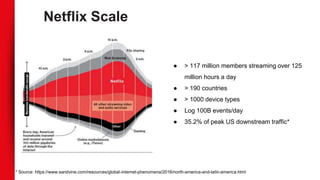
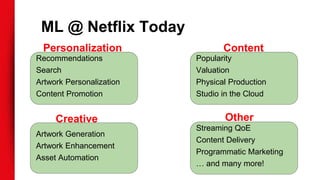
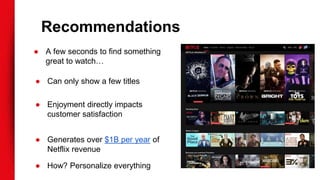
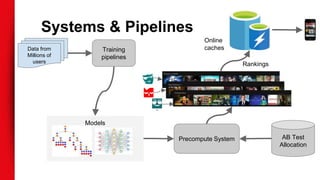
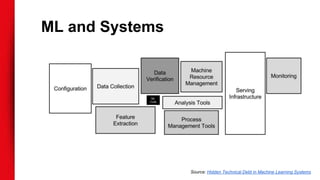
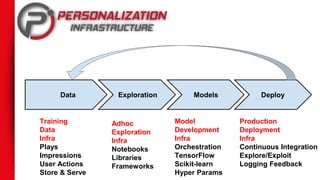
The document discusses Netflix's extensive use of machine learning for personalized recommendations, which plays a crucial role in enhancing customer satisfaction and generates significant revenue. It highlights the scale of Netflix’s operations, involving over 117 million members and data from 100 billion events daily, as well as the technical infrastructure required for efficient machine learning processes. Key takeaways emphasize the importance of solid infrastructure, investment in software best practices, and the ability to personalize the viewing experience for users.