Downloaded 56 times

















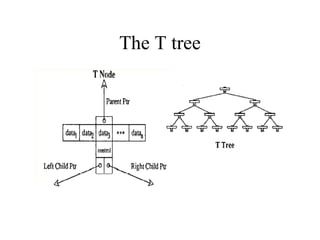





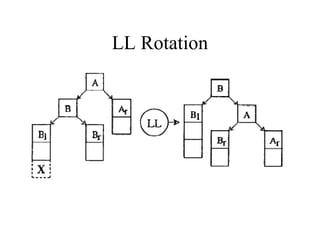
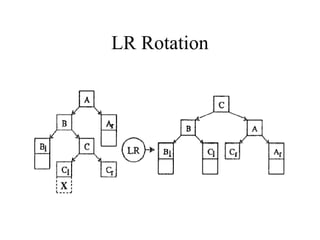
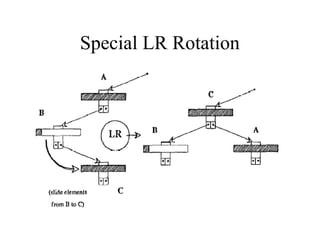












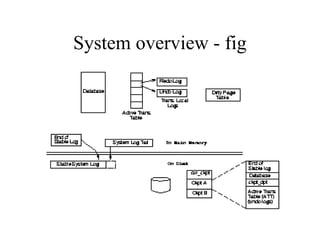

























Main Memory database systems store data primarily in main memory for faster access compared to disk-based systems. The T tree is proposed as an index structure for main memory databases that provides fast search, insert and delete performance while using relatively little memory space. The Dali storage manager is designed for main memory databases and provides persistence, availability and recovery guarantees similar to disk-based databases through the use of logging, locking, checkpointing and other techniques while leveraging the speed of main memory.














































![[Www.pkbulk.blogspot.com]file and indexing](https://cdn.slidesharecdn.com/ss_thumbnails/www-pkbul-blogspot-comfileandindexing-130615034648-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












