Download to read offline








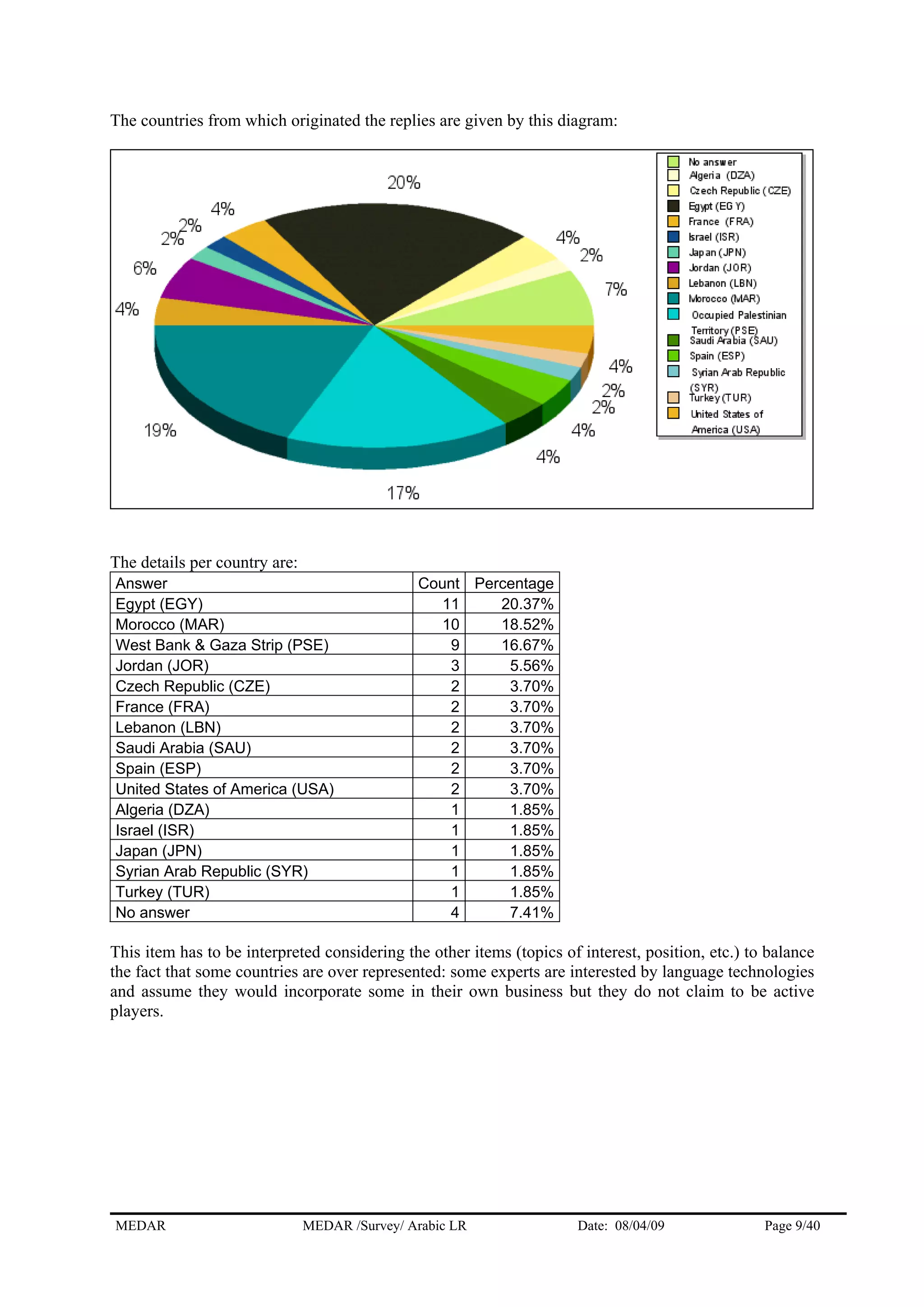
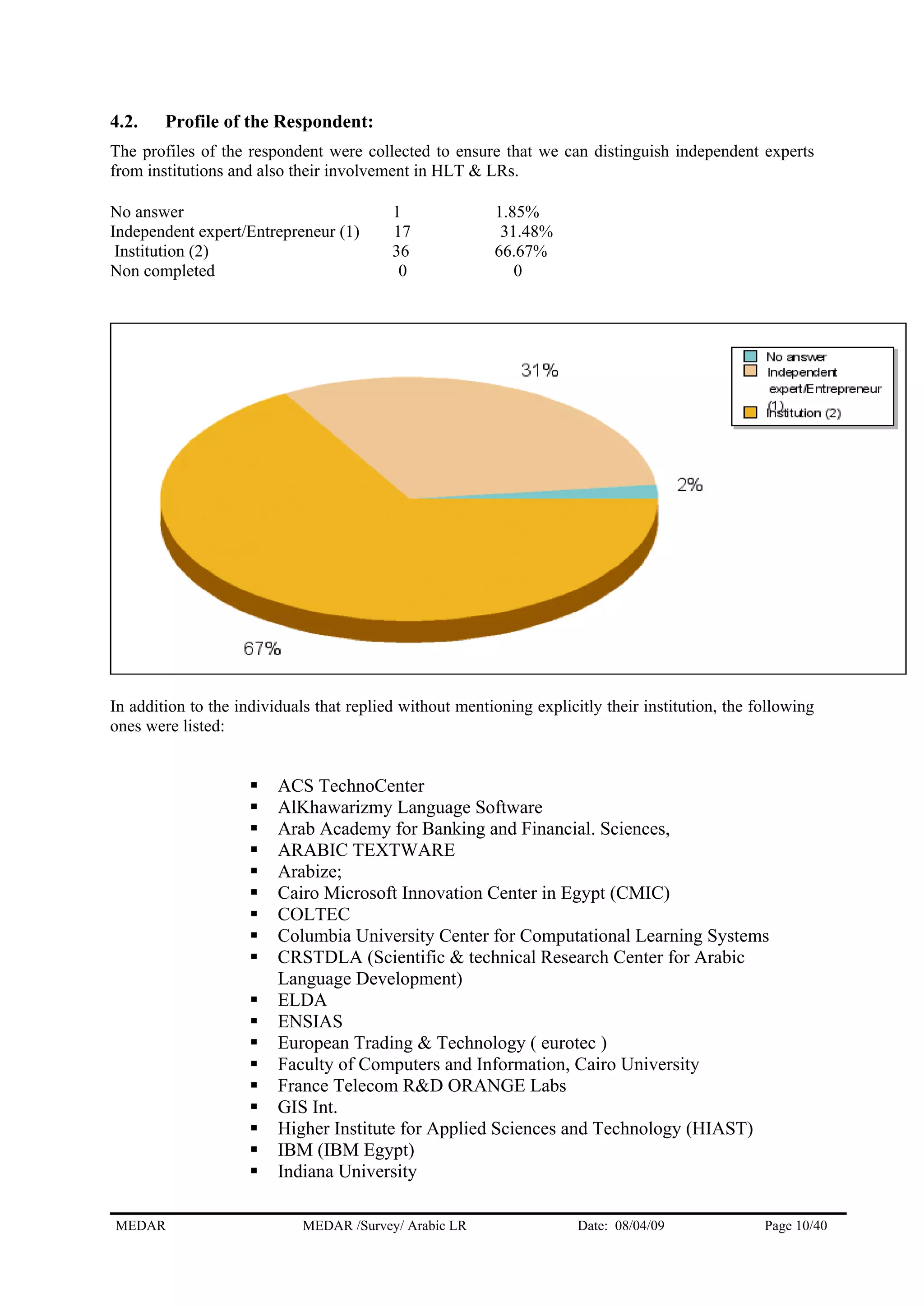
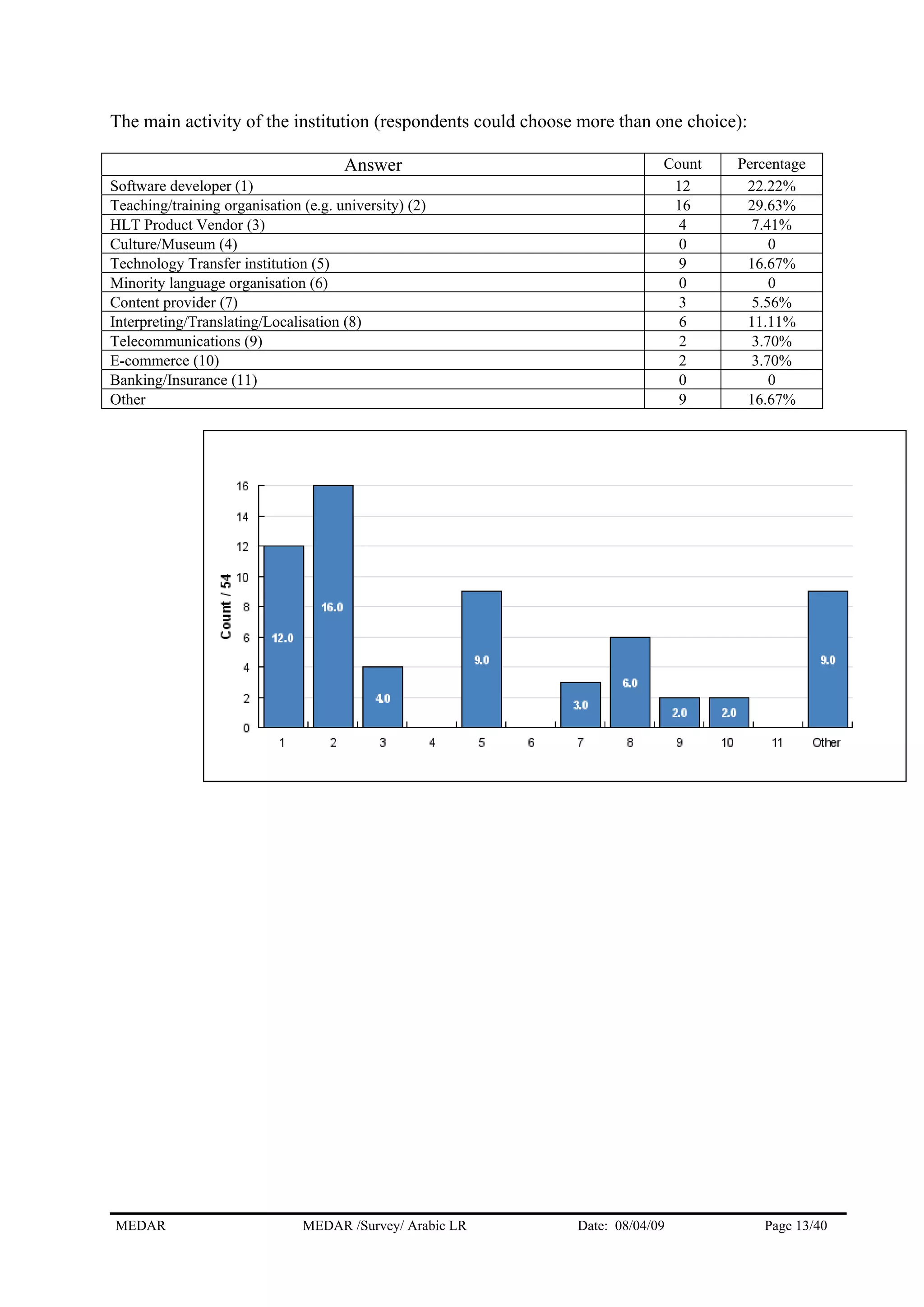
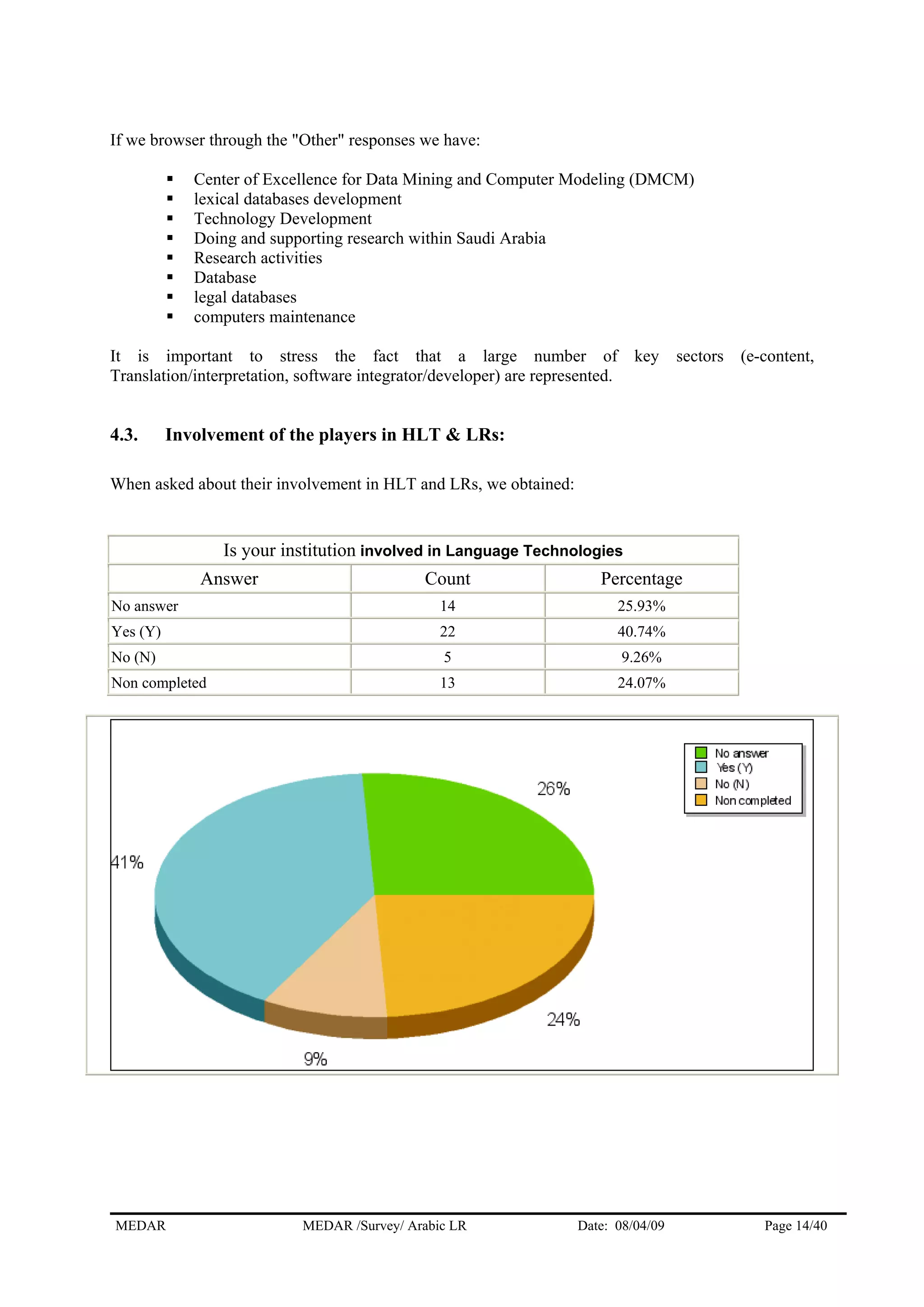
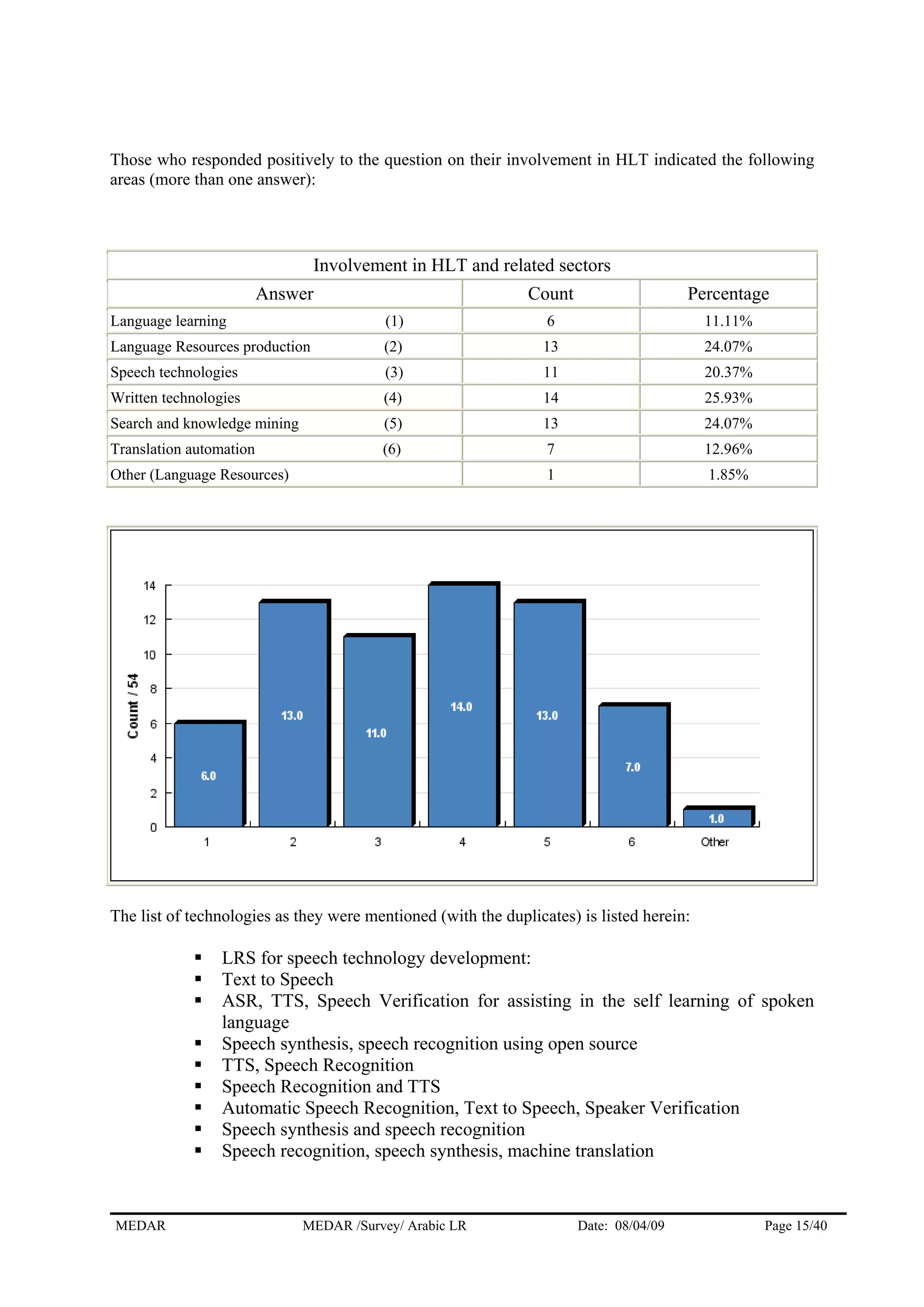

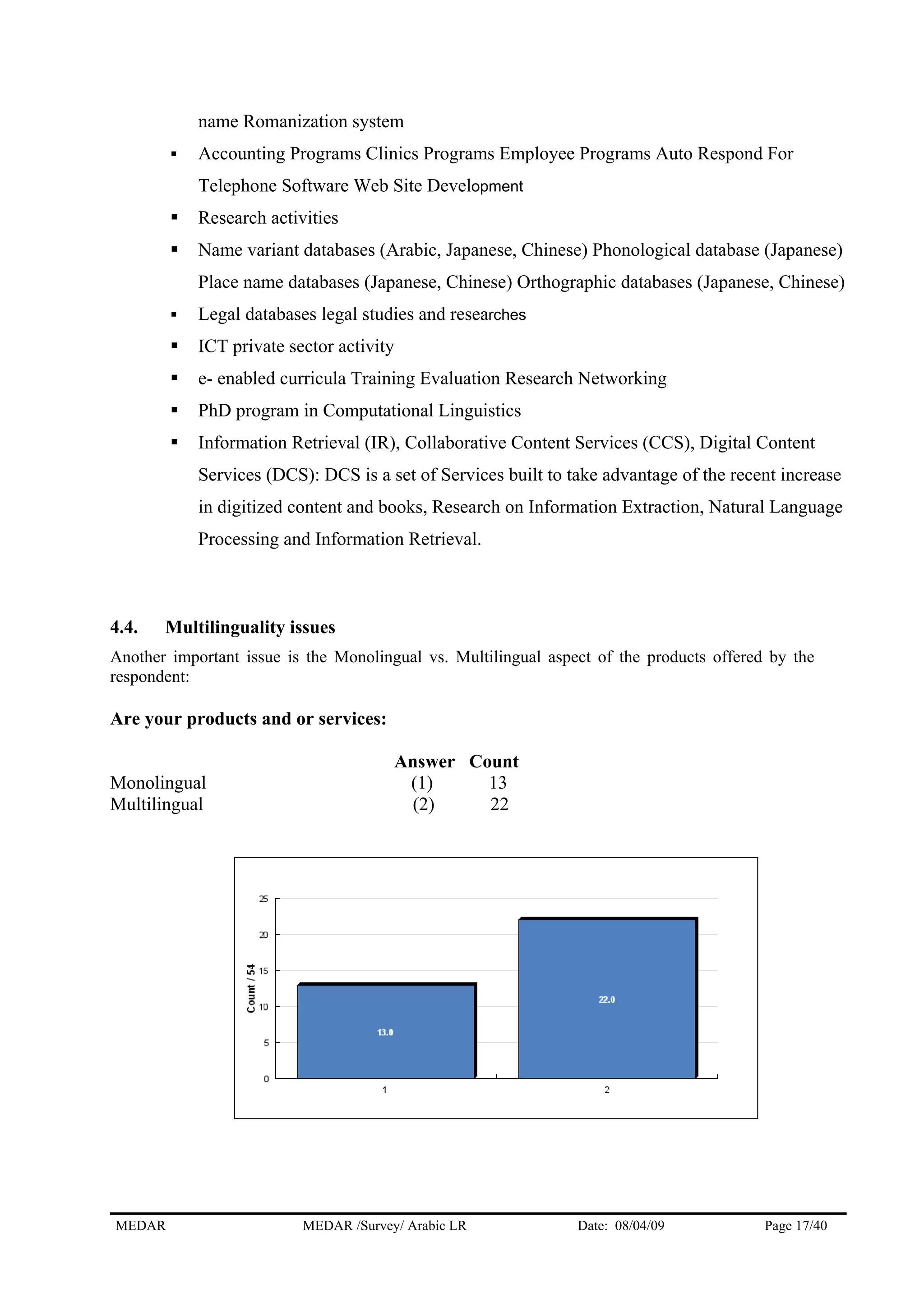













The MEDAR survey collected responses from 57 players involved in human language technologies and language resources for Arabic. The responses came from a variety of countries, with the highest numbers coming from Egypt (11), Morocco (10), and West Bank & Gaza Strip (9). The majority of respondents (36) answered on behalf of institutions, while 17 answered as independent experts. The survey gathered information on the respondents' profiles, language resources, needs for resources, and market information to understand the current state of language technologies for Arabic.










































































