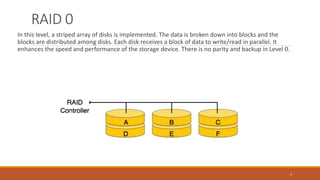
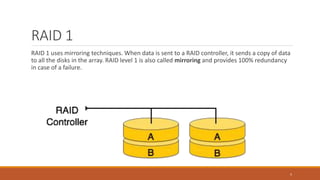
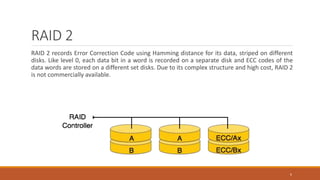
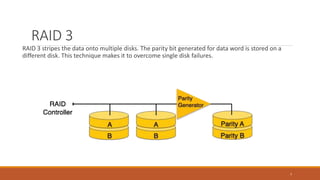
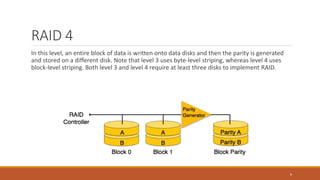
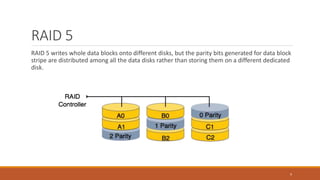
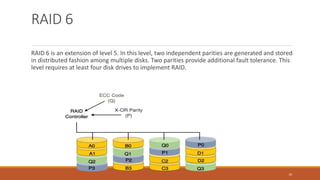
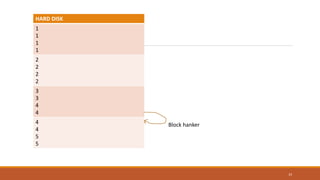
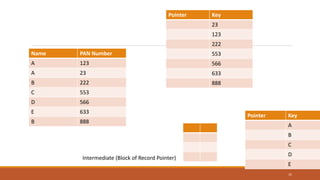
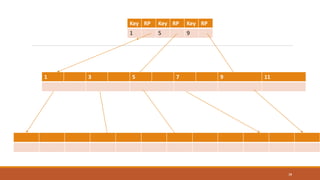
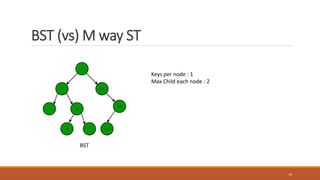
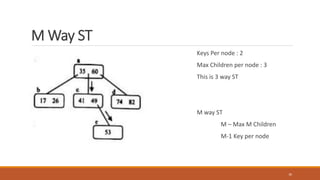
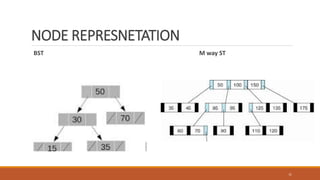
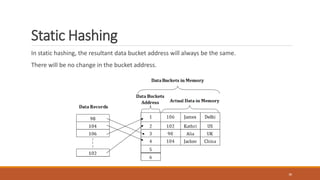
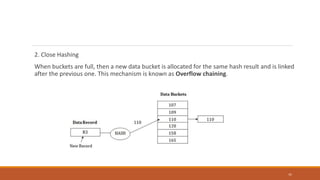
This document provides an overview of various data storage and querying techniques including RAID configurations, file organization methods, indexing, hashing, and query processing. It describes RAID levels 0 through 6, common file organizations like heap, sequential, hash, and clustered, and indexing using primary, clustered, and secondary indexes. Ordered and unordered indices are discussed along with B-tree and B+-tree structures. The document also covers static and dynamic hashing techniques as well as query optimization.