
Download as PDF, PPTX





















![Representing
Texts
Digitally
Embeddings
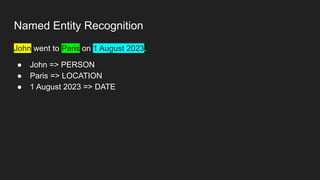
● The apple is in the tree.
○ 1-[0.01234, -0.23456, 0.87654,
0.45678, -0.56123, 0.65432,
0.12345, -0.77123, 0.08456,
0.34567, ...]
○ 2-different vector
○ 3-different vector
○ 4-different vector
○ 1-[0.01234, -0.23456, 0.87654,
0.45678, -0.56123, 0.65432,
0.12345, -0.77123, 0.08456,
0.34567, ...]
○ 5-different vector](https://image.slidesharecdn.com/niso04-vectordbragandassistants-240429200337-f68d4302/85/Mattingly-AI-Prompt-Design-Structured-Data-Assistants-RAG-24-320.jpg)
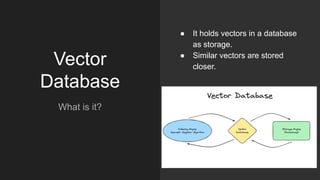
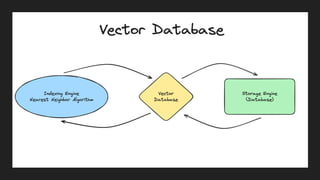
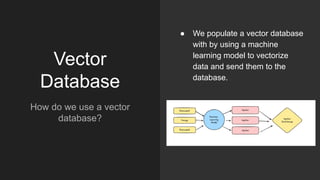
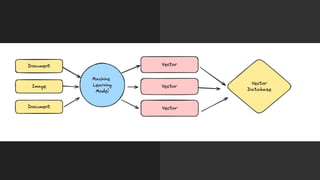

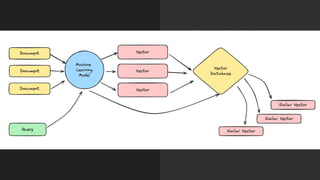

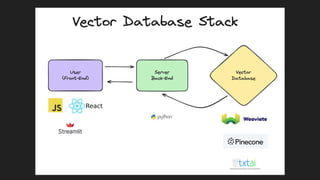

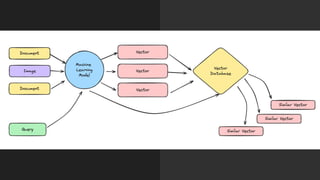





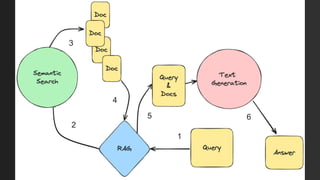
The document discusses the importance of structured data and methods to generate it using large language models (LLMs), highlighting the need for consistency in output and various data formats like CSV, JSON, and XML. It explores the role of vector databases in semantic search and retrieval-augmented generation (RAG), emphasizing the way they enhance the capabilities of LLMs by providing relevant context and reducing inaccuracies. Practical exercises are included to help apply the concepts presented, particularly in creating consistent structured data outputs.



































































