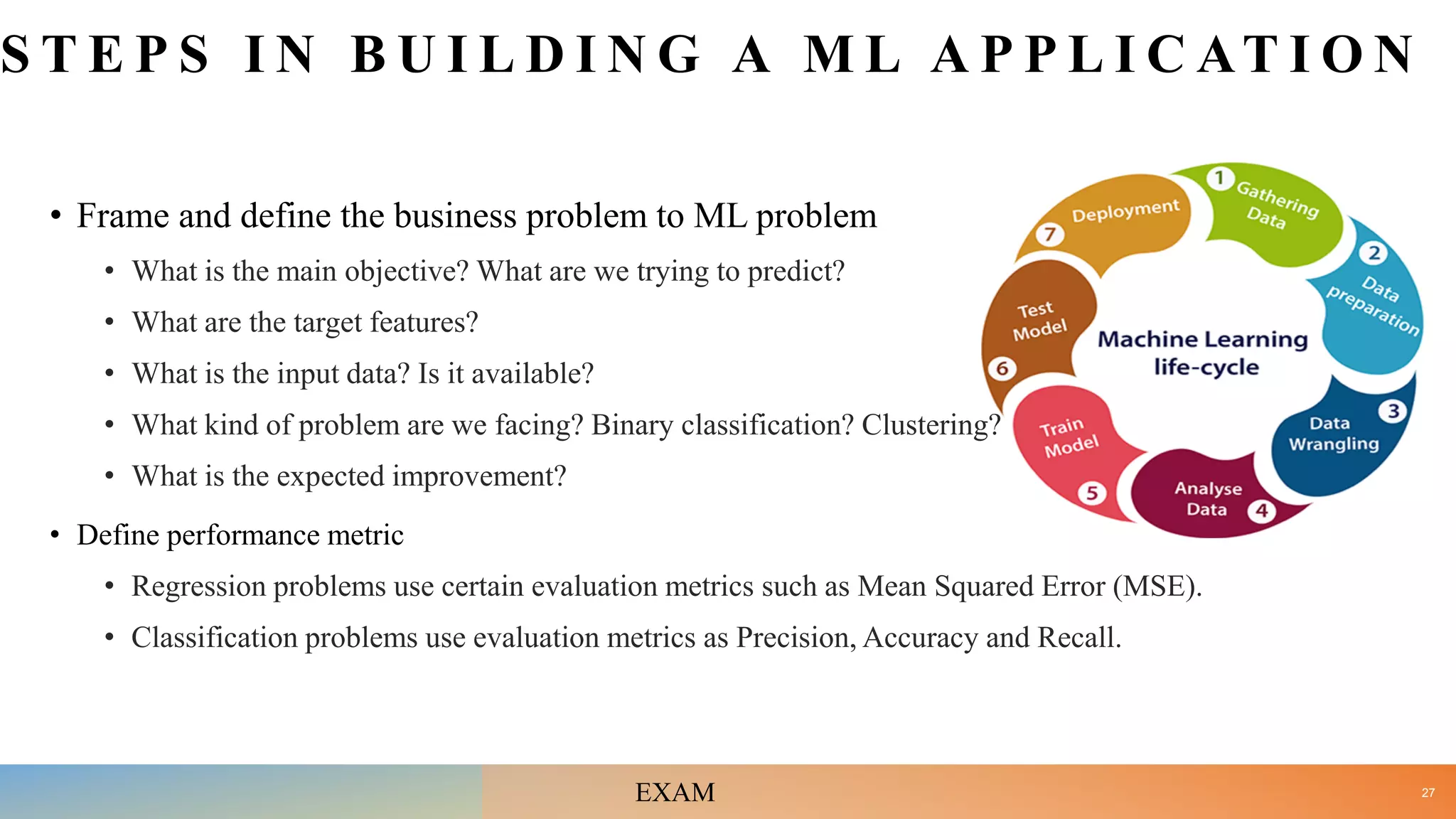
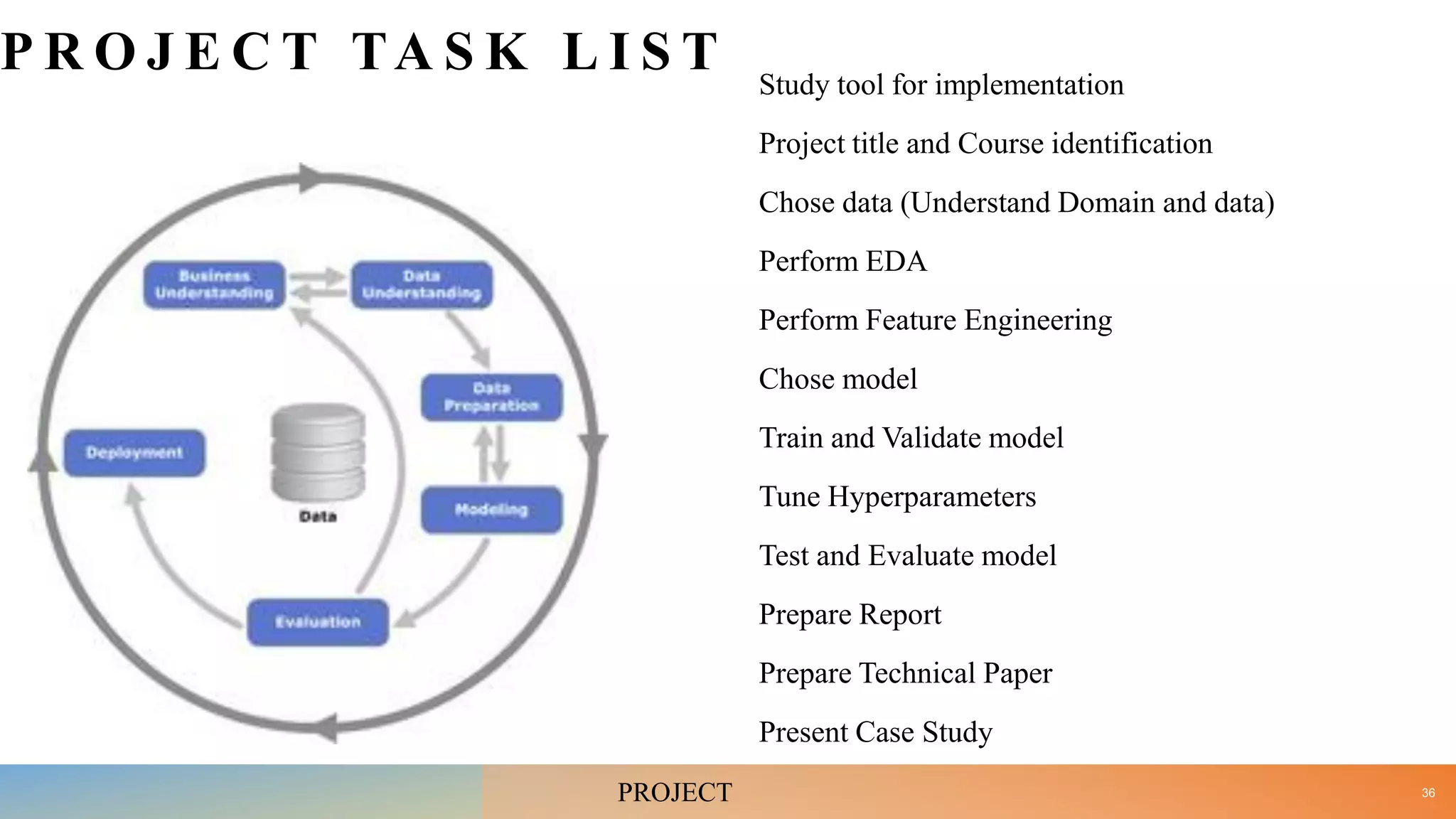
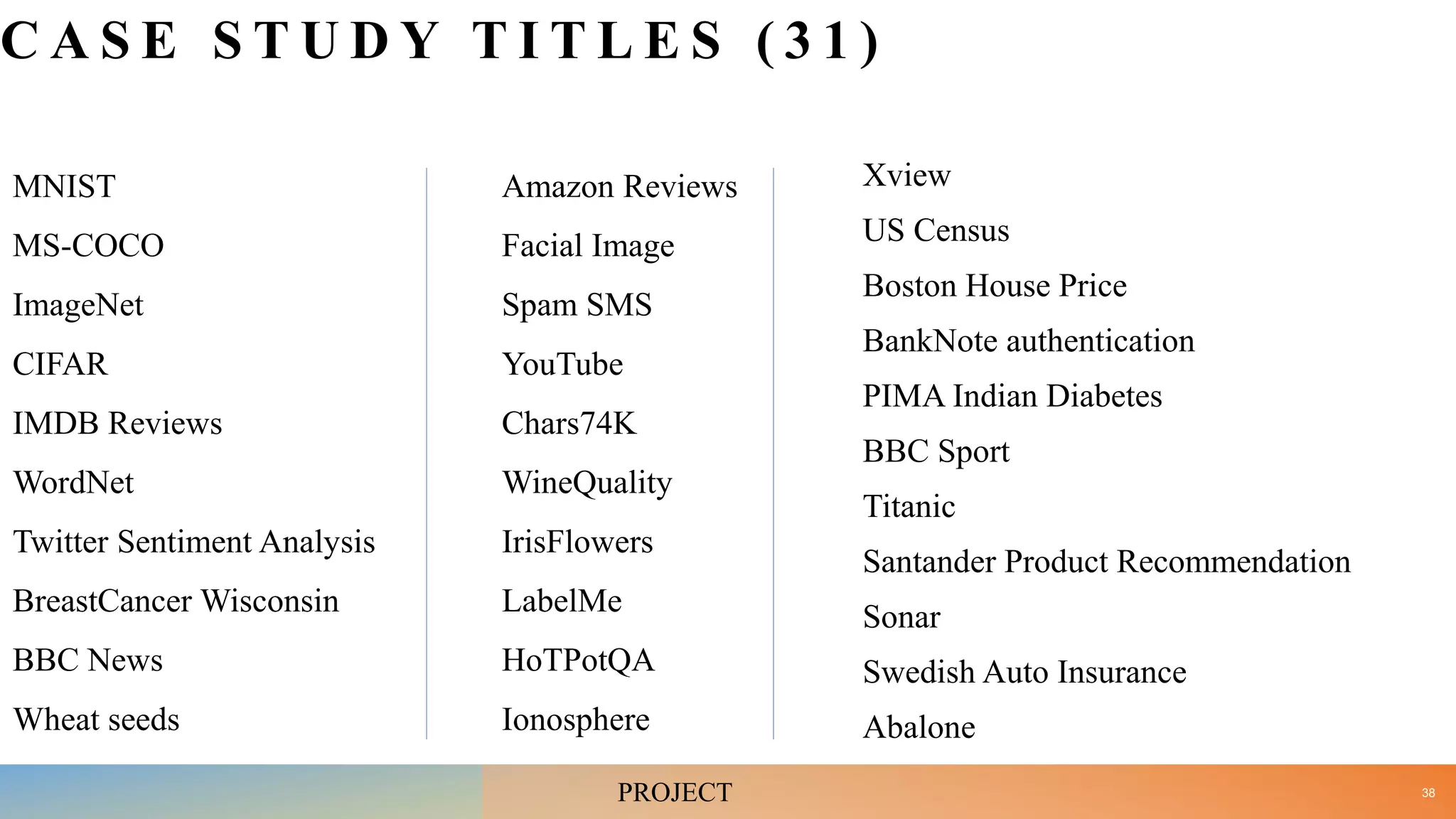
• Examine steps in developing Machine Learning application with respect to your mini project. [10]
• Review the issues in Machine Learning. [10]
• State applicable use case for each ML algorithm. [10]
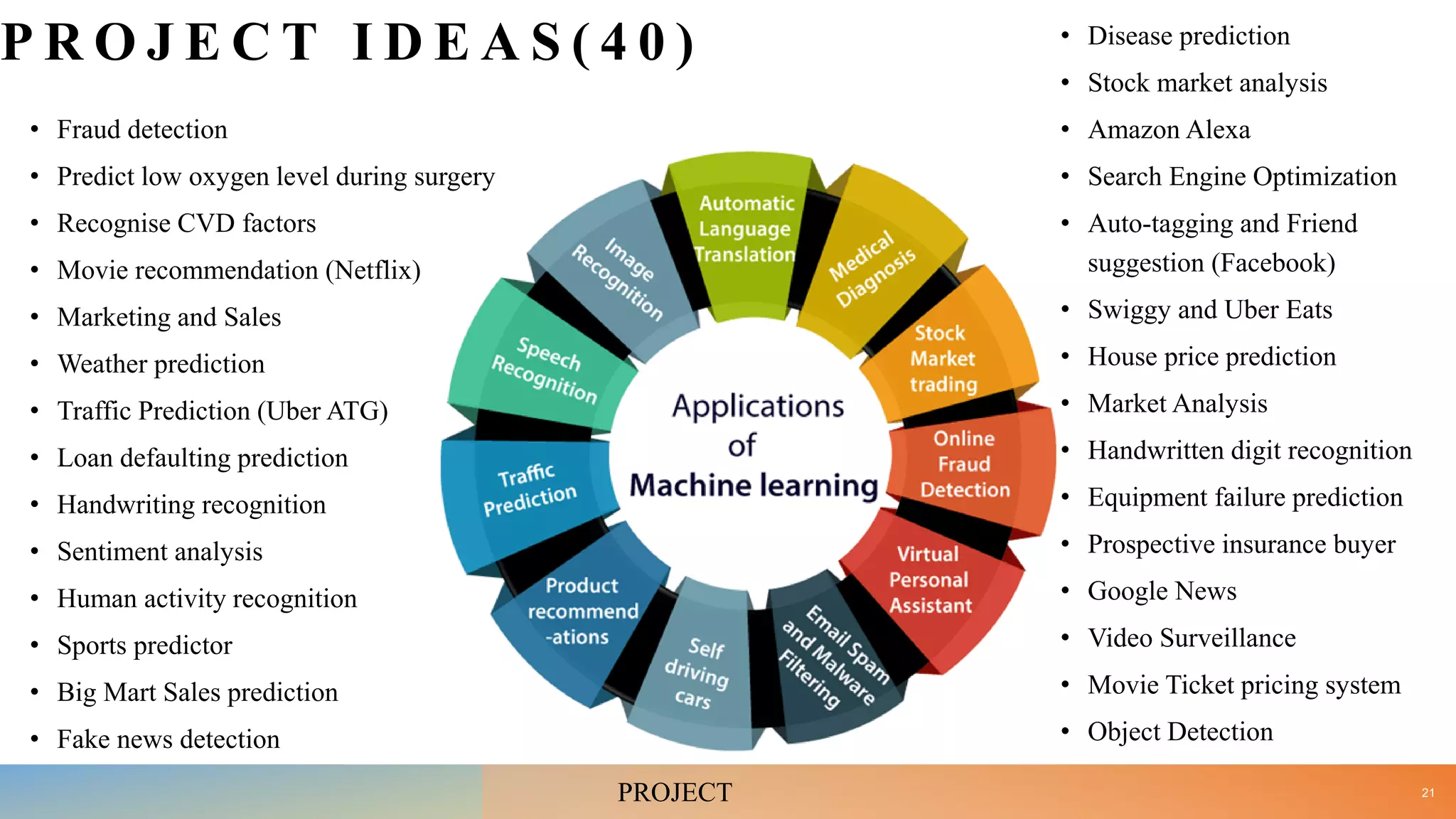
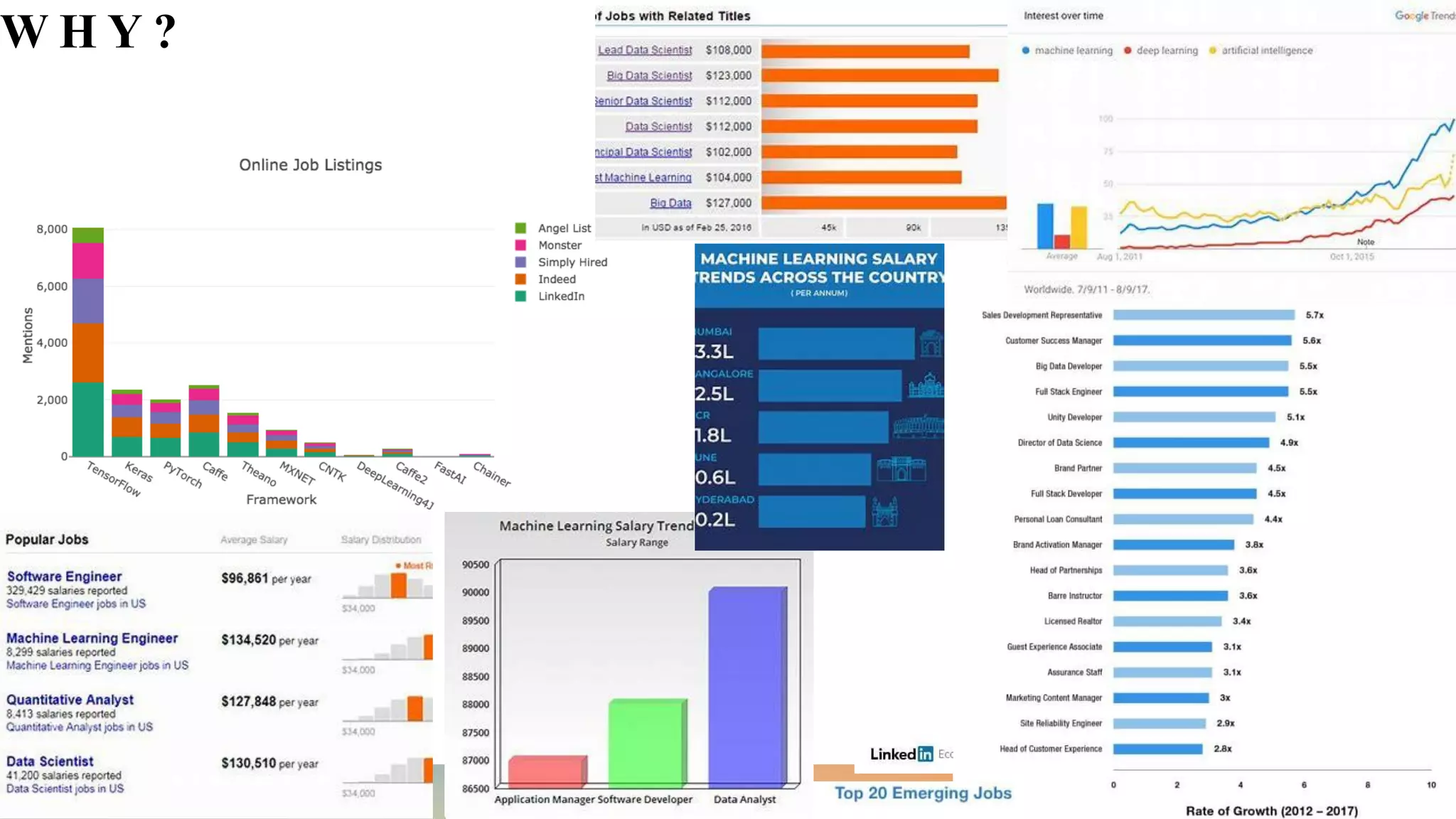
• Examine Applications of AI. [10]
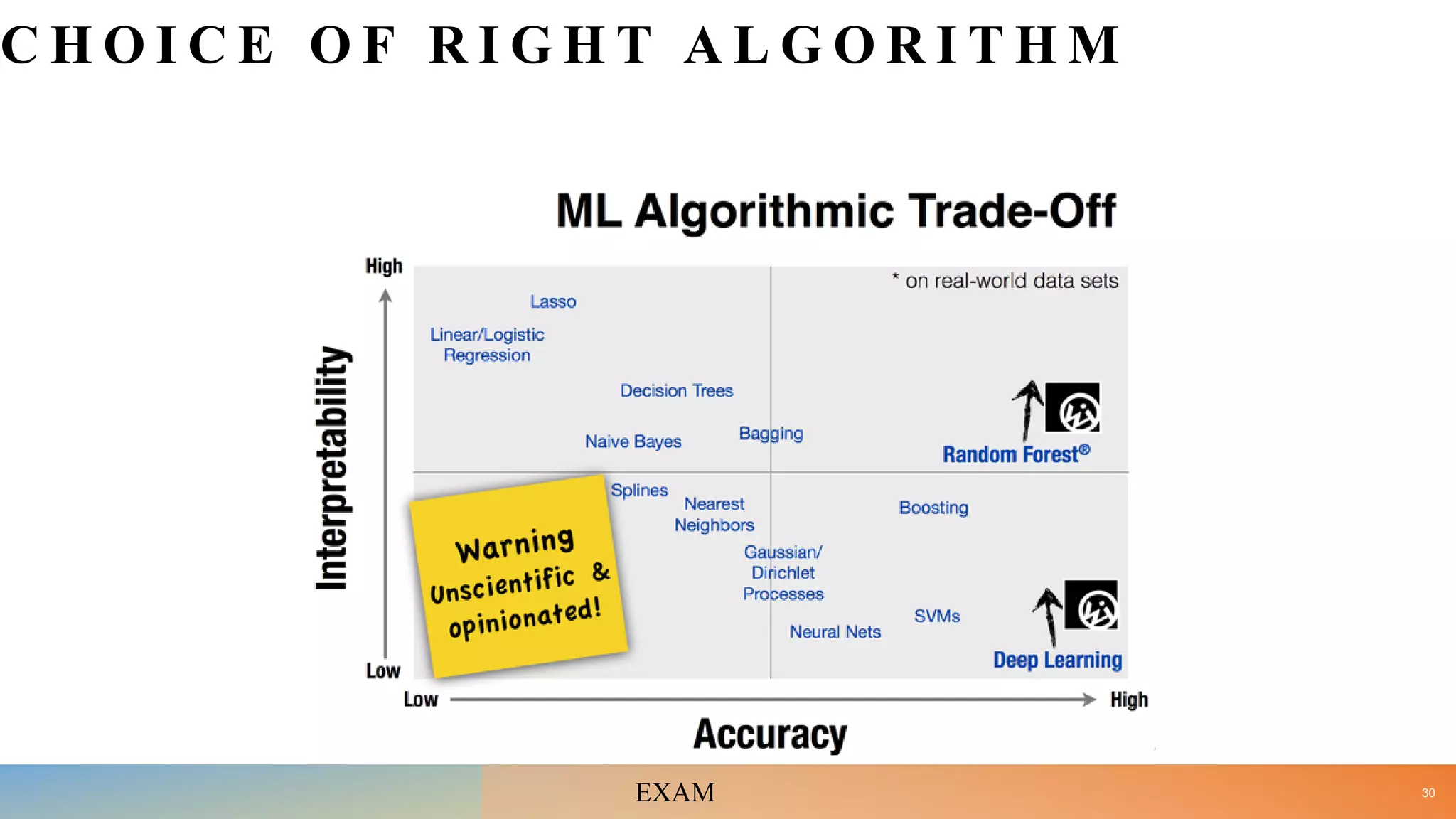
• Illustrate steps for selecting right ML algorithm. [10]
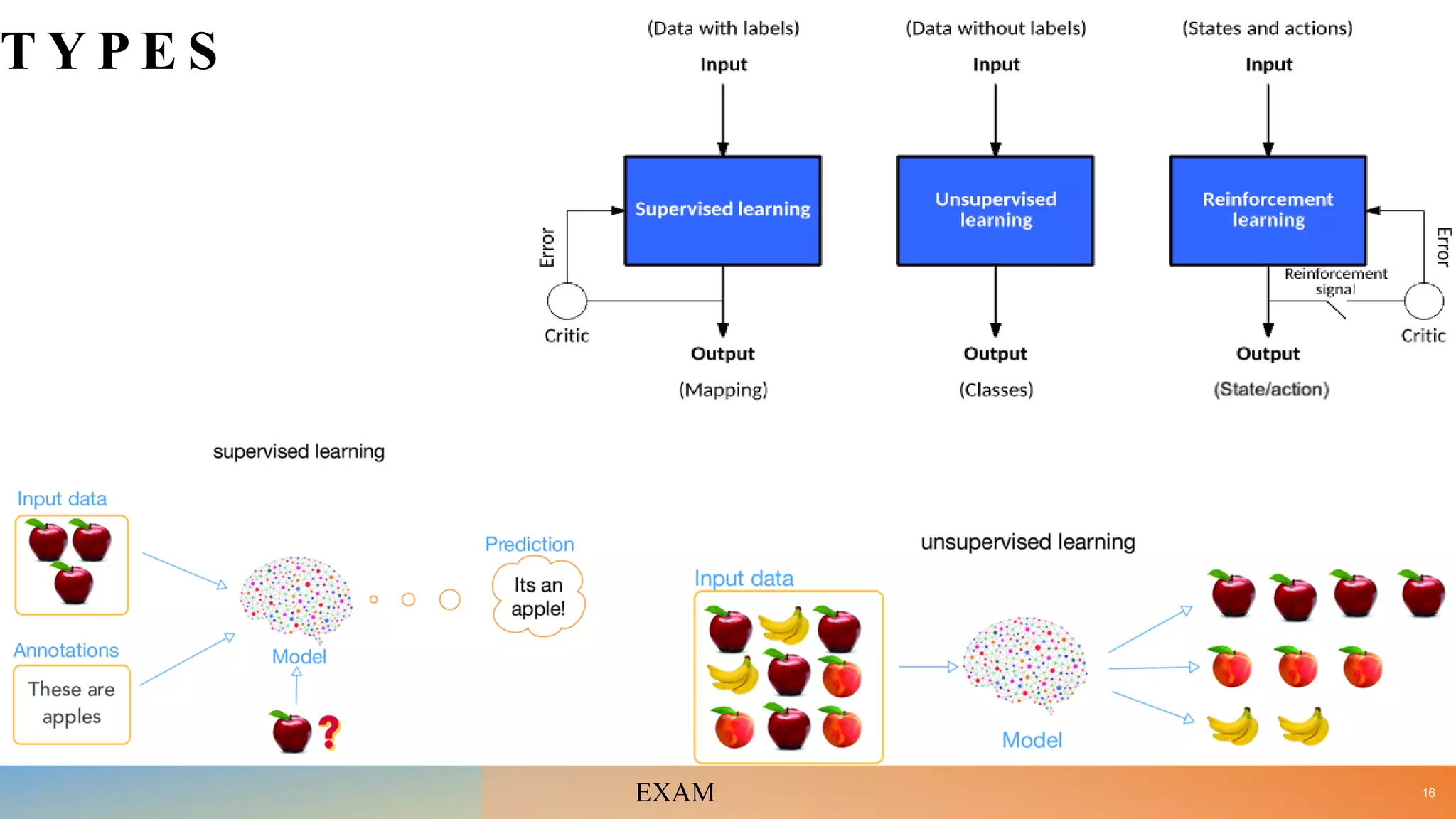
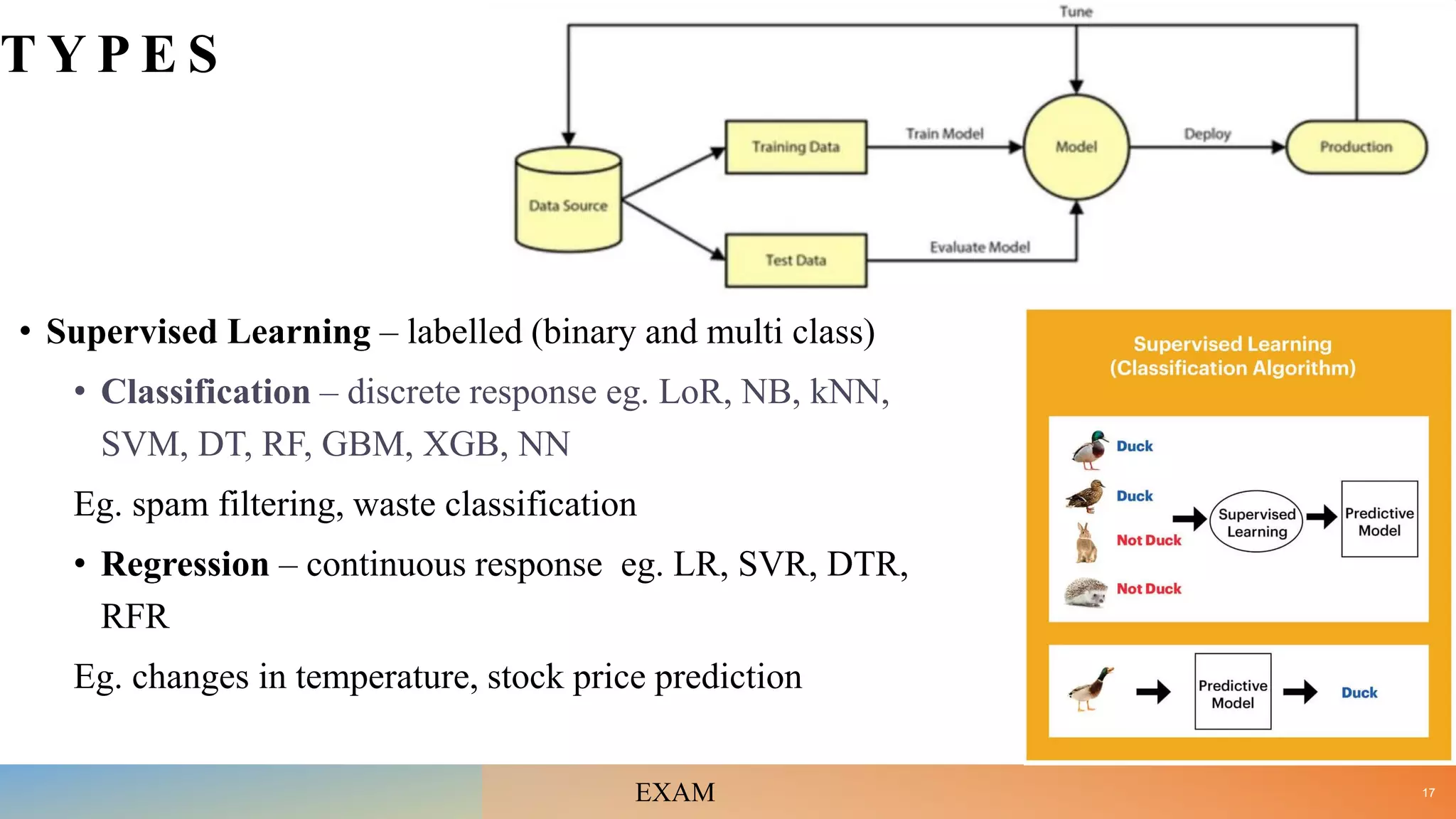
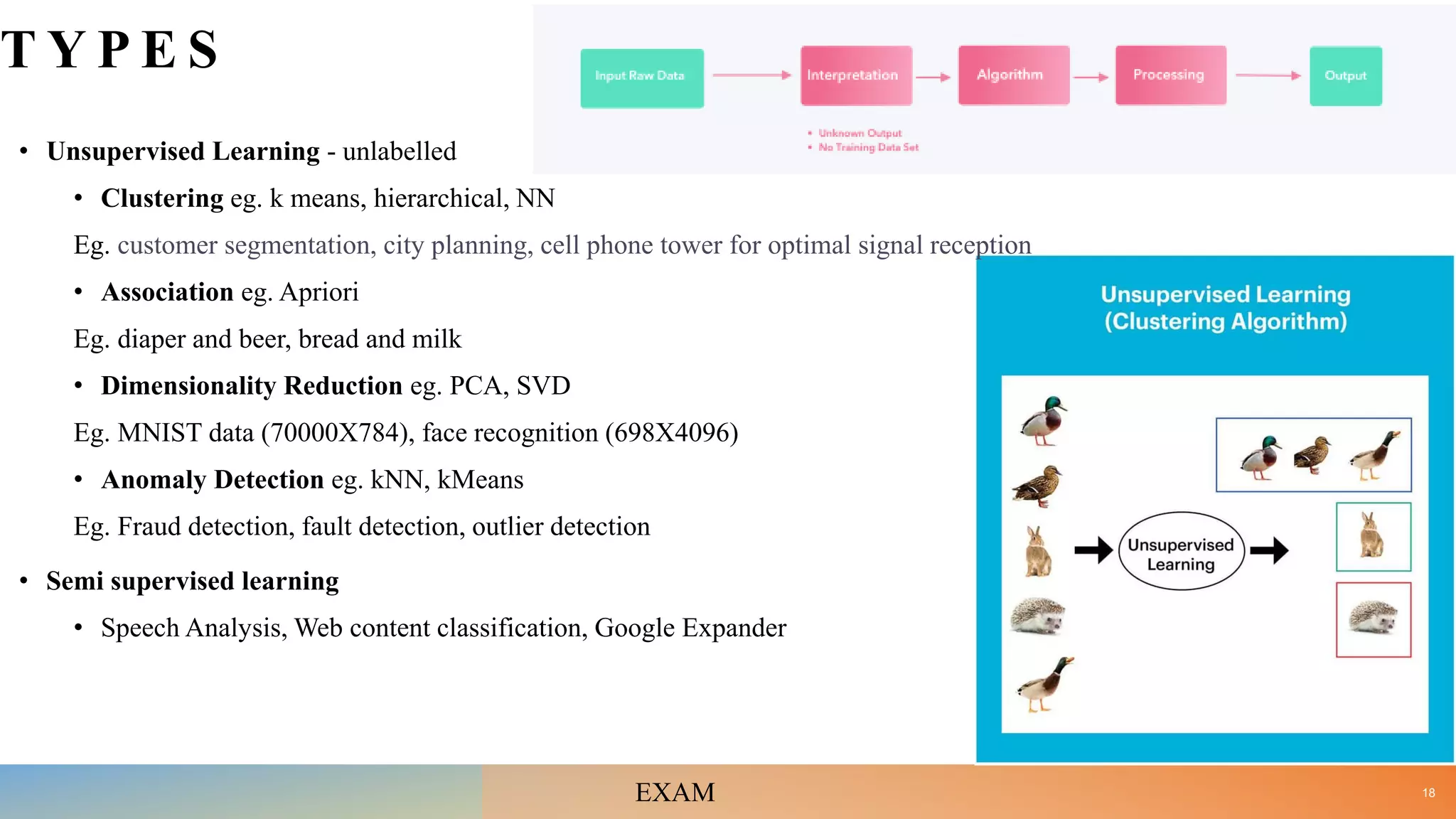
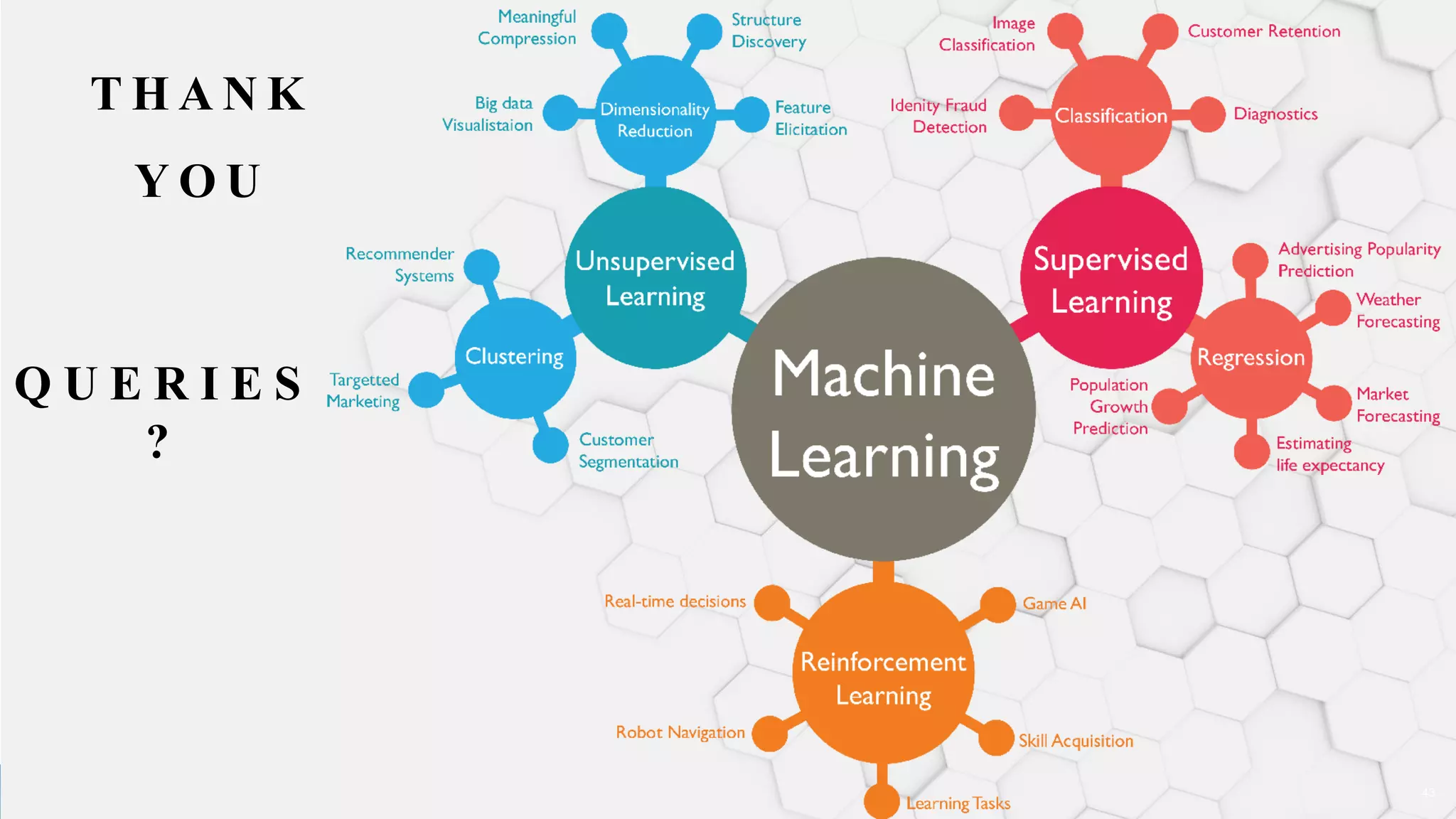
• Define ML and differentiate between Supervised, Unsupervised and Reinforcement learning with the help of suitable examples. [10]
• Explain ML w.r.t. identifying Tasks, Experience and Performance measure (Tom Mitchell). [10]
• designing a checkers learning problem
• designing a handwriting recognition learning problem
• designing a Robot driving learning problem
• Illustrate with example how Supervised learning can be used in handling loan defaulters. [10]
• Explain Supervised Learning with neat diagram. [10]
42
EXAM](https://image.slidesharecdn.com/mlmodule1slideshare-220810033519-c8fd624a/75/ML-MODULE-1_slideshare-pdf-42-2048.jpg)

This document provides an outline for a machine learning syllabus. It includes 14 modules covering topics like machine learning terminology, supervised and unsupervised learning algorithms, optimization techniques, and projects. It lists software and hardware requirements for the course. It also discusses machine learning applications, issues, and the steps to build a machine learning model.




















































































