Download as PDF, PPTX






![Key Value store
• Stores values that are indexed by a key usually built on a hash or tree data-
structure
• No predefined schema needed
• Often used for in-memory quick lookup
• Pro: no or minimal overhead of RDBMS necessary, great for unstructured or semi-
structured data related to one single object (shopping cart, social media) examples:
Berkeley DB (Oracle), open LDAP
• Con: limited functionality
void Put(string key, byte[] data); byte[] Get(string key); void Remove(string key);
Simple API can hide very
complex implementation.
Why?](https://image.slidesharecdn.com/databasetechnologiespublic-180324110312/85/Database-Technologies-13-320.jpg)

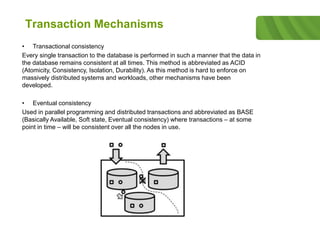
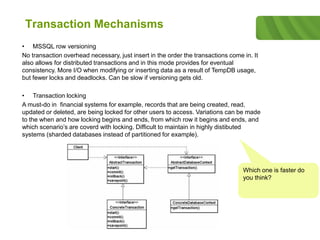


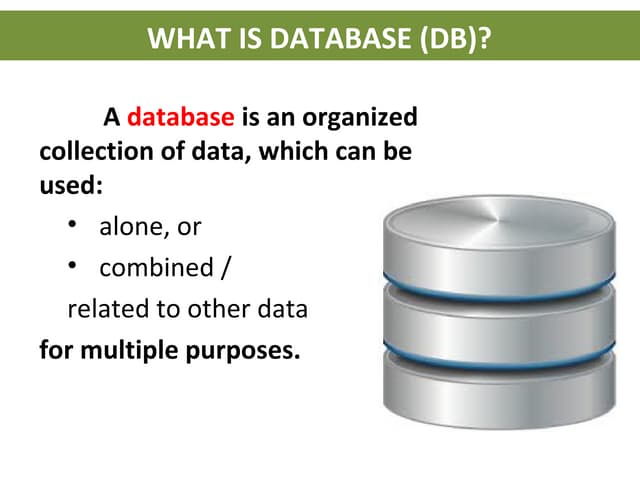
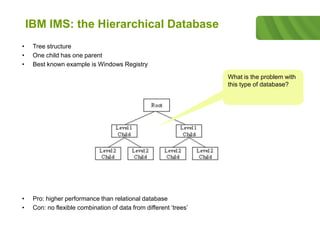
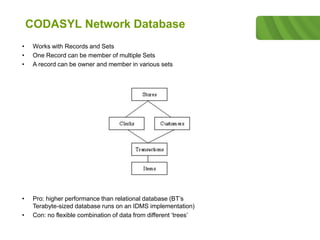
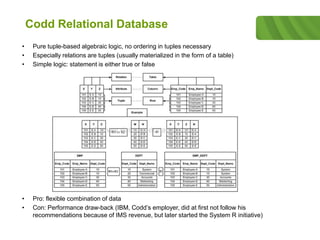
The document outlines the historical development of database technologies, starting from the formation of CODASYL in 1959 and the introduction of various database models, including hierarchical, network, and relational databases. It discusses advantages and disadvantages of each type, leading to the emergence of NoSQL databases designed for handling large amounts of data with a focus on scalability and fast retrieval. Various NoSQL database types are described, including key-value stores, document stores, and column stores, highlighting their unique features and use cases.