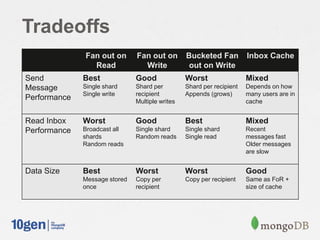
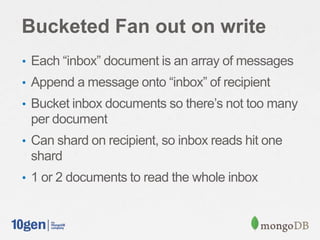
The document provides an overview of building a scalable messaging system using MongoDB and Java, highlighting various schema designs and query methods for managing user interactions in a social networking context. It discusses user and relationship collections, indexing for performance, and different design patterns for handling message storage and retrieval, including fan out on read, fan out on write, and bucketed fan out on write strategies. Additionally, it presents sample code for implementing these strategies within a Java application, ensuring efficient processing and storage of data.








![The User Document
{ "_id": ObjectId("519c12d53004030e5a6316d2"),
"address": {
"streetAddress": "2600 Rafe Lane",
"city": "Jackson",
"state": "MS",
"zip": 39201,
"country": "US" },
"birthday": "IDODate("1980-12-26T00:00:00.000Z"),
"company": "Parade of Shoes",
"domain": "SanFranciscoAgency.com",
"email": "AnthonyJDacosta@pookmail.com",
"firstName": "Anthony",
"gender": "male",
"lastName": "Dacosta",
"location": [ -90.183518, 32.368619 ],
…
}](https://image.slidesharecdn.com/2013-5scalableinboxprojectjava-130927151511-phpapp01/85/Building-a-Scalable-Inbox-System-with-MongoDB-and-Java-9-320.jpg)





![Message Document
The message document:
> db.messages.findOne()
{
"_id": "ObjectId("519d4858e4b079162fe7eb12"),
"uid": "48268973", // the author id
"username": "Abiall", // why store the username?
"text": "Lorem ipsum dolor sit amet, consectetur ...",
"created": ISODate(2013-05-22T22:36:08.663Z"),
"location": [ -95.470188, 37.366044 ],
"tags": [ "gadgets" ]
}
Collection statistics:
> db.messages.stats()
{
"ns": "msg.messages",
"count": 21440518,
"size": 14184598000,
"avgObjSize": 661.5790719235422,
"storageSize": 15749418944,
"numExtents": 27,
"nindexes": 2,
"lastExtentSize": 2146426864,
"paddingFactor": 1,
"systemFlags": 1,
"userFlags": 0,
"totalIndexSize": 1454289648,
"indexSizes": {
"_id_": 695646784,
"uid_1_created_1": 758642864 },
"ok": 1
}](https://image.slidesharecdn.com/2013-5scalableinboxprojectjava-130927151511-phpapp01/85/Building-a-Scalable-Inbox-System-with-MongoDB-and-Java-15-320.jpg)
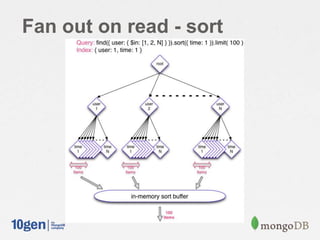
![Implementing the Outbox
The query is on "uid" and needs to be sorted by descending "created" time:
> db.messages.ensureIndex({ "uid": 1, "created": 1 } ) // use a compound index
> db.messages.find({ "uid": "31837072" } ).sort({ "created": -1 } ).limit(100)
{ "_id": ObjectId("519d626ae4b07916312e15b1") }, "uid": "31837072", "username": "Roya
"text": "Lorem ipsum dolor sit amet, consectetur adipisicing elit , sed do eiusmod tempor …",
"created": ISODate("2013-05-23T00:27:22.369Z"),
"location": [ "-118.296138", "33.772832" ],
"tags": [ "Art" ] }
…
> db.messages.find({ "uid": "31837072" }).sort({ "created": -1 }).limit(100).explain()
{
"cursor": "BtreeCursor uid_1_created_1 reverse",
"n": 18,
"nscannedObjects": 18,
"nscanned": 18,
"scanAndOrder": false,
"millis": 0
…](https://image.slidesharecdn.com/2013-5scalableinboxprojectjava-130927151511-phpapp01/85/Building-a-Scalable-Inbox-System-with-MongoDB-and-Java-16-320.jpg)










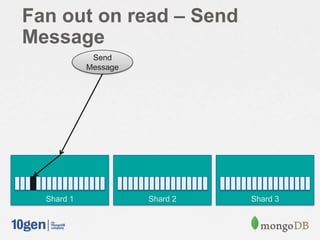
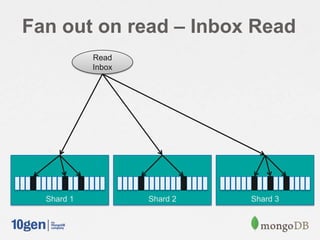
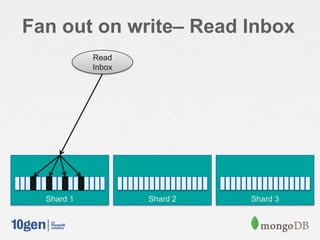
![Fan out on Read
Put the followees ids in a list:
> var fees = []
> db.followees.find({user: "11622712"})
.forEach( function(doc) { fees.push( doc.followee ) } )
Use $in and sort() and limit() to gather the inbox:
> db.messages.find({ uid: { $in: fees } }).sort({ created: -1 }).limit(100)
{ "_id": ObjectId("519d627ce4b07916312f0a09"), "uid": "34660390", "username": "Dingdowas"
{ "_id": ObjectId("519d627ce4b07916312f0a10"), "uid": "34661390", "username": "John" } …
{ "_id": ObjectId("519d627ce4b07916312f0a11"), "uid": "34662390", "username": "Brenda" } …
…](https://image.slidesharecdn.com/2013-5scalableinboxprojectjava-130927151511-phpapp01/85/Building-a-Scalable-Inbox-System-with-MongoDB-and-Java-27-320.jpg)



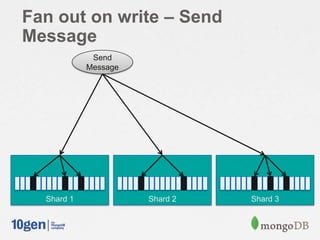

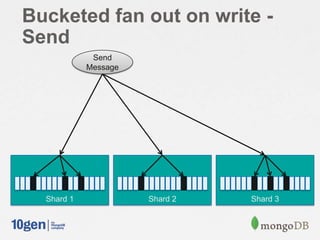
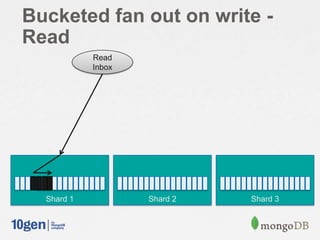
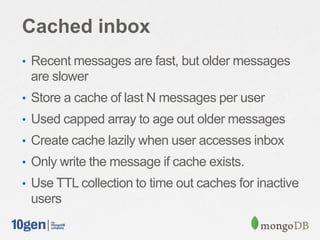
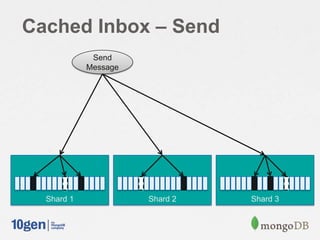
![Cached Inbox
// Shard on “owner"
db.shardCollection(”myapp.caches”, { ”owner”: 1 } )
// Send a message, add it to the existing caches of followers
for( follower in followersOf( msg.from) ) {
db.caches.update({ owner: recipient }, { $push: { messages: {
$each: [ msg ],
$sort: { „sent‟: 1 },
$slice: -50 } } } );
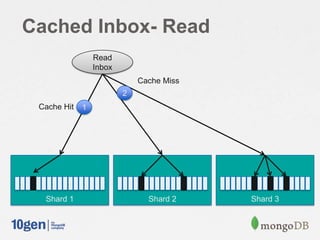
// Read my inbox
If( msgs = db.caches.find({ owner: ”Joe” }) ) {
// cache document exists
return msgs;
} else {
// fall back to "fan out on read" and cache it
db.caches.save({owner:‟joe‟, messages:[]});
msgs = db.outbox.find({sender: { $in: [ followersOf( msg.from ) ] }}).sort({sent:-1}).limit(50);
db.caches.update({user:‟joe‟}, {$push: msgs });
}](https://image.slidesharecdn.com/2013-5scalableinboxprojectjava-130927151511-phpapp01/85/Building-a-Scalable-Inbox-System-with-MongoDB-and-Java-41-320.jpg)