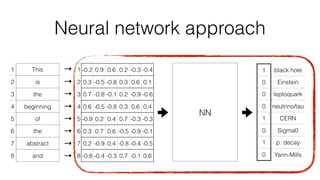
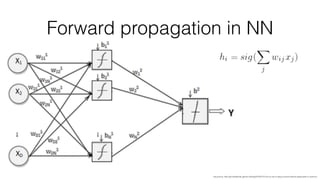
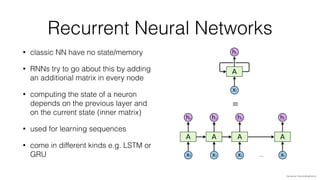
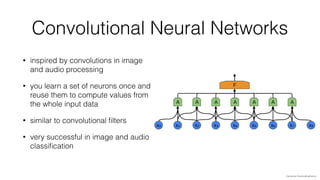
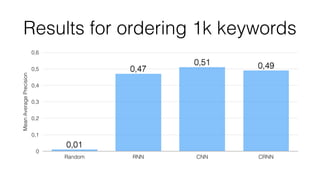
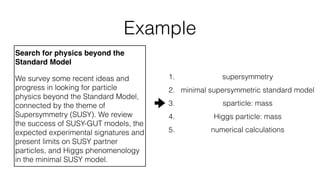
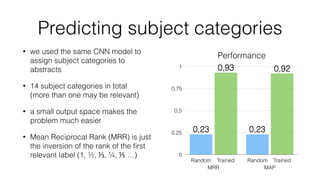
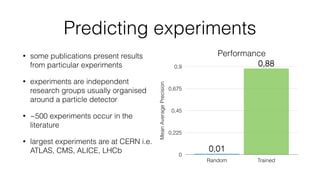
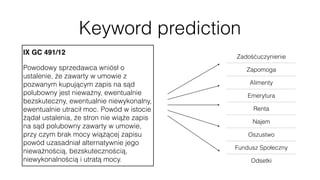
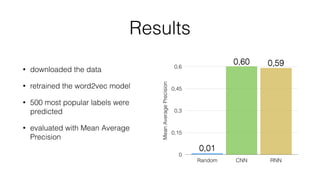
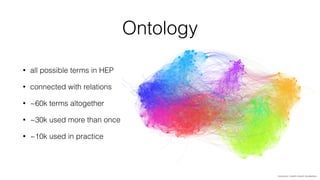
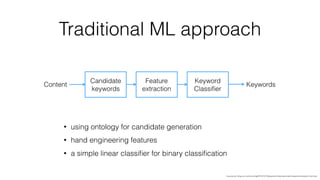
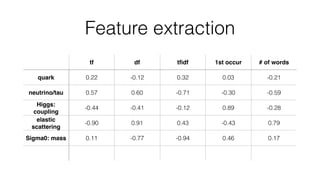
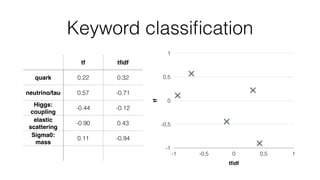
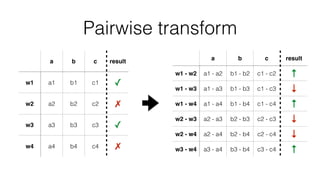
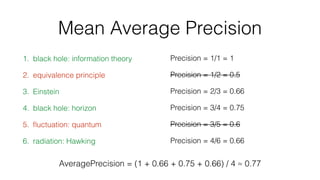
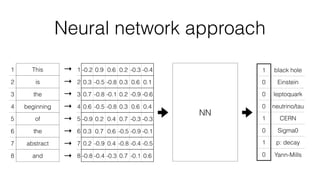
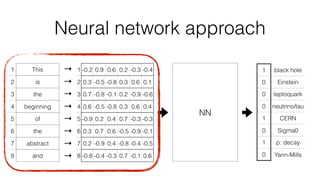
Jan Stypka presented an outline for a talk on extracting keywords from high energy physics publication abstracts. The initial approach involved using an ontology to generate candidate keywords and hand-engineering features for a linear classifier, but this achieved only 30% mean average precision. A neural network approach using word embeddings skipped the candidate generation and feature engineering steps and achieved 47-51% mean average precision, demonstrating an improvement over the traditional machine learning method. The presentation included examples of keyword rankings produced by different neural network models.
















![Word vectors
• we need to represent the meaning of the words
• we want to perform arithmetics e.g. vec[“hotel”] - vec[“motel”] ≈ 0
• we want them to be low-dimensional
• we want them to preserve relations
e.g. vec[“Paris”] - vec[“France”] ≈ vec[“Berlin”] - vec[“Germany”]
• vec[“king”] - vec[“man”] + vec[“woman”] ≈ vec[“queen”]](https://image.slidesharecdn.com/magpie-datakrk-160628090208/85/Magpie-26-320.jpg)