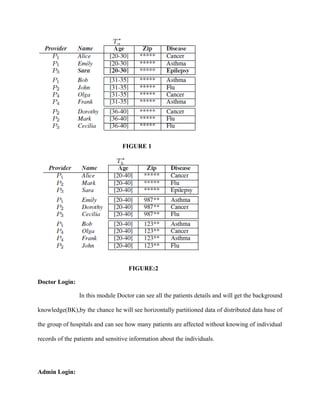
The document discusses collaborative data publishing and the introduction of 'm-privacy' to protect against insider attacks from colluding data providers. It presents heuristic algorithms for ensuring m-privacy while maintaining data utility and outlines a new provider-aware anonymization algorithm. The findings demonstrate improved utility and efficiency compared to existing algorithms, although several research questions remain for further exploration.