Download to read offline













![{
name: ‘Mongo DB‘,
signification: 'humongous',
fr: ‘enorme',
Release : ‘MongoV3,1'
}
{
name: ‘NoSQL meeting ',
date: ISODate("2016-10-08T09:00:00.382Z"),
speakers: [
{ name: ‘Speacker1' },
{ name: ‘Speacker2’ }
]
}
No schema](https://image.slidesharecdn.com/mongo-161014232520/85/Introduction-to-MongoDB-17-320.jpg)



![{ id: ’doc1’,
name: ‘Mongo DB‘,
signification: 'humongous',
fr: ‘enorme',
Release : ‘MongoV3,1'
}
{ _id:’doc2’,
name: ‘NoSQL meeting ',
date: ISODate("2016-10-08T09:00:00.382Z"),
speakers: [
{ name: ‘Speacker1' },
{ name: ‘Speacker2’ }
],
programme:{
name: ‘Mongo DB‘,
signification: 'humongous',
fr: ‘enorme',
Release : ‘MongoV3,1'
}
}](https://image.slidesharecdn.com/mongo-161014232520/85/Introduction-to-MongoDB-23-320.jpg)

![{ _id:ObjectId(‘xxxxxxxxxxxxxxxxx’),
name: ‘NoSQL meeting ',
date: ISODate("2016-10-08T09:00:00.382Z"),
speakers: [
{ name: ‘Speacker1' },
{ name: ‘Speacker2’ }
],
programme:{
_id:ObjectId(‘yyyyyyyyyyyy’),
name: ‘Mongo DB‘,
signification: 'humongous',
fr: ‘enorme',
Release : ‘MongoV3,1'
}
}](https://image.slidesharecdn.com/mongo-161014232520/85/Introduction-to-MongoDB-26-320.jpg)
![{ _id:ObjectId(‘xxxxxxxxxxxxxxxxx’),
name: ‘NoSQL meeting ',
date: ISODate("2016-10-08T09:00:00.382Z"),
speakers: [
{ name: ‘Speacker1' },
{ name: ‘Speacker2’ }
],
programmeid:{ObjectId(‘yyyyyyyyyyyy’),}
}
{
_id:ObjectId(‘yyyyyyyyyyyy’),
name: ‘Mongo DB‘,
signification: 'humongous',
fr: ‘enorme',
Release : ‘MongoV3,1'
}](https://image.slidesharecdn.com/mongo-161014232520/85/Introduction-to-MongoDB-27-320.jpg)
![{ _id:ObjectId(‘xxxxxxxxxxxxxxxxx’),
name: ‘NoSQL meeting ',
date: ISODate("2016-10-08T09:00:00.382Z"),
speakers: [
{ name: ‘Speacker1' },
{ name: ‘Speacker2’ }
],
programmeid:
{ "$ref" : "creators",
"$id" : ObjectId("5126bc054aed4daf9),
"$db" : "users"
}
}
{_id:ObjectId(‘5126bc054aed4daf9’),
name: ‘Mongo DB‘,
signification: 'humongous',
fr: ‘enorme',
Release : ‘MongoV3,1'
}
Collection : creators
Db : Users](https://image.slidesharecdn.com/mongo-161014232520/85/Introduction-to-MongoDB-28-320.jpg)






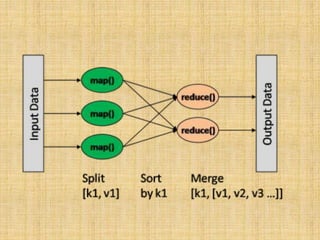





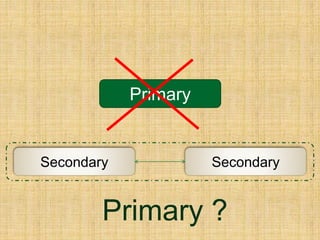
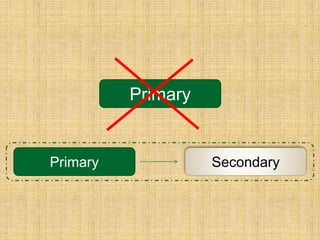
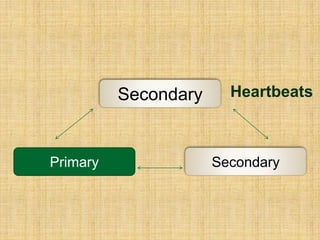





The document discusses various aspects of MongoDB and NoSQL databases, including their architectures and features. It includes information about MongoDB's documentation, a NoSQL meeting with scheduled speakers, and best practices for using the database. Additionally, it covers topics like BSON object IDs, indexed fields, and the use of map-reduce functions for data analysis.



























































































