Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
TY
Uploaded by
Tanaka Yuichi
PPTX, PDF
3,734 views
PythonでDeepLearningを始めるよ
PythonでDeepLearningの仕組みを見ていきます。
Technology
◦
Read more
6
Save
Share
Embed
Embed presentation
Download
Downloaded 167 times
1
/ 32
2
/ 32
3
/ 32
4
/ 32
5
/ 32
6
/ 32
7
/ 32
8
/ 32
9
/ 32
10
/ 32
11
/ 32
12
/ 32
13
/ 32
14
/ 32
15
/ 32
16
/ 32
17
/ 32
18
/ 32
19
/ 32
20
/ 32
21
/ 32
22
/ 32
23
/ 32
24
/ 32
25
/ 32
26
/ 32
27
/ 32
28
/ 32
29
/ 32
30
/ 32
31
/ 32
32
/ 32
More Related Content
PPTX
Bluemixを使ったTwitter分析
by
Tanaka Yuichi
PPTX
SparkとJupyterNotebookを使った分析処理 [Html5 conference]
by
Tanaka Yuichi
PPTX
Apache Sparkを使った感情極性分析
by
Tanaka Yuichi
PPTX
Big datauniversity
by
Tanaka Yuichi
PPTX
BigDataUnivercity 2017年改めてApache Sparkとデータサイエンスの関係についてのまとめ
by
Tanaka Yuichi
PPTX
Watson summit 2016_j2_5
by
Tanaka Yuichi
PPTX
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
by
Tanaka Yuichi
PPTX
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜
by
Tanaka Yuichi
Bluemixを使ったTwitter分析
by
Tanaka Yuichi
SparkとJupyterNotebookを使った分析処理 [Html5 conference]
by
Tanaka Yuichi
Apache Sparkを使った感情極性分析
by
Tanaka Yuichi
Big datauniversity
by
Tanaka Yuichi
BigDataUnivercity 2017年改めてApache Sparkとデータサイエンスの関係についてのまとめ
by
Tanaka Yuichi
Watson summit 2016_j2_5
by
Tanaka Yuichi
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
by
Tanaka Yuichi
初めてのSpark streaming 〜kafka+sparkstreamingの紹介〜
by
Tanaka Yuichi
What's hot
PPTX
Jjug ccc
by
Tanaka Yuichi
PPTX
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
by
Tanaka Yuichi
PPTX
Pysparkで始めるデータ分析
by
Tanaka Yuichi
PPSX
HBaseとSparkでセンサーデータを有効活用 #hbasejp
by
FwardNetwork
PPTX
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
PPTX
Spark GraphX で始めるグラフ解析
by
Yosuke Mizutani
PDF
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Sparkの紹介
by
Ryuji Tamagawa
PDF
20160127三木会 RDB経験者のためのspark
by
Ryuji Tamagawa
PDF
本当にあったApache Spark障害の話
by
x1 ichi
PPTX
Apache cassandraと apache sparkで作るデータ解析プラットフォーム
by
Kazutaka Tomita
PDF
SparkやBigQueryなどを用いた モバイルゲーム分析環境
by
yuichi_komatsu
PDF
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
PDF
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
PPTX
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
PDF
ゼロから始めるSparkSQL徹底活用!
by
Nagato Kasaki
PDF
QConTokyo2015「Sparkを用いたビッグデータ解析 〜後編〜」
by
Kazuki Taniguchi
PDF
Apache Sparkについて
by
BrainPad Inc.
PDF
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
Jjug ccc
by
Tanaka Yuichi
Devsumi 2016 b_4 KafkaとSparkを組み合わせたリアルタイム分析基盤の構築
by
Tanaka Yuichi
Pysparkで始めるデータ分析
by
Tanaka Yuichi
HBaseとSparkでセンサーデータを有効活用 #hbasejp
by
FwardNetwork
Pythonで入門するApache Spark at PyCon2016
by
Tatsuya Atsumi
Spark GraphX で始めるグラフ解析
by
Yosuke Mizutani
Spark Streamingを活用したシステムの検証結果と設計時のノウハウ
by
Future Of Data Japan
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Sparkの紹介
by
Ryuji Tamagawa
20160127三木会 RDB経験者のためのspark
by
Ryuji Tamagawa
本当にあったApache Spark障害の話
by
x1 ichi
Apache cassandraと apache sparkで作るデータ解析プラットフォーム
by
Kazutaka Tomita
SparkやBigQueryなどを用いた モバイルゲーム分析環境
by
yuichi_komatsu
1000台規模のHadoopクラスタをHive/Tezアプリケーションにあわせてパフォーマンスチューニングした話
by
Yahoo!デベロッパーネットワーク
Sparkのクエリ処理系と周辺の話題
by
Takeshi Yamamuro
Kafkaを活用するためのストリーム処理の基本
by
Sotaro Kimura
ゼロから始めるSparkSQL徹底活用!
by
Nagato Kasaki
QConTokyo2015「Sparkを用いたビッグデータ解析 〜後編〜」
by
Kazuki Taniguchi
Apache Sparkについて
by
BrainPad Inc.
Spark勉強会_ibm_20151014-公開版
by
Atsushi Tsuchiya
Similar to PythonでDeepLearningを始めるよ
PDF
Deep learning実装の基礎と実践
by
Seiya Tokui
PDF
TensorFlow White Paperを読む
by
Yuta Kashino
PDF
これから始める人のためのディープラーニング基礎講座
by
NVIDIA Japan
PPTX
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
PDF
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
PPTX
深層学習の基礎と導入
by
Kazuki Motohashi
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
PPTX
Azure Machine Learning Services 概要 - 2019年2月版
by
Daiyu Hatakeyama
PPTX
深層学習入門 スライド
by
swamp Sawa
PPTX
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
PDF
Deep learning Libs @twm
by
Yuta Kashino
PDF
「深層学習」勉強会LT資料 "Chainer使ってみた"
by
Ken'ichi Matsui
PDF
Chainerの使い方と自然言語処理への応用
by
Seiya Tokui
PPTX
Machine Learning Fundamentals IEEE
by
Antonio Tejero de Pablos
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PPTX
1028 TECH & BRIDGE MEETING
by
健司 亀本
PPTX
Jupyter NotebookとChainerで楽々Deep Learning
by
Jun-ya Norimatsu
PDF
dl-with-python01_handout
by
Shin Asakawa
PDF
lispmeetup#63 Common Lispでゼロから作るDeep Learning
by
Satoshi imai
PPTX
Using Deep Learning for Recommendation
by
Eduardo Gonzalez
Deep learning実装の基礎と実践
by
Seiya Tokui
TensorFlow White Paperを読む
by
Yuta Kashino
これから始める人のためのディープラーニング基礎講座
by
NVIDIA Japan
「機械学習とは?」から始める Deep learning実践入門
by
Hideto Masuoka
SGDによるDeepLearningの学習
by
Masashi (Jangsa) Kawaguchi
深層学習の基礎と導入
by
Kazuki Motohashi
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
Azure Machine Learning Services 概要 - 2019年2月版
by
Daiyu Hatakeyama
深層学習入門 スライド
by
swamp Sawa
機械学習 / Deep Learning 大全 (2) Deep Learning 基礎編
by
Daiyu Hatakeyama
Deep learning Libs @twm
by
Yuta Kashino
「深層学習」勉強会LT資料 "Chainer使ってみた"
by
Ken'ichi Matsui
Chainerの使い方と自然言語処理への応用
by
Seiya Tokui
Machine Learning Fundamentals IEEE
by
Antonio Tejero de Pablos
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
1028 TECH & BRIDGE MEETING
by
健司 亀本
Jupyter NotebookとChainerで楽々Deep Learning
by
Jun-ya Norimatsu
dl-with-python01_handout
by
Shin Asakawa
lispmeetup#63 Common Lispでゼロから作るDeep Learning
by
Satoshi imai
Using Deep Learning for Recommendation
by
Eduardo Gonzalez
PythonでDeepLearningを始めるよ
1.
© 2016 IBM
Corporation Pythonをつかってディープ・ラーニングの仕 組みを見ていくよ Tanaka Y.P 2016-10-18
2.
© 2016 IBM
Corporation2 お詫びと言い訳 (仮)Sparkで試してみるディープ・ラーニング 昨今、人工知能関連で最大の話題であるDeep Learningを、Apache Sparkを使って実装する方法について体験していただくハンズ・オン・セッ ションです。 Pythonをつかってディープ・ラーニングの仕組みを見ていくよ 昨今、人工知能関連で最大の話題であるDeep Learningを、Numpyを 使って実装する方法について体験していただくハンズ・オン・セッションで す。
3.
© 2016 IBM
Corporation3 自己紹介 田中裕一(yuichi tanaka) 主にアーキテクチャとサーバーサイドプログラムを担当 することが多い。Hadoop/Spark周りをよく触ります。 Node.js、Python、最近はSpark周りの仕事でScalaを書く ことが多い気がします。 休日はOSS周りで遊んだり。 詳解 Apache Spark
4.
© 2016 IBM
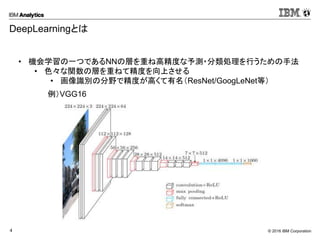
Corporation4 DeepLearningとは • 機会学習の一つであるNNの層を重ね高精度な予測・分類処理を行うための手法 • 色々な関数の層を重ねて精度を向上させる • 画像識別の分野で精度が高くて有名(ResNet/GoogLeNet等) 例)VGG16
5.
© 2016 IBM
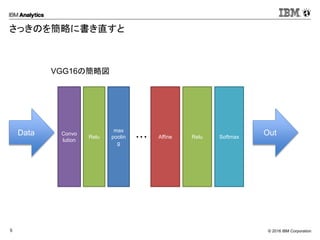
Corporation5 さっきのを簡略に書き直すと Data Convo lution Relu Affine Relu Softmax Out ・・・ max poolin g VGG16の簡略図
6.
© 2016 IBM
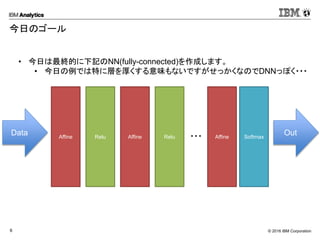
Corporation6 今日のゴール • 今日は最終的に下記のNN(fully-connected)を作成します。 • 今日の例では特に層を厚くする意味もないですがせっかくなのでDNNっぽく・・・ Data Affine Relu Affine Relu Softmax Out・・・ Affine
7.
© 2016 IBM
Corporation7 今日の範疇 今日の話の中で説明すること 背景的な話 DeepLearningの全体像 レイヤ フォワード • アフィン変換 活性化関数について • ReLU関数 出力層での正規化関数 • ソフトマックス関数 バックプロパゲーション 損失関数 誤差伝搬について ハイパーパラメータ
8.
© 2016 IBM
Corporation8 今日の範疇 今日の話の中で説明しないこと DeepLearningの種類的な違いとかの細かいこと 畳み込みニューラルネットワーク:CNN@触れる程度で 再帰ニューラルネットワーク:RNN 教師なし学習:GAN 強化学習:DQN 数式の話 『うぇ』ってなるので数式なしで 内積の話@アフィン変換 ネイピア数@ところどころ 各関数の詳細@特にバックプロパゲーションの関数 Batch Norm@各レイヤの値の分布調整 Dropoutについて@過学習とか
9.
© 2016 IBM
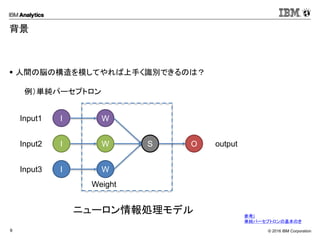
Corporation9 背景 人間の脳の構造を模してやれば上手く識別できるのは? ニューロン情報処理モデル 例)単純パーセプトロン I I I W W W S O Input1 Input2 Input3 output 参考) 単純パーセプトロンの基本のき Weight
10.
© 2016 IBM
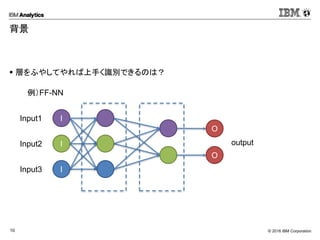
Corporation10 背景 層をふやしてやれば上手く識別できるのは? 例)FF-NN I I I Input1 Input2 Input3 output O O
11.
© 2016 IBM
Corporation11 今日のサンプル(色の識別:3つに分類) • 何色ですか? RGB(255,0,0) RGB(0,255,0) RGB(0,0,255) RGB(233,63,127) 赤 緑 青 赤
12.
© 2016 IBM
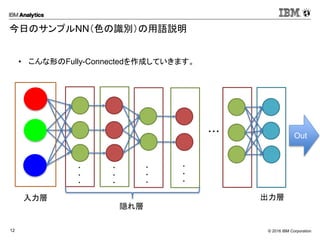
Corporation12 今日のサンプルNN(色の識別)の用語説明 • こんな形のFully-Connectedを作成していきます。 Out ・・・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ 入力層 隠れ層 出力層 Softmax
13.
© 2016 IBM
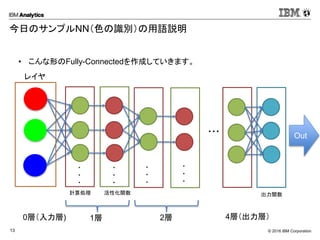
Corporation13 今日のサンプルNN(色の識別)の用語説明 • こんな形のFully-Connectedを作成していきます。 ・・・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ 0層(入力層) 1層 4層(出力層)2層 計算処理 活性化関数 出力関数 レイヤ Softmax Out
14.
© 2016 IBM
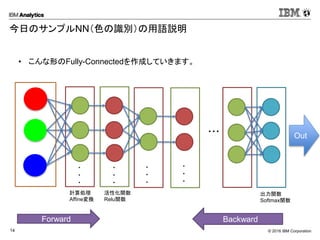
Corporation14 今日のサンプルNN(色の識別)の用語説明 • こんな形のFully-Connectedを作成していきます。 ・・・ Forward Backward ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ 計算処理 Affine変換 活性化関数 Relu関数 出力関数 Softmax関数 OutSoftmax
15.
© 2016 IBM
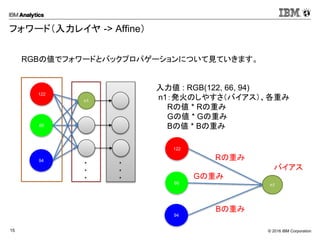
Corporation15 フォワード(入力レイヤ -> Affine) 122 66 94 n1 ・ ・ ・ ・ ・ ・ RGBの値でフォワードとバックプロパゲーションについて見ていきます。 入力値 : RGB(122, 66, 94) n1:発火のしやすさ(バイアス)、各重み Rの値 * Rの重み Gの値 * Gの重み Bの値 * Bの重み 122 66 94 n1 Rの重み Gの重み Bの重み バイアス
16.
© 2016 IBM
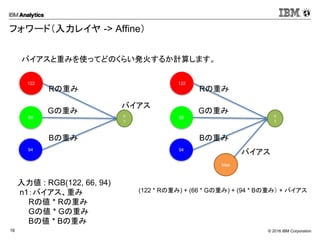
Corporation16 フォワード(入力レイヤ -> Affine) バイアスと重みを使ってどのくらい発火するか計算します。 入力値 : RGB(122, 66, 94) n1:バイアス、重み Rの値 * Rの重み Gの値 * Gの重み Bの値 * Bの重み 122 66 94 n 1 Rの重み Gの重み Bの重み 122 66 94 n 1 Rの重み Gの重み Bの重み bias バイアス バイアス (122 * Rの重み) + (66 * Gの重み) + (94 * Bの重み) + バイアス
17.
© 2016 IBM
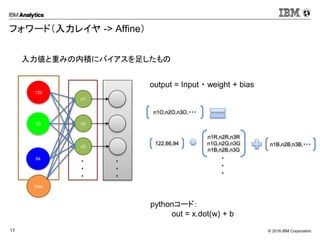
Corporation17 フォワード(入力レイヤ -> Affine) 入力値と重みの内積にバイアスを足したもの 122 66 94 n1 n2 n3 ・ ・ ・ ・ ・ ・ bias output = Input ・ weight + bias 122,66,94 n1R,n2R,n3R n1G,n2G,n3G n1B,n2B,n3G ・ ・ ・ n1B,n2B,n3B,・・・ pythonコード: out = x.dot(w) + b n1O,n2O,n3O,・・・
18.
© 2016 IBM
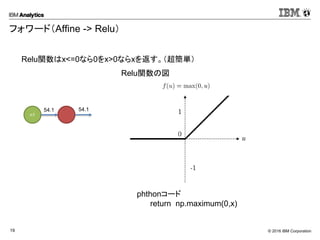
Corporation18 フォワード(Affine -> Relu) Affineの出力結果を活性化関数Reluを使って活性化させます ・ ・ ・ ・ ・ ・ ・ ・ ・ s1 = np.array([[122, 66, 94]]) w1 = np.array([[0.1], [0.2],[0.3]]) s1.dot(w1) + [0.5] [ 54.1] 例)Affineの重み・バイアスを決め打ちで計算 n1 54.1
19.
© 2016 IBM
Corporation19 フォワード(Affine -> Relu) Relu関数はx<=0なら0をx>0ならxを返す。(超簡単) Relu関数の図 n1 54.1 54.1 phthonコード return np.maximum(0,x)
20.
© 2016 IBM
Corporation20 フォワード(Affine -> 出力レイヤ) Softmax関数で最終値を扱いやすい形に変換 Softmax関数 pythonコード e = np.exp(x) sum_e = e.sum() return e / sum_e Softmax n1 n2 n3 出力例 [0, 0.1, 5.3] => [ 0.00493969, 0.0054592 , 0.98960111] 98%の確率で青と判定!
21.
© 2016 IBM
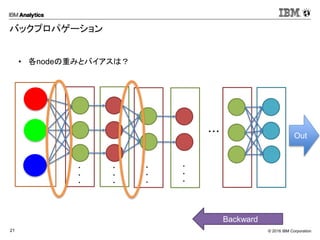
Corporation21 バックプロパゲーション • 各nodeの重みとバイアスは? ・・・ Backward ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ OutSoftmax
22.
© 2016 IBM
Corporation22 バックプロパゲーション(損失関数) • 各nodeの重みとバイアスは? ・・・ Backward ・ ・ ・ ・ ・ ・ OutSoftmax RGB(122, 66, 94) 教師Label [1,0,0] 初期値を当てる Forward 教師Label [1,0,0] 出力 [0.3,0.28,0.32] 損失関数 誤差修正 交差エントロピー誤差
23.
© 2016 IBM
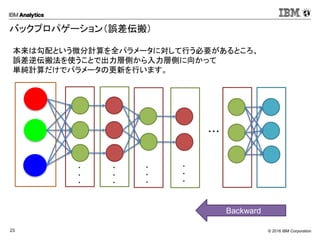
Corporation23 バックプロパゲーション(誤差伝搬) ・・・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ Softmax Backward 本来は勾配という微分計算を全パラメータに対して行う必要があるところ、 誤差逆伝搬法を使うことで出力層側から入力層側に向かって 単純計算だけでパラメータの更新を行います。
24.
© 2016 IBM
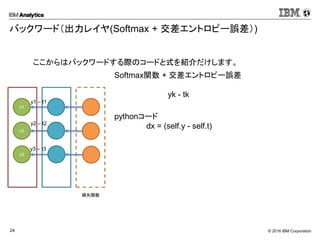
Corporation24 バックワード(出力レイヤ(Softmax + 交差エントロピー誤差)) Softmax関数 + 交差エントロピー誤差 yk - tk pythonコード dx = (self.y - self.t) Softmax n1 n2 n3 ここからはバックワードする際のコードと式を紹介だけします。 Softmax y1 – t1 y2 – t2 y3 – t3 損失関数
25.
© 2016 IBM
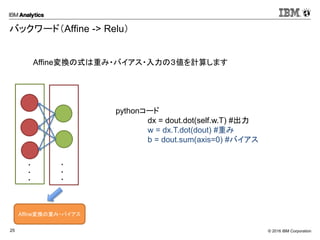
Corporation25 バックワード(Affine -> Relu) pythonコード dx = dout.dot(self.w.T) #出力 w = dx.T.dot(dout) #重み b = dout.sum(axis=0) #バイアス Affine変換の式は重み・バイアス・入力の3値を計算します ・ ・ ・ ・ ・ ・ Affine変換の重み・バイアス
26.
© 2016 IBM
Corporation26 バックワード(Relu -> Affine) pythonコード dout[self.mask] = 0 Relu関数は値を反転してあげるだけ ・ ・ ・ ・ ・ ・
27.
© 2016 IBM
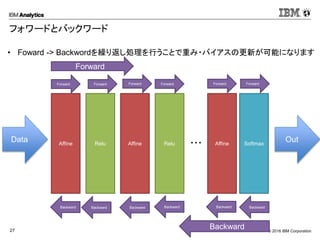
Corporation27 フォワードとバックワード Data Affine Relu Affine Relu Softmax Out・・・ Affine Forward Forward Forward Forward Forward Forward Forward Backward BackwardBackwardBackwardBackwardBackwardBackward • Foward -> Backwordを繰り返し処理を行うことで重み・バイアスの更新が可能になります
28.
© 2016 IBM
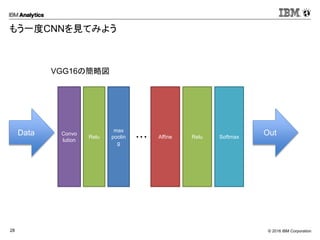
Corporation28 もう一度CNNを見てみよう Data Convo lution Relu Affine Relu Softmax Out ・・・ max poolin g VGG16の簡略図
29.
© 2016 IBM
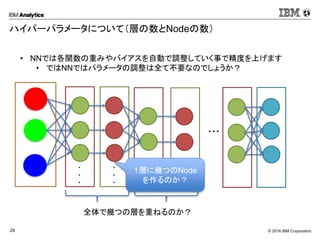
Corporation29 ハイパーパラメータについて(層の数とNodeの数) ・・・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ Softmax • NNでは各関数の重みやバイアスを自動で調整していく事で精度を上げます • ではNNではパラメータの調整は全て不要なのでしょうか? 全体で幾つの層を重ねるのか? 1層に幾つのNode を作るのか?
30.
© 2016 IBM
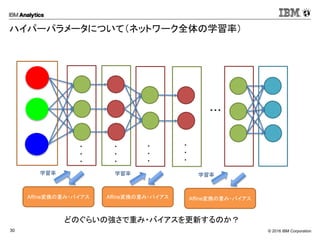
Corporation30 ハイパーパラメータについて(ネットワーク全体の学習率) Affine変換の重み・バイアス ・・・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ Softmax Affine変換の重み・バイアス Affine変換の重み・バイアス どのぐらいの強さで重み・バイアスを更新するのか? 学習率学習率学習率
31.
© 2016 IBM
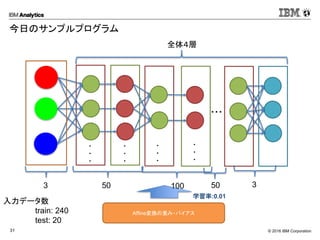
Corporation31 今日のサンプルプログラム ・・・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ ・ Softmax Affine変換の重み・バイアス 学習率:0.01 全体4層 50 100 503 3 入力データ数 train: 240 test: 20
32.
© 2016 IBM
Corporation32 DataScientistExperienceへ Notebookはこちらそれではコードに移ります
Editor's Notes
#2
1
#4
会社ではSparkとHadoopのスペシャリストやってます。
#5
DeepLearningとは
#7
今日は画像処理などややこしいことを行わず、純粋にAffine変換とRelu関数、最後のSoftmax関数のみを使ってNNを作成します。 ただ、せっかくなのでAffine+Reluを4層にしてDNNっぽく作ります。 今日のサンプルソースコードでは色(RGB)の分類を扱います。 #ちなみに色の分類行うのにわざわざDNNを作ったりはしません。説明用。
#8
Rectified linear unit
#10
元々NN系の機会学習は人間の脳の構造を模せば、識別処理が上手くいくのではというところから始まってます。
#11
で、単純パーセプトロンは、非線形の分析ができないということで、FF-NN(多層パーセプトロン)に進化していきます。
#12
今日はこのあたりからやってきます。
#16
まず入力レイヤから見ていきます。
#18
余談ですが、このNNに画像を入れる場合 30*30の画像で入力層が900になります。多いですね。
#20
また余談です。今回簡素化のため正規化かけてませんが、入力値の正規化は重要です。 今日のサンプルはこのAffine変換と活性化関数Reluを3層重ねてます。
#21
この層で結果[1,0,0] ここでForwardの処理は終わりです。ね簡単でしょ?ここまでなら・・・
#22
この時の問題として 例えば50のnodeを作ると、今回のケースでいきなり150個の重みと50個のバイアスを適切な値 これ無理ですよね? 出力結果をもとに重みやバイアスを調整するのを誤差伝搬
#23
実際のコードはSoftmax関数内で損失関数の計算もやってる 初期値はガウス分布
#24
確率勾配を用いて パラメータの微分は独立なものではなく、 レイヤのパラメータに関する誤差関数の微分は、 一つ前の層のレイヤのパラメータの微分が求まっていると、 微分計算をしなくても自動的に単純計算で決まる、つまり微分やらなくても良いので高速
#25
次はAffine変換
#28
Input(教師データ)だけ用意すればNNを通して各パラメータを自動的に算出してくれます。 これがend-to-endの機会学習と言われる所以ですね。 例えばTensorFlowやchainerやcaffe
#29
このDNNをCNNにしたい場合はいくつかの層を Convolutionとmax poolingの関数を作って入れ替えてあげればCNNの完成です。
#32
今日はこんな感じのパラメータで作ります。
Download







![© 2016 IBM Corporation18
フォワード(Affine -> Relu)
Affineの出力結果を活性化関数Reluを使って活性化させます
・
・
・
・
・
・
・
・
・
s1 = np.array([[122, 66, 94]])
w1 = np.array([[0.1], [0.2],[0.3]])
s1.dot(w1) + [0.5]
[ 54.1]
例)Affineの重み・バイアスを決め打ちで計算
n1
54.1](https://image.slidesharecdn.com/bdu1018-161020063121/85/Python-DeepLearning-18-320.jpg)
![© 2016 IBM Corporation20
フォワード(Affine -> 出力レイヤ)
Softmax関数で最終値を扱いやすい形に変換
Softmax関数
pythonコード
e = np.exp(x)
sum_e = e.sum()
return e / sum_e
Softmax
n1
n2
n3
出力例
[0, 0.1, 5.3] => [ 0.00493969, 0.0054592 , 0.98960111]
98%の確率で青と判定!](https://image.slidesharecdn.com/bdu1018-161020063121/85/Python-DeepLearning-20-320.jpg)
![© 2016 IBM Corporation22
バックプロパゲーション(損失関数)
• 各nodeの重みとバイアスは?
・・・
Backward
・
・
・
・
・
・
OutSoftmax
RGB(122, 66, 94)
教師Label [1,0,0]
初期値を当てる
Forward
教師Label
[1,0,0]
出力
[0.3,0.28,0.32]
損失関数
誤差修正
交差エントロピー誤差](https://image.slidesharecdn.com/bdu1018-161020063121/85/Python-DeepLearning-22-320.jpg)
![© 2016 IBM Corporation26
バックワード(Relu -> Affine)
pythonコード
dout[self.mask] = 0
Relu関数は値を反転してあげるだけ
・
・
・
・
・
・](https://image.slidesharecdn.com/bdu1018-161020063121/85/Python-DeepLearning-26-320.jpg)

![SparkとJupyterNotebookを使った分析処理 [Html5 conference]](https://cdn.slidesharecdn.com/ss_thumbnails/html5conference-160903045852-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)












