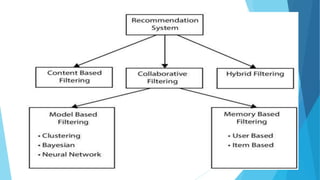
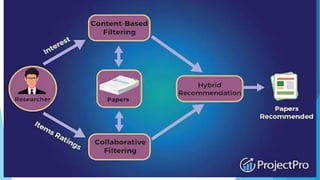
This document provides an overview of machine learning using Python. It introduces machine learning applications and key Python concepts for machine learning like data types, variables, strings, dates, conditional statements, loops, and common machine learning libraries like NumPy, Matplotlib, and Pandas. It also covers important machine learning topics like statistics, probability, algorithms like linear regression, logistic regression, KNN, Naive Bayes, and clustering. It distinguishes between supervised and unsupervised learning, and highlights algorithm types like regression, classification, decision trees, and dimensionality reduction techniques. Finally, it provides examples of potential machine learning projects.




![STRINGS:
string is a sequence of characters . It is an immutable
sequence data type.
Ex:
var1 = 'Hello World!’
var2 = "Python Programming"
Accessing Values in Strings:
To access substrings, use the square brackets for slicing along with the
index or indices to obtain your substring.
EX:
var1 = 'Hello World!’
var2 = "Python Programming"
var1 [0] : H
var2 [1:5] : ytho
String Concatenation :
we can join two or more strings using + operator
var1=‘hello’
var2=‘world’
var3=var1+” “+var2
var3 hello world](https://image.slidesharecdn.com/finalmlppt-230126173021-8ab39fd6/85/fINAL-ML-PPT-pptx-5-320.jpg)





![LOOPS IN PYTHON:
We can run a single statement or set of statements repeatedly using a
loop command.
TYPES:
for , while , nested loops.
for loop:
A for loop is used for iterating over a
sequence (that is either a list, a tuple, a
dictionary, a set, or a string).
Ex:
fruits=["a", "b", "c"]
for x in fruits:
print(x)
Output:
a
b
c
while loop
With the while loop we can execute a set of statements
as long as a condition is true.
Ex:
i = 1
while i < 4:
print(i)
i += 1
Output:
1
2
3](https://image.slidesharecdn.com/finalmlppt-230126173021-8ab39fd6/85/fINAL-ML-PPT-pptx-11-320.jpg)
![LIST:
List is used to store data of different data types in a sequential manner. There are addresses assigned to
every element of the list, which is called as Index
EX:
my_list = [1, 2, 3, 'example', 3.132]
TUPLE:
A tuple is created by placing all the items (elements) inside parentheses () , separated by commas. It is
immutable.
EX:
my_tuple = (1, "Hello", 3.4)
DICTIONARY:
Dictionaries are used to store key-value pairs.
EX:
my_dict = {1: 'Python', 2: 'Java’}
SET:
Sets are a collection of unordered elements that are unique. Meaning that even if the data is repeated
more than one time, it would be entered into the set only once.
EX:
my_set = {1, 2, 3, 4, 5, 5, 5}](https://image.slidesharecdn.com/finalmlppt-230126173021-8ab39fd6/85/fINAL-ML-PPT-pptx-12-320.jpg)