Download to read offline













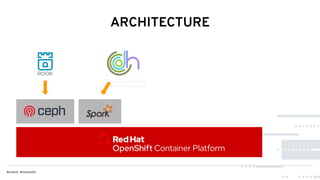
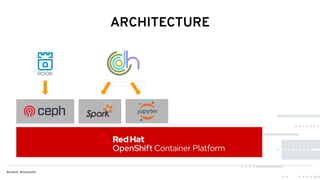
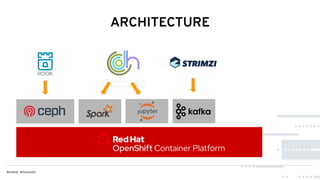
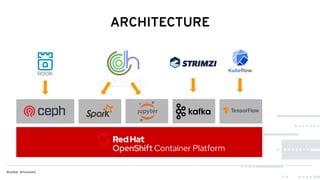


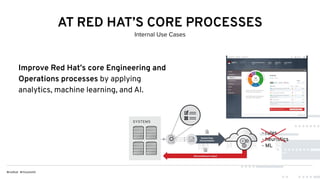


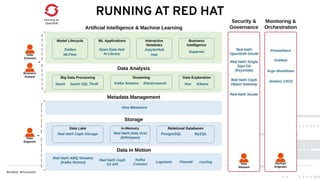
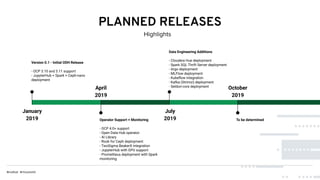





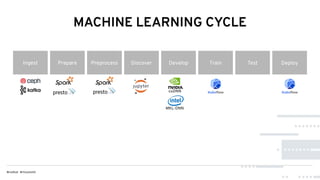

This document discusses Red Hat's Open Data Hub platform for multi-tenant data analytics and machine learning. It describes the challenges of sharing data and compute resources across teams and the Open Data Hub architecture which allows teams to spin up and down their own compute clusters while sharing a common data store. Key elements of the Open Data Hub include Spark, Ceph storage, JupyterHub notebooks, and TensorFlow/Keras for modeling. The document provides an overview of data structures, analytics workflows, and the components and roadmap for the Open Data Hub platform.






























































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



