Downloaded 176 times







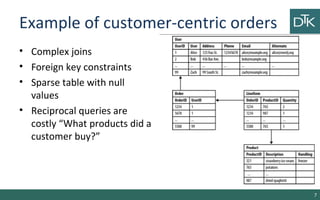

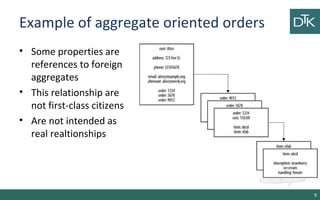
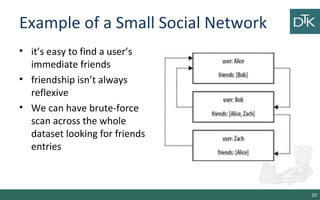

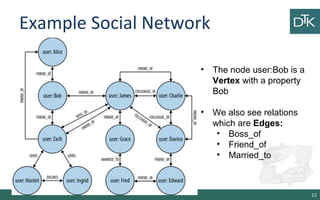








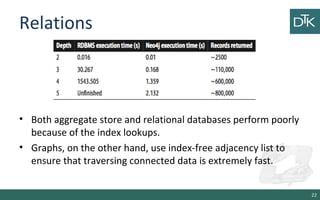
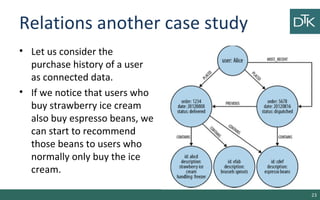














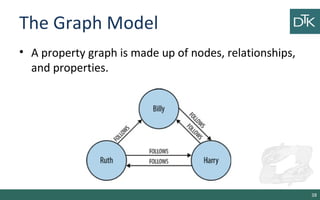
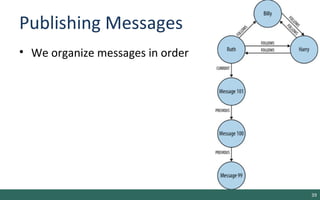






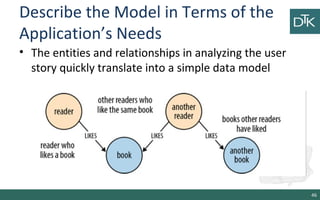



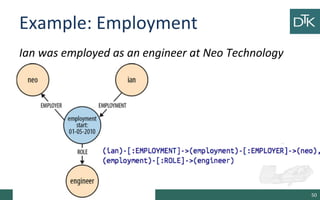
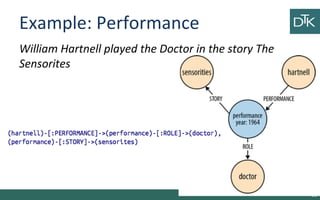
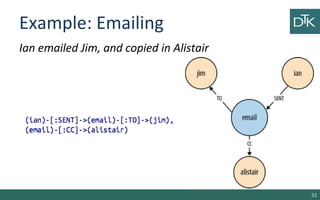
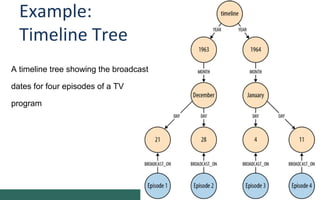
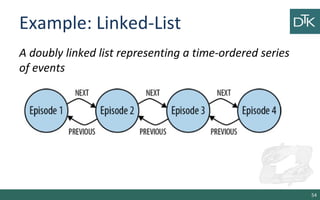












The document discusses graph-oriented databases, highlighting their advantages over relational databases (RDBMS) and NoSQL databases, particularly in modeling and managing relationships among data. It covers topics such as the structure of graph databases, their query languages, and data modeling techniques, emphasizing the importance of connections and efficient traversal. The conclusion suggests that graph databases are ideal for connected data use cases, such as recommendation engines and location-based services.
































































































