
Downloaded 199 times



![Cultural shift toward data sharing
▪ National and international policies
– US NSF and NIH [1, 2]
– OECD (Organisation for Economic Co-operation and
Development) [3]
– INSPIRE Infrastructure for Spatial Information in the European
Community EU Commission [4]
– UK Medical Research Council [5]
Dryad ―enables scientists to validate
published findings, explore new analysis
methodologies, repurpose data for research
questions unanticipated by the original
authors, and perform synthetic studies.‖
(http://datadryad.org/)](https://image.slidesharecdn.com/dcmi-greenberg-august22-slideshare-120822153150-phpapp02/75/NISO-DCMI-Webinar-Metadata-for-Managing-Scientific-Research-Data-4-2048.jpg)





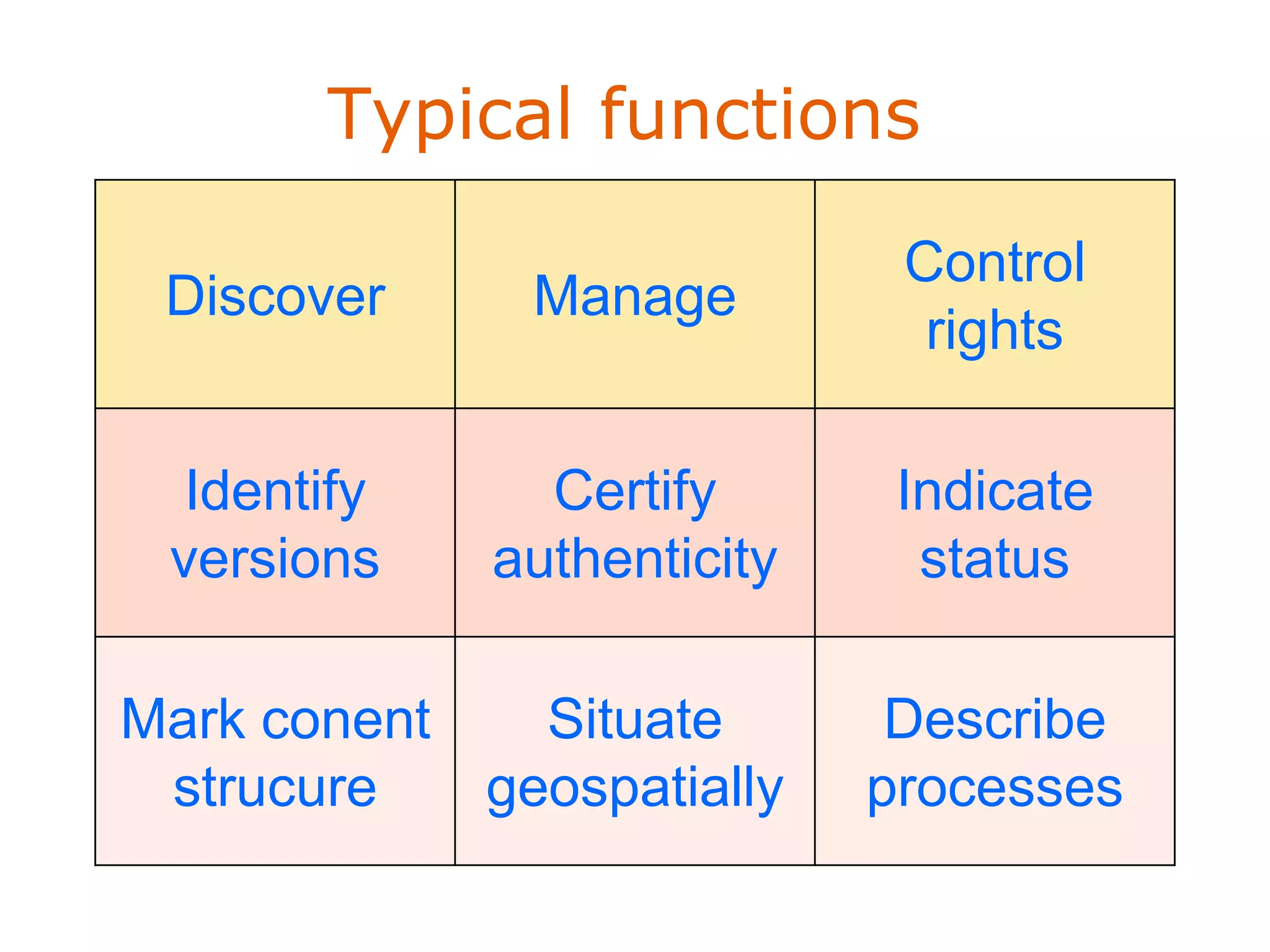





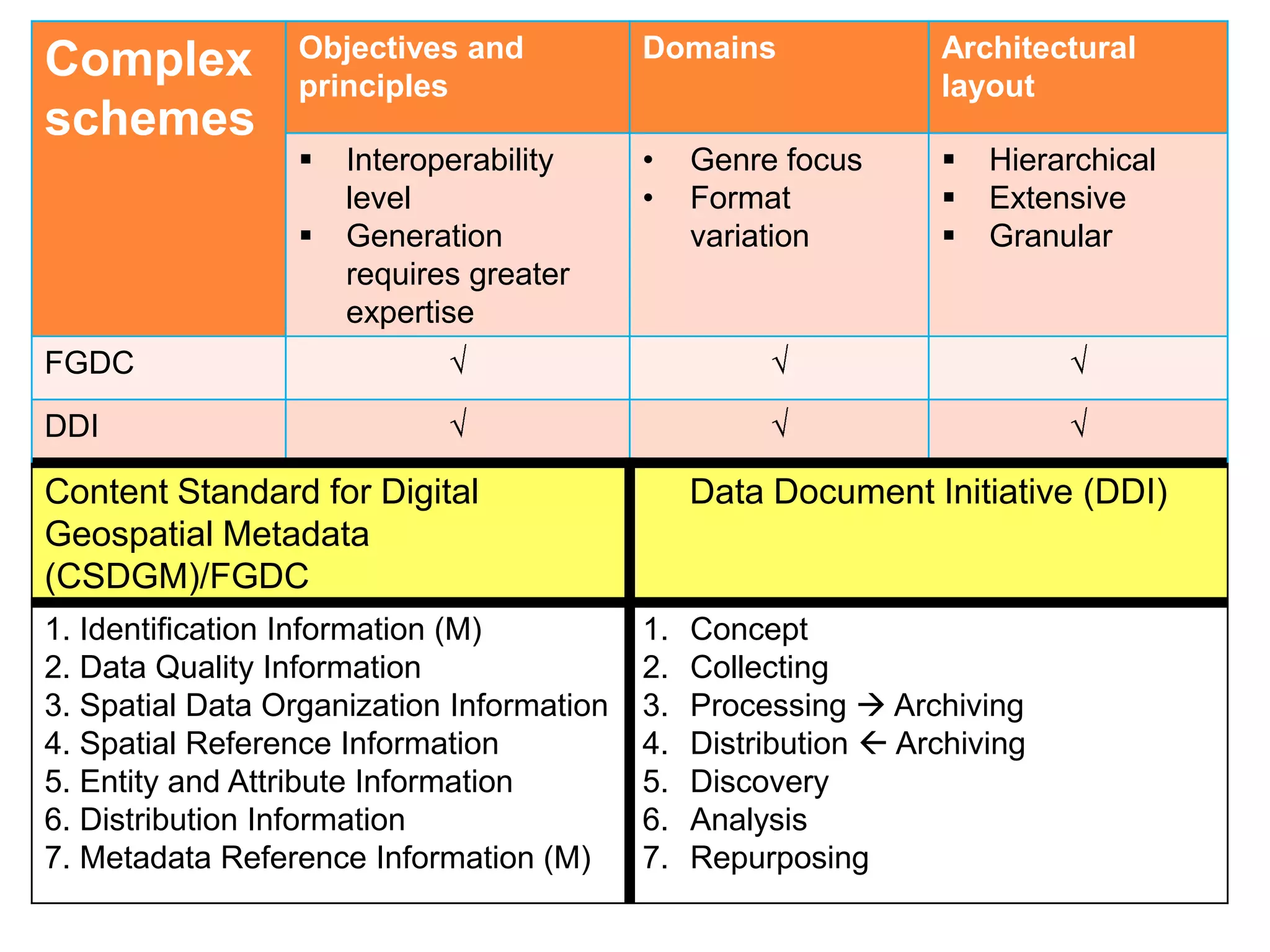
![Objectives and Domains Architectural
Simple principles layout
schemes
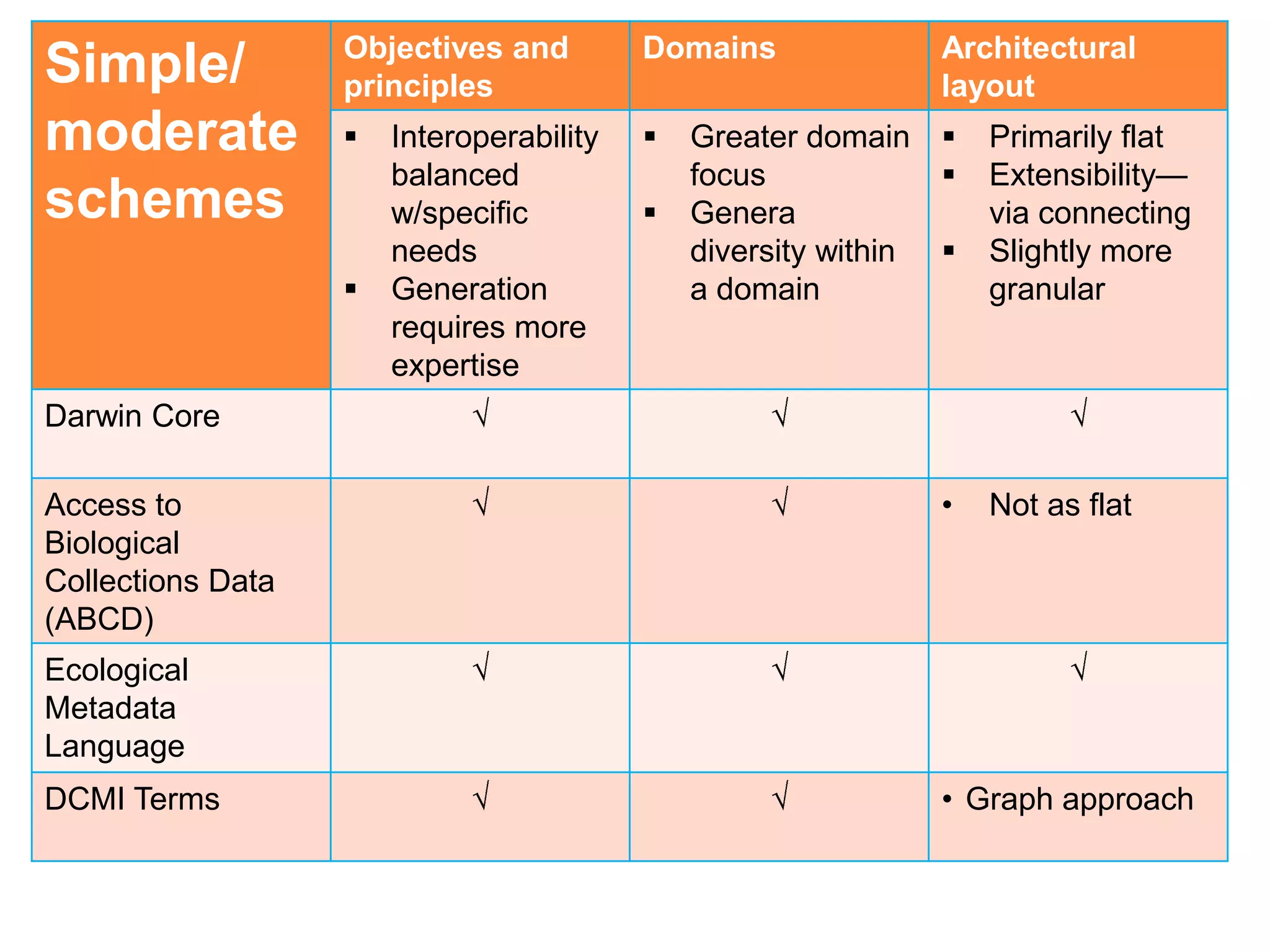
[6] • Interoperability • Multi- • Primarily flat
• Easy to disciplinary • Minimal with
generate, • Any genre or means to
lower barrier format extend
to produce • General (not
granular)
Dublin Core
Metadata
Element Set
(DCMES)
ver.1.1
US MARC • Need training • Primarily flat
bibliographic • Extensible
format
DataCite • Primarily flat](https://image.slidesharecdn.com/dcmi-greenberg-august22-slideshare-120822153150-phpapp02/75/NISO-DCMI-Webinar-Metadata-for-Managing-Scientific-Research-Data-16-2048.jpg)
![Dublin Core
Application
Profile-
Dryad [7]
](https://image.slidesharecdn.com/dcmi-greenberg-august22-slideshare-120822153150-phpapp02/75/NISO-DCMI-Webinar-Metadata-for-Managing-Scientific-Research-Data-17-2048.jpg)
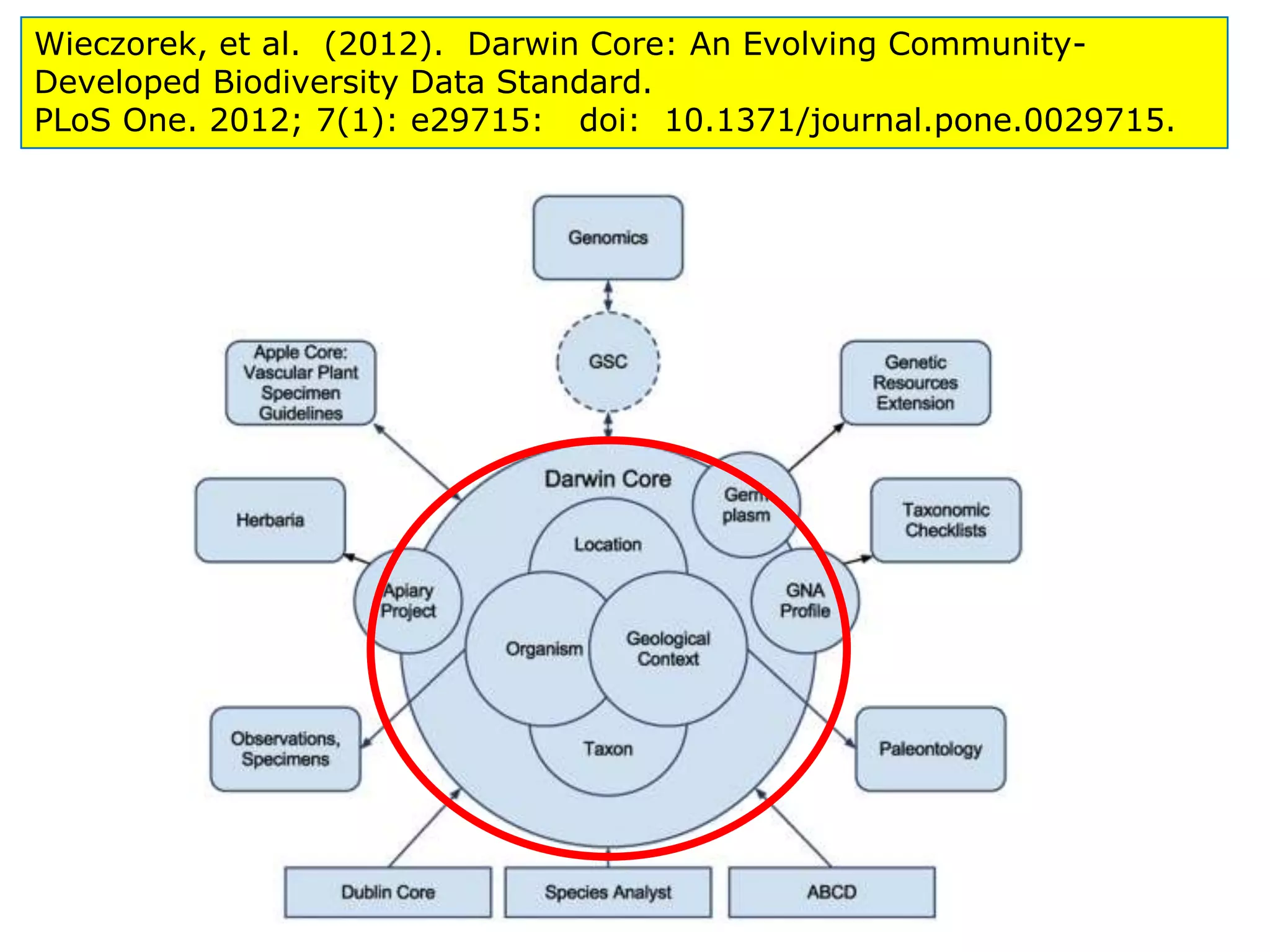
![DataCite example, ver.2.2 [8]
National Institute for
Environmental Studies and
Center for Climate System
Research Japan](https://image.slidesharecdn.com/dcmi-greenberg-august22-slideshare-120822153150-phpapp02/75/NISO-DCMI-Webinar-Metadata-for-Managing-Scientific-Research-Data-18-2048.jpg)
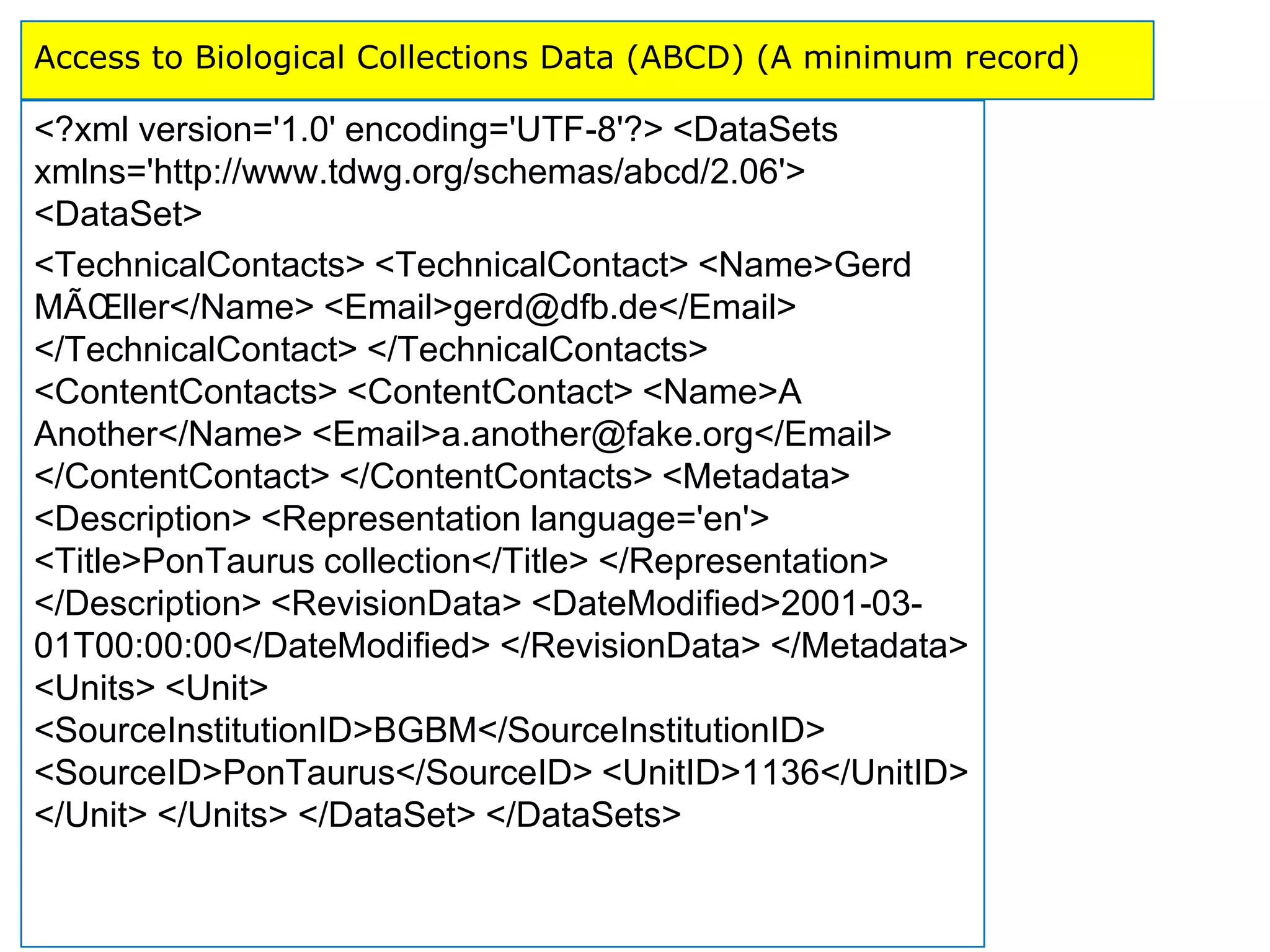
![US MARC bibliographic
format: World Ocean
Circulation Experiment global
data (Moss Landing Marine
Labs and the Monterey Bay
Aquarium Research Institute
Library) [9]](https://image.slidesharecdn.com/dcmi-greenberg-august22-slideshare-120822153150-phpapp02/75/NISO-DCMI-Webinar-Metadata-for-Managing-Scientific-Research-Data-19-2048.jpg)









![Footnotes
[1] NSF Data Sharing Policy: http://www.nsf.gov/bfa/dias/policy/dmp.jsp.
[2] NIH Data Sharing Policy: http://grants.nih.gov/grants/policy/data_sharing/.
[3] ORGANISATION FOR ECONOMIC CO-OPERATION AND DEVELOPMENT/Data and
Metadata Reporting and Presentation Handbook: http://www.oecd.org/std/37671574.pdf.
[4] The INSPIRE Infrastructure for Spatial Information in the European Community):
http://inspire.ec.europa.eu/index.cfm/pageid/48. directive released 15 May 2007 and will be
implemented in various stages, with full implementation required by 2019, and aims to create a
European Union (EU) spatial data infrastructure.
[5] UK medical research council:
http://www.mrc.ac.uk/Ourresearch/Ethicsresearchguidance/datasharing/index.html.
[6] The DCMI Glossary (scroll down for ―schema‖ entry):
http://dublincore.org/documents/usageguide/glossary.shtml#schema.
[7] Dublin Core Example: Data from: Divergence time estimation using fossils as terminal taxa
and the origins of Lissamphibia (Dryad repository):
http://datadryad.org/resource/doi:10.5061/dryad.8120?show=full.
[8] National Institute for Environmental Studies and Center for Climate System Research
Japan—animation data (DataCite): http://schema.datacite.org/meta/kernel-
2.2/example/datacite-metadata-sample-v2.2.xml.
[9] US MARC bibliographic format: World Ocean Circulation Experiment global data (Moss
Landing Marine Labs and the Monterey Bay Aquarium Research Institute Library):
http://mlml.kohalibrary.com/cgi-bin/koha/opac-detail.pl?biblionumber=9282.](https://image.slidesharecdn.com/dcmi-greenberg-august22-slideshare-120822153150-phpapp02/75/NISO-DCMI-Webinar-Metadata-for-Managing-Scientific-Research-Data-33-2048.jpg)
This document summarizes a webinar on metadata for managing scientific research data. The webinar covered why metadata is important for scientific data management, definitions of data and metadata, selected metadata standards including Dublin Core, Darwin Core and FGDC, challenges in generating metadata and opportunities to address these challenges, and advice for getting started with metadata. The webinar emphasized that metadata standards provide guidelines not strict rules, and encouraged participants to keep metadata simple while aiming to facilitate reuse of data.























































































