Download to read offline







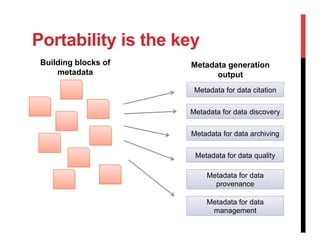

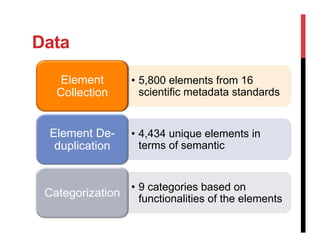

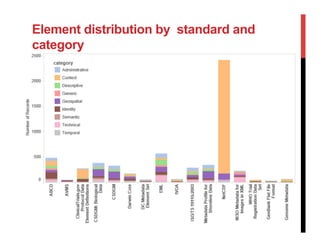









The document discusses the challenges and complexities of metadata standards for scientific data, highlighting issues such as unwieldiness, difficulties in understanding, and the need for customization. It emphasizes the importance of metadata portability, proposing measures to assess it and exploring the concept of a metadata infrastructure that is portable, customizable, and reusable. The document concludes with a call for further research to address gaps in current practices and to define the necessary components of a metadata infrastructure.





















































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)
