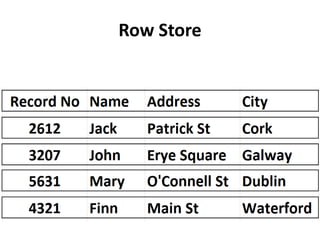
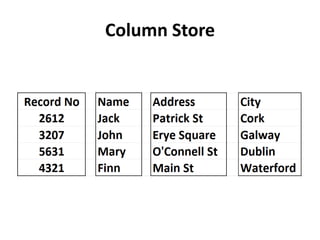
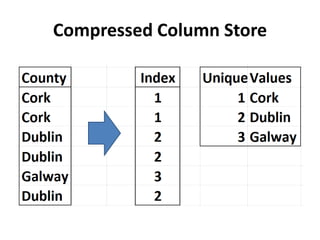
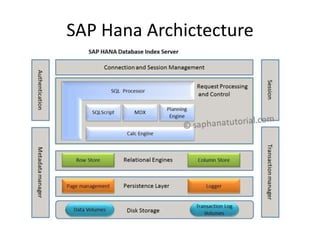
This document provides an overview of in-memory databases, summarizing different types including row stores, column stores, compressed column stores, and how specific databases like SQLite, Excel, Tableau, Qlik, MonetDB, SQL Server, Oracle, SAP Hana, MemSQL, and others approach in-memory storage. It also discusses hardware considerations like GPUs, FPGAs, and new memory technologies that could enhance in-memory database performance.



















![Initial Version
• InMemoryColumn<T> {
Dictionary <T,int> initialValuesDict;
List <int> initialIndexes;
T [] finalValues;
int [] finalIndexes;
• }](https://image.slidesharecdn.com/inmemorydatabasespresentation-160308194829/85/In-memory-databases-presentation-24-320.jpg)
![Next Version
• InMemoryColumn<T> {
Dictionary <T,int> initialValuesDict;
int [][] initialIndexes;
T [] finalValues;
int [] finalIndexes;
• }](https://image.slidesharecdn.com/inmemorydatabasespresentation-160308194829/85/In-memory-databases-presentation-25-320.jpg)
![Final Version
• InMemoryColumn<T> {
Dictionary <T,int> initialValuesDict;
byte/ushort/int [][] initialIndexes;
T [] finalValues;
byte/ushort/int [] finalIndexes;
• }](https://image.slidesharecdn.com/inmemorydatabasespresentation-160308194829/85/In-memory-databases-presentation-26-320.jpg)
![ANLTR to Parse Queries
grammar Expr;
prog: (expr NEWLINE)* ;
expr: expr ('*'|'/') expr |
expr ('+'|'-') expr |
INT | '(' expr ')' ;
NEWLINE : [rn]+ ;
INT : [0-9]+ ;](https://image.slidesharecdn.com/inmemorydatabasespresentation-160308194829/85/In-memory-databases-presentation-27-320.jpg)
![Example Rule from Grammer
mainquery [ImpVars vars] returns [InMemoryQuery query ] :
{ $query = new InMemoryQuery(); }
SELECT1
(CACHE {$query.setCache();} )?
(NOCACHE {$query.setNoCache();} )?
(DISTINCT {$query.setDistinct();} )?
fieldclause [$query,$vars]
(
(INTO label { $query.setInto ($label.text2 ) ;})?
FROM tableclause [$query,$vars]
( (COMMA|CROSS JOIN ) tableclause [$query,$vars] ) *
(WHERE whereclause [$query,$vars])?
(GROUP BY groupclause [$query,$vars])?
(HAVING havingclause [$query,$vars])?
(ORDER BY orderclause [$query,$vars])?
(LIMIT limitclause [$query,$vars])?
)? ;](https://image.slidesharecdn.com/inmemorydatabasespresentation-160308194829/85/In-memory-databases-presentation-28-320.jpg)


![SELECT customerid FROM Orders
for (int tab1_counter = rowStart; tab1_counter < rowEnd; tab1_counter++,)
{ groupRowD1 = groupRowCount >> 14;
groupRowD2 = groupRowCount & 16383;
if (groupRowD2 == 0)
{
if (groupRowD1 > 0)
{
blockCounts[groupRowD1 - 1] = 16384;
}
lock (lock_newBlockObject)
{
groupRowCount = nextRecordD1 << 14;
nextRecordD1++;
}
groupRowD1 = groupRowCount >> 14;
t_total0[groupRowD1] = new byte[16384];
total0 = t_total0[groupRowD1];
};
total0[groupRowD2] = val_t1_c1[tab1_counter];
groupRowCount++;
if ((groupRowCount & 16383) == 0)
{
blockCounts[groupRowD1] = 16384;
}
}](https://image.slidesharecdn.com/inmemorydatabasespresentation-160308194829/85/In-memory-databases-presentation-31-320.jpg)

![SELECT customer, SUM(1) FROM orders
WHERE employee=1 GROUP BY customer
for (int tab1_counter = rowStart; tab1_counter < rowEnd;
tab1_counter++, newRow = false) {
if ((val_t1_c2[tab1_counter] == const_0_t1_c2)) {
rowIndex = val_t1_c1[tab1_counter];
if (groupRowExists[rowIndex] == 0) newRow = true;
groupRowExists[rowIndex] = 1;
total1[rowIndex] += const_0;
if (newRow) {
total0[rowIndex]=val_t1_c1[tab1_counter];
}
}
}](https://image.slidesharecdn.com/inmemorydatabasespresentation-160308194829/85/In-memory-databases-presentation-33-320.jpg)
![COUNT DISTINCT
• Initial Algorithm used Byte []
• Used lots of Memory on Large Cores
• Upgraded to 1 [] across all Cores
• Interlocked.CompareExchange to set Bit
• Hashmap for initial Values
• Then switch to byte []](https://image.slidesharecdn.com/inmemorydatabasespresentation-160308194829/85/In-memory-databases-presentation-34-320.jpg)



































































































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)

