Downloaded 64 times






![Design Session
Design documents that simply map to your application
> post = { author: "Hergé",
date: ISODate("2011-09-18T09:56:06.298Z"),
text: "Destination Moon",
tags: ["comic", "adventure"]
}
> db.blogs.save(post)](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-11-320.jpg)
![Find the document
> db.blogs.find()
{ _id: ObjectId("4c4ba5c0672c685e5e8aabf3"),
author: "Hergé",
date: ISODate("2011-09-18T09:56:06.298Z"),
text: "Destination Moon",
tags: [ "comic", "adventure" ]
}
Notes:
• ID must be unique, but can be anything you’d like
• MongoDB will generate a default ID if one is not supplied](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-12-320.jpg)

![Examine the query plan
> db.blogs.find( { author: "Hergé" } ).explain()
{
"cursor" : "BtreeCursor author_1",
"nscanned" : 1,
"nscannedObjects" : 1,
"n" : 1,
"millis" : 5,
"indexBounds" : {
"author" : [
[
"Hergé",
"Hergé"
]
]
}
}](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-14-320.jpg)
![Examine the query plan
> db.blogs.find( { author: "Hergé" } ).explain()
{
"cursor" : "BtreeCursor author_1",
"nscanned" : 1,
"nscannedObjects" : 1,
"n" : 1,
"millis" : 5,
"indexBounds" : {
"author" : [
[
"Hergé",
"Hergé"
]
]
}
}](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-15-320.jpg)




![Extending the Schema
> db.blogs.find( { author: "Hergé"} )
{ _id : ObjectId("4c4ba5c0672c685e5e8aabf3"),
author : "Hergé",
date : ISODate("2011-09-18T09:56:06.298Z"),
text : "Destination Moon",
tags : [ "comic", "adventure" ],
comments : [
{
author : "Kyle",
date : ISODate("2011-09-19T09:56:06.298Z"),
text : "great book"
}
],
comments_count: 1
}](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-20-320.jpg)








![One to Many
Embedded Array:
•$slice operator to return subset of comments
•some queries become harder (e.g find latest comments across all blogs)
blogs: {
author : "Hergé",
date : ISODate("2011-09-18T09:56:06.298Z"),
comments : [
{
author : "Kyle",
date : ISODate("2011-09-19T09:56:06.298Z"),
text : "great book"
}
]
}](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-31-320.jpg)

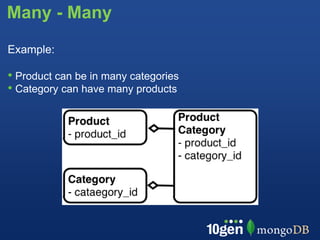
![Many - Many
// Each product list the IDs of the categories
products:
{ _id: 10, name: "Destination Moon",
category_ids: [ 20, 30 ] }](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-34-320.jpg)
![Many - Many
// Each product list the IDs of the categories
products:
{ _id: 10, name: "Destination Moon",
category_ids: [ 20, 30 ] }
// Each category lists the IDs of the products
categories:
{ _id: 20, name: "adventure",
product_ids: [ 10, 11, 12 ] }
categories:
{ _id: 21, name: "movie",
product_ids: [ 10 ] }](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-35-320.jpg)
![Many - Many
// Each product list the IDs of the categories
products:
{ _id: 10, name: "Destination Moon",
category_ids: [ 20, 30 ] }
// Each category lists the IDs of the products
categories:
{ _id: 20, name: "adventure",
product_ids: [ 10, 11, 12 ] }
categories:
{ _id: 21, name: "movie",
product_ids: [ 10 ] }
Cuts mapping table and 2 indexes, but:
• potential consistency issue
• lists can grow too large](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-36-320.jpg)
![Alternative
// Each product list the IDs of the categories
products:
{ _id: 10, name: "Destination Moon",
category_ids: [ 20, 30 ] }
// Association not stored on the categories
categories:
{ _id: 20,
name: "adventure"}](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-37-320.jpg)
![Alternative
// Each product list the IDs of the categories
products:
{ _id: 10, name: "Destination Moon",
category_ids: [ 20, 30 ] }
// Association not stored on the categories
categories:
{ _id: 20,
name: "adventure"}
// All products for a given category
> db.products.ensureIndex( { category_ids: 1} ) // yes!
> db.products.find( { category_ids: 20 } )](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-38-320.jpg)

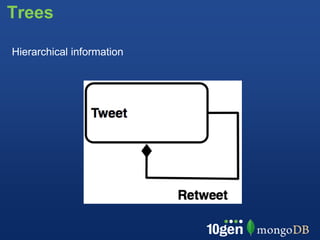
![Trees
Full Tree in Document
{ retweet: [
{ who: “Kyle”, text: “...”,
retweet: [
{who: “James”, text: “...”,
retweet: []}
]}
]
}
Pros: Single Document, Performance, Intuitive
Cons: Hard to search or update, document can easily get
too large](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-41-320.jpg)
![Array of Ancestors A B C
// Store all Ancestors of a node E D
{ _id: "a" }
{ _id: "b", tree: [ "a" ], retweet: "a" } F
{ _id: "c", tree: [ "a", "b" ], retweet: "b" }
{ _id: "d", tree: [ "a", "b" ], retweet: "b" }
{ _id: "e", tree: [ "a" ], retweet: "a" }
{ _id: "f", tree: [ "a", "e" ], retweet: "e" }
// find all direct retweets of "b"
> db.tweets.find( { retweet: "b" } )](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-42-320.jpg)
![Array of Ancestors A B C
// Store all Ancestors of a node E D
{ _id: "a" }
{ _id: "b", tree: [ "a" ], retweet: "a" } F
{ _id: "c", tree: [ "a", "b" ], retweet: "b" }
{ _id: "d", tree: [ "a", "b" ], retweet: "b" }
{ _id: "e", tree: [ "a" ], retweet: "a" }
{ _id: "f", tree: [ "a", "e" ], retweet: "e" }
// find all direct retweets of "b"
> db.tweets.find( { retweet: "b" } )
// find all retweets of "e" anywhere in tree
> db.tweets.find( { tree: "e" } )](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-43-320.jpg)
![Array of Ancestors A B C
// Store all Ancestors of a node E D
{ _id: "a" }
{ _id: "b", tree: [ "a" ], retweet: "a" } F
{ _id: "c", tree: [ "a", "b" ], retweet: "b" }
{ _id: "d", tree: [ "a", "b" ], retweet: "b" }
{ _id: "e", tree: [ "a" ], retweet: "a" }
{ _id: "f", tree: [ "a", "e" ], retweet: "e" }
// find all direct retweets of "b"
> db.tweets.find( { retweet: "b" } )
// find all retweets of "e" anywhere in tree
> db.tweets.find( { tree: "e" } )
// find tweet history of f:
> tweets = db.tweets.findOne( { _id: "f" } ).tree
> db.tweets.find( { _id: { $in : tweets } } )](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-44-320.jpg)
![Trees as Paths A B C
Store hierarchy as a path expression E D
• Separate each node by a delimiter, e.g. “,”
• Use text search for find parts of a tree F
• search must be left-rooted and use an index!
{ retweets: [
{ _id: "a", text: "initial tweet",
path: "a" },
{ _id: "b", text: "reweet with comment",
path: "a,b" },
{ _id: "c", text: "reply to retweet",
path : "a,b,c"} ] }
// Find the conversations "a" started
> db.tweets.find( { path: /^a/ } )
// Find the conversations under a branch
> db.tweets.find( { path: /^a,b/ } )](https://image.slidesharecdn.com/10genpresentsschemadesignanddatamodeling-121220191337-phpapp02/85/10gen-Presents-Schema-Design-and-Data-Modeling-45-320.jpg)










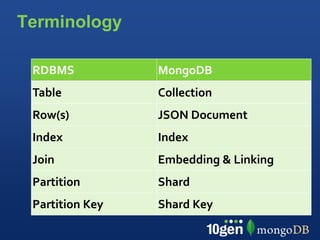
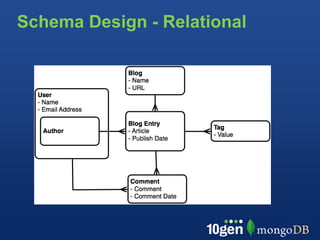
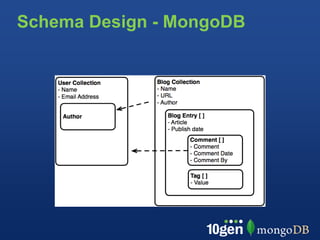
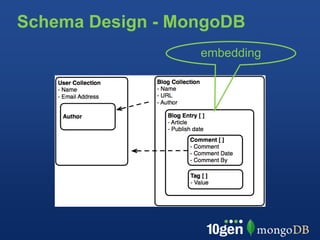
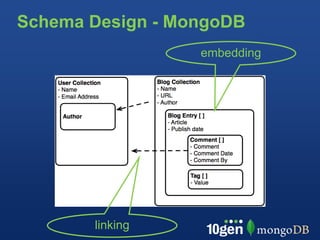
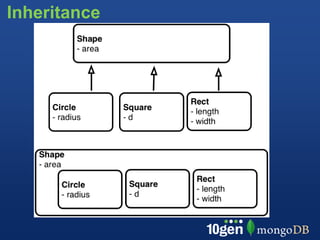
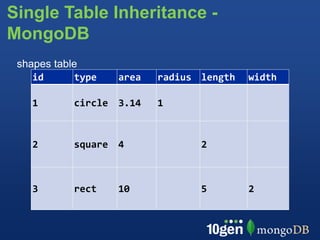
This document provides an overview of schema design in MongoDB. It discusses topics such as: - The goals of schema design, which include avoiding anomalies, minimizing redesign, avoiding query bias, and making use of features. - Key terminology when comparing MongoDB to relational databases, such as using collections instead of tables and embedding/linking instead of joins. - Examples of basic collections, documents, indexing, and query operators. - Common schema patterns for MongoDB like embedding, normalization, inheritance, one-to-many, many-to-many, and trees. - Use cases like time series are also briefly covered.






















































































