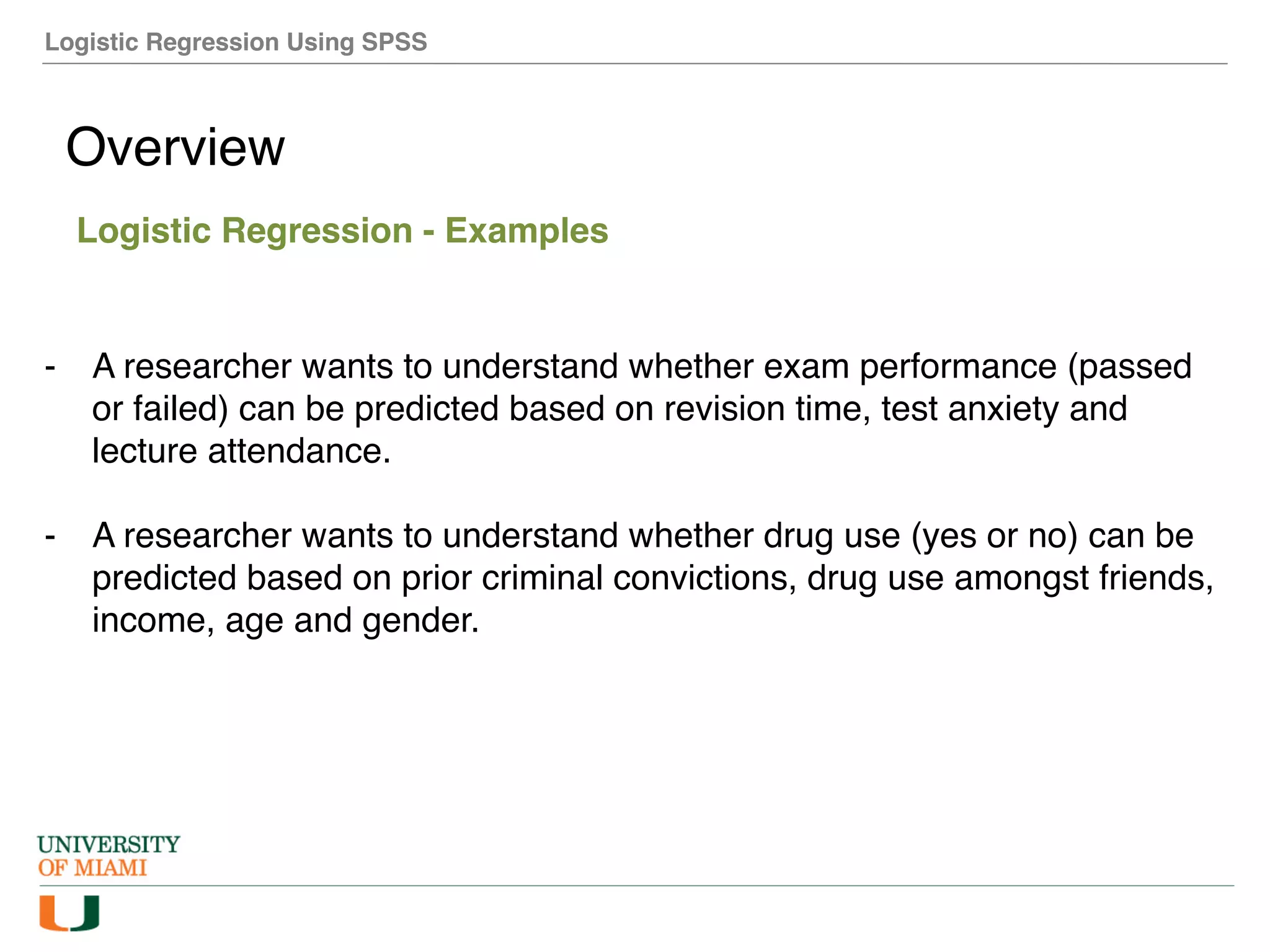
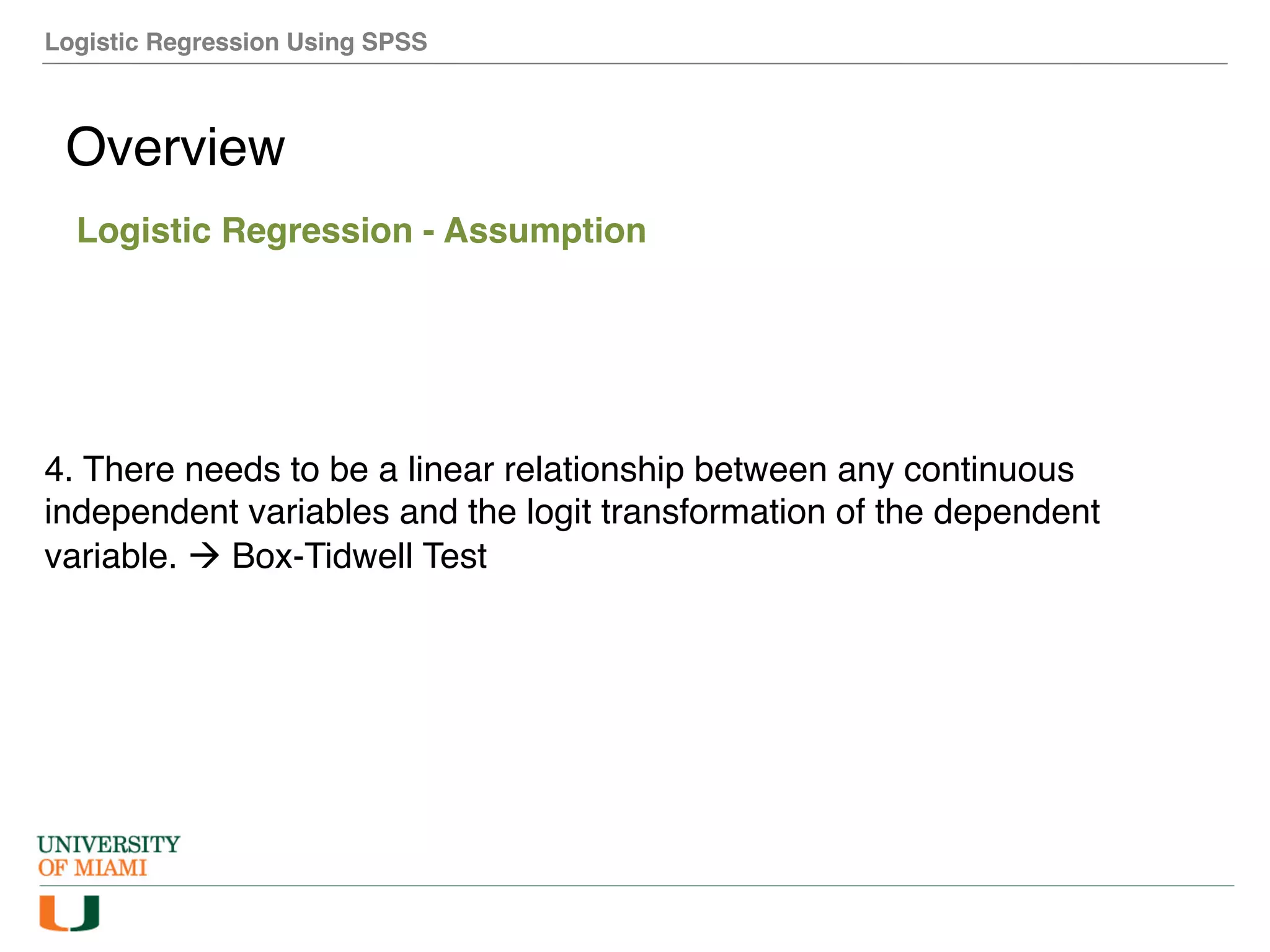
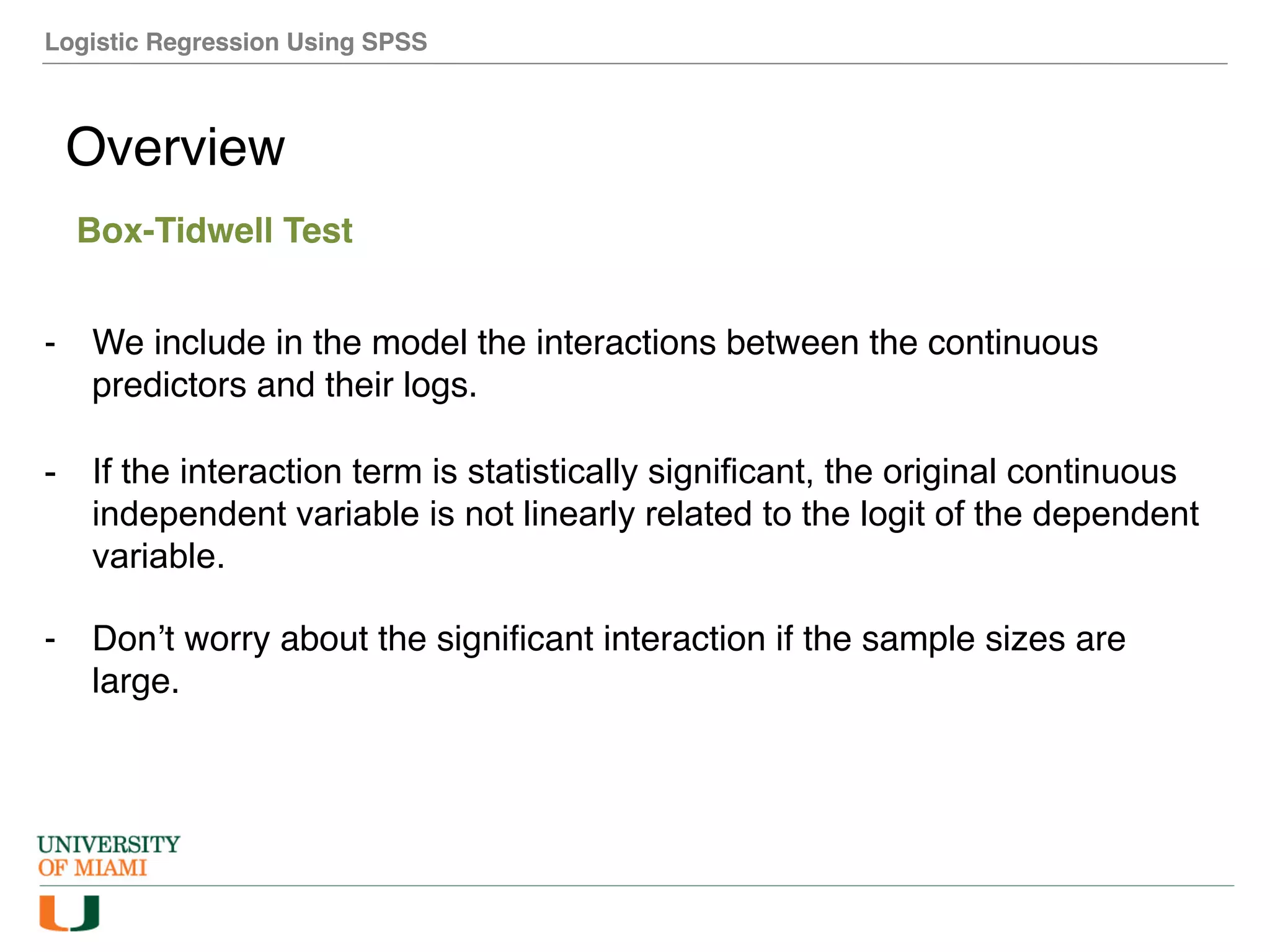
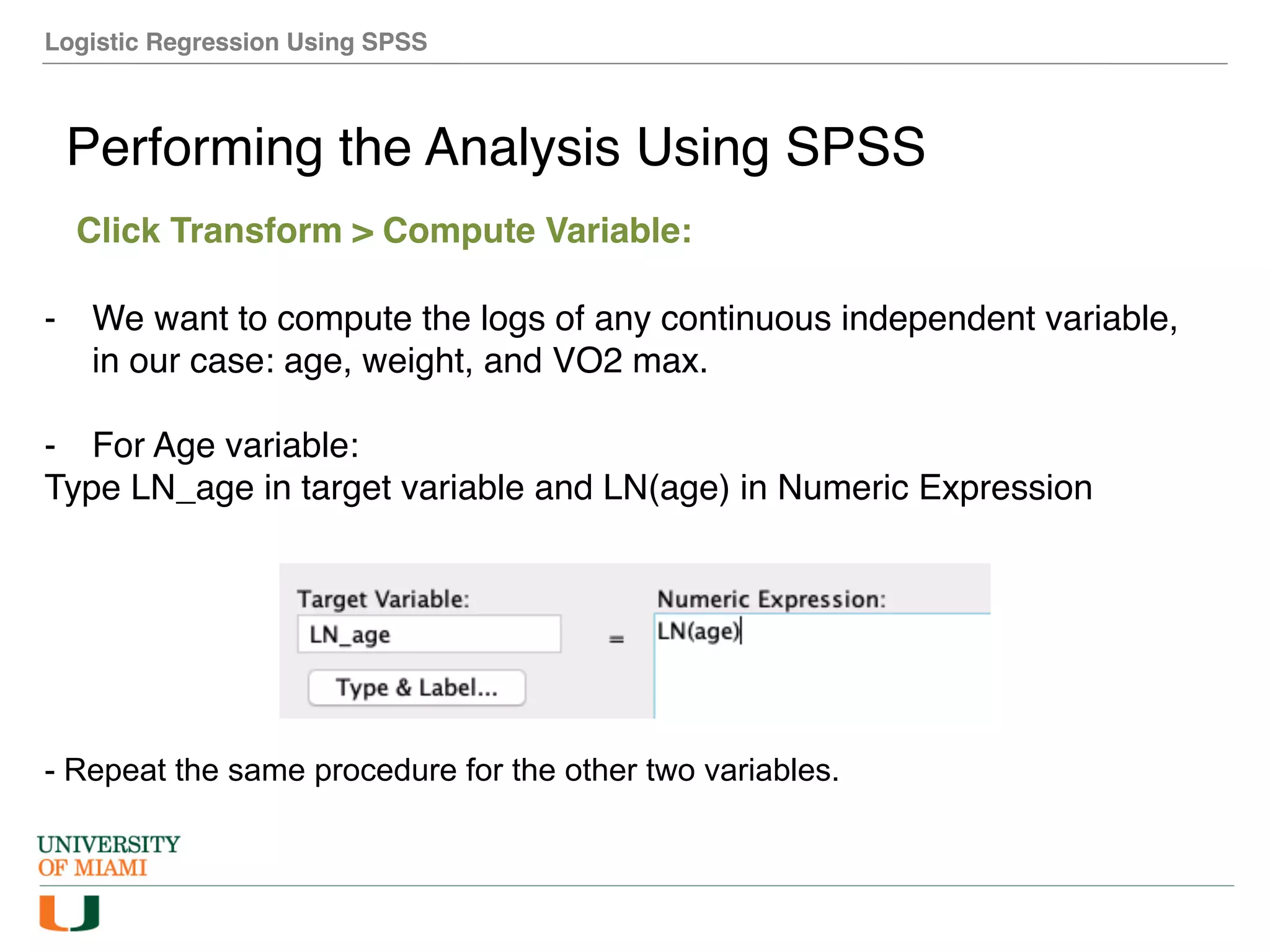
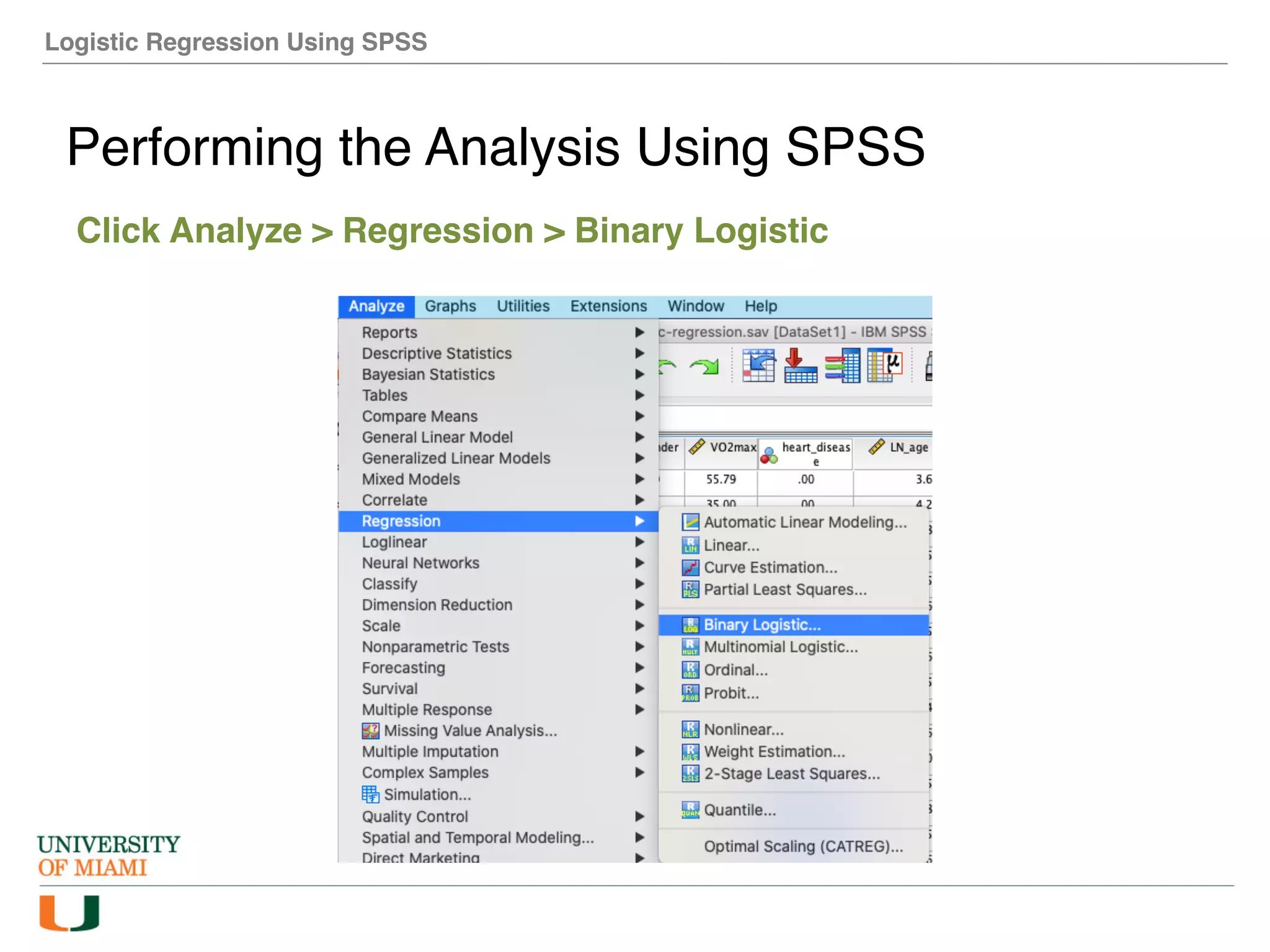
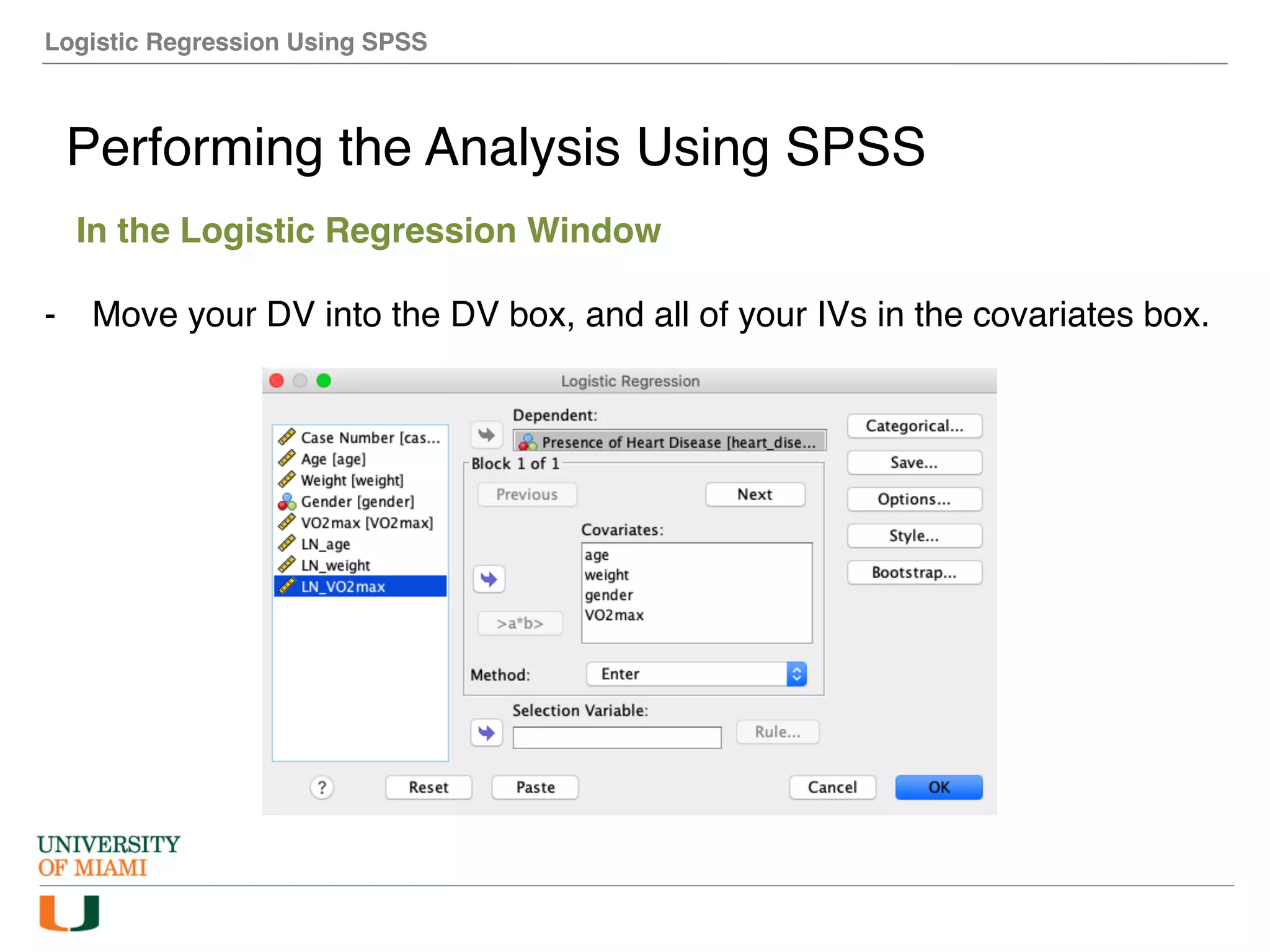
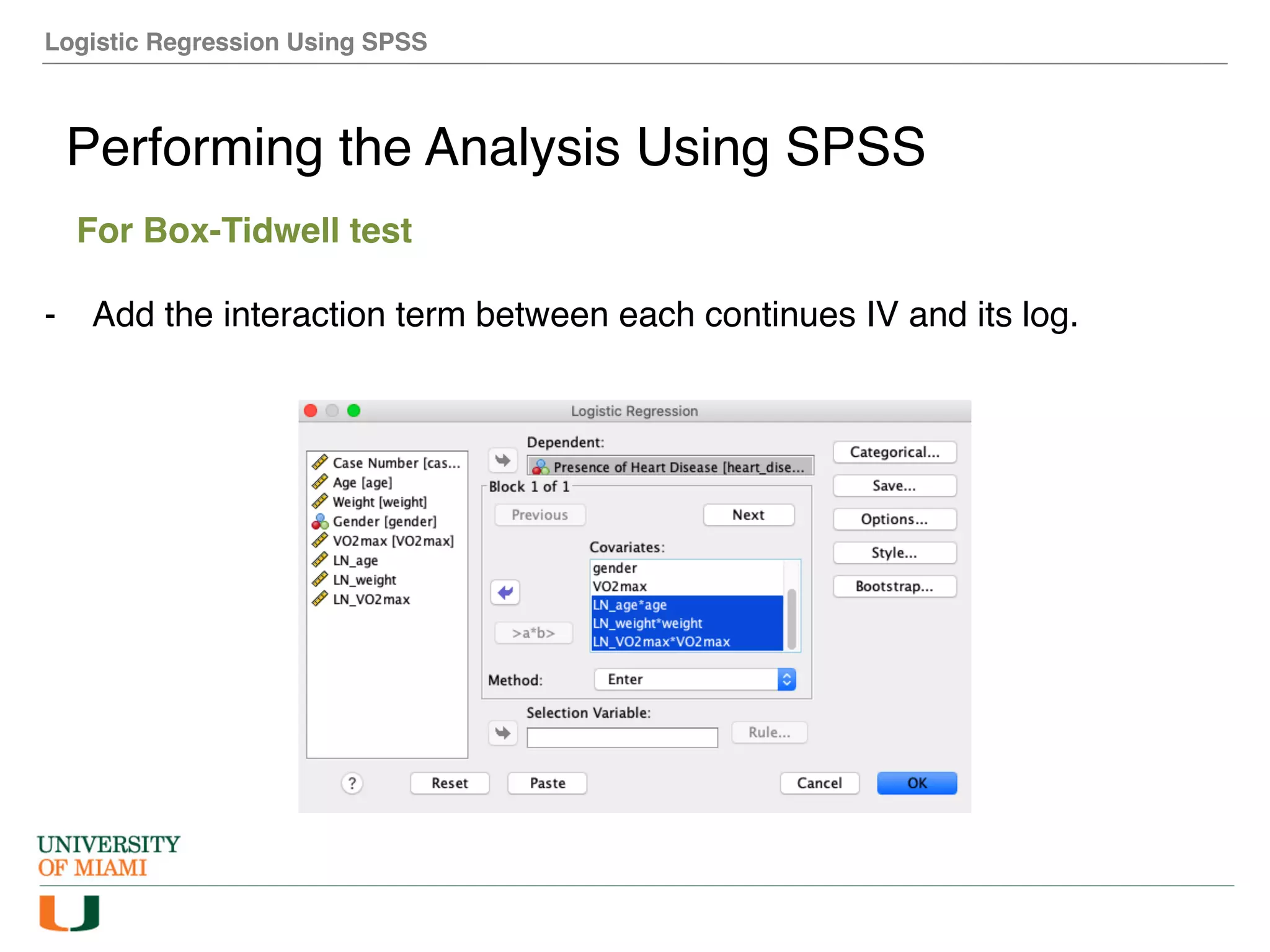
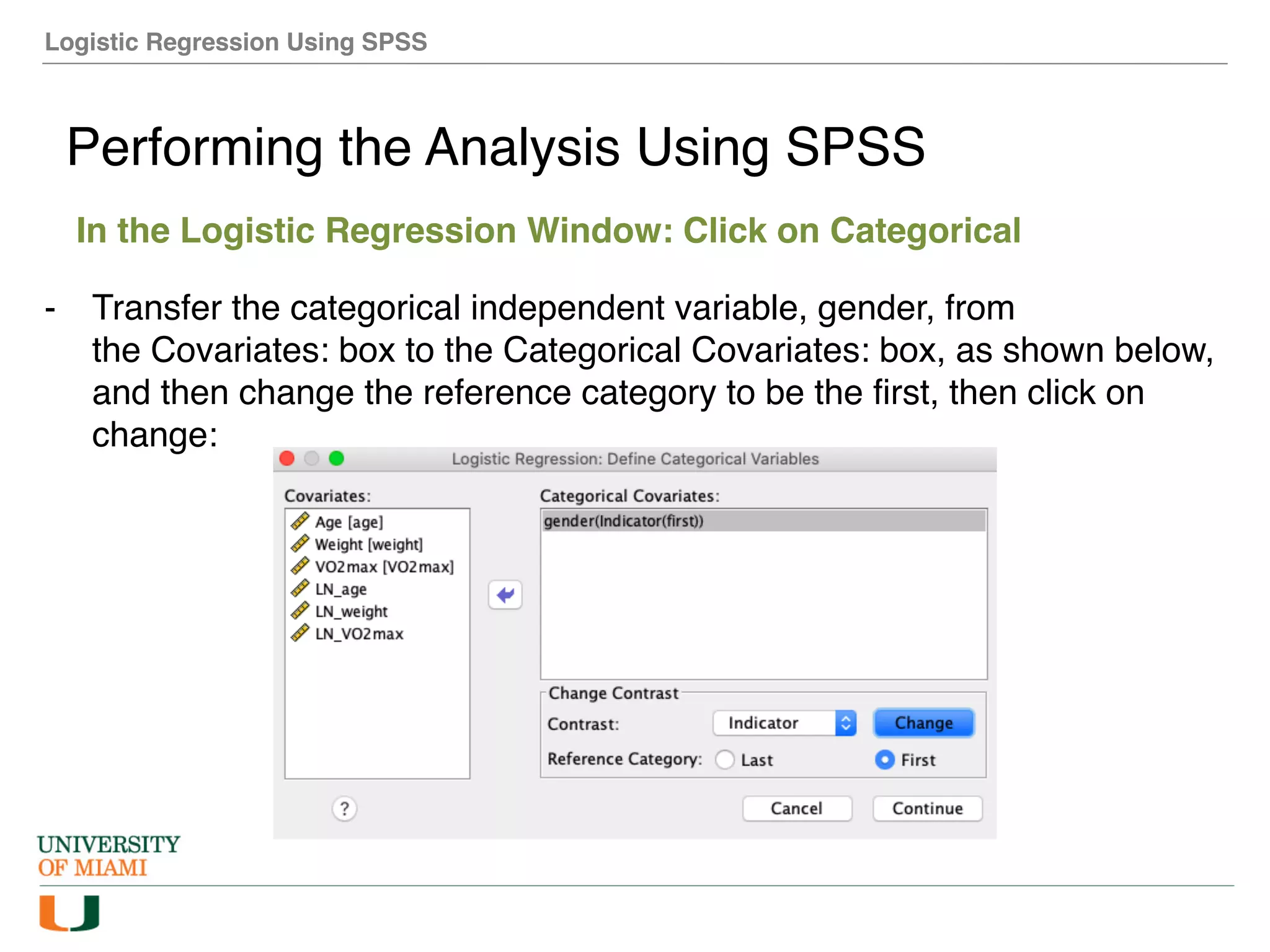
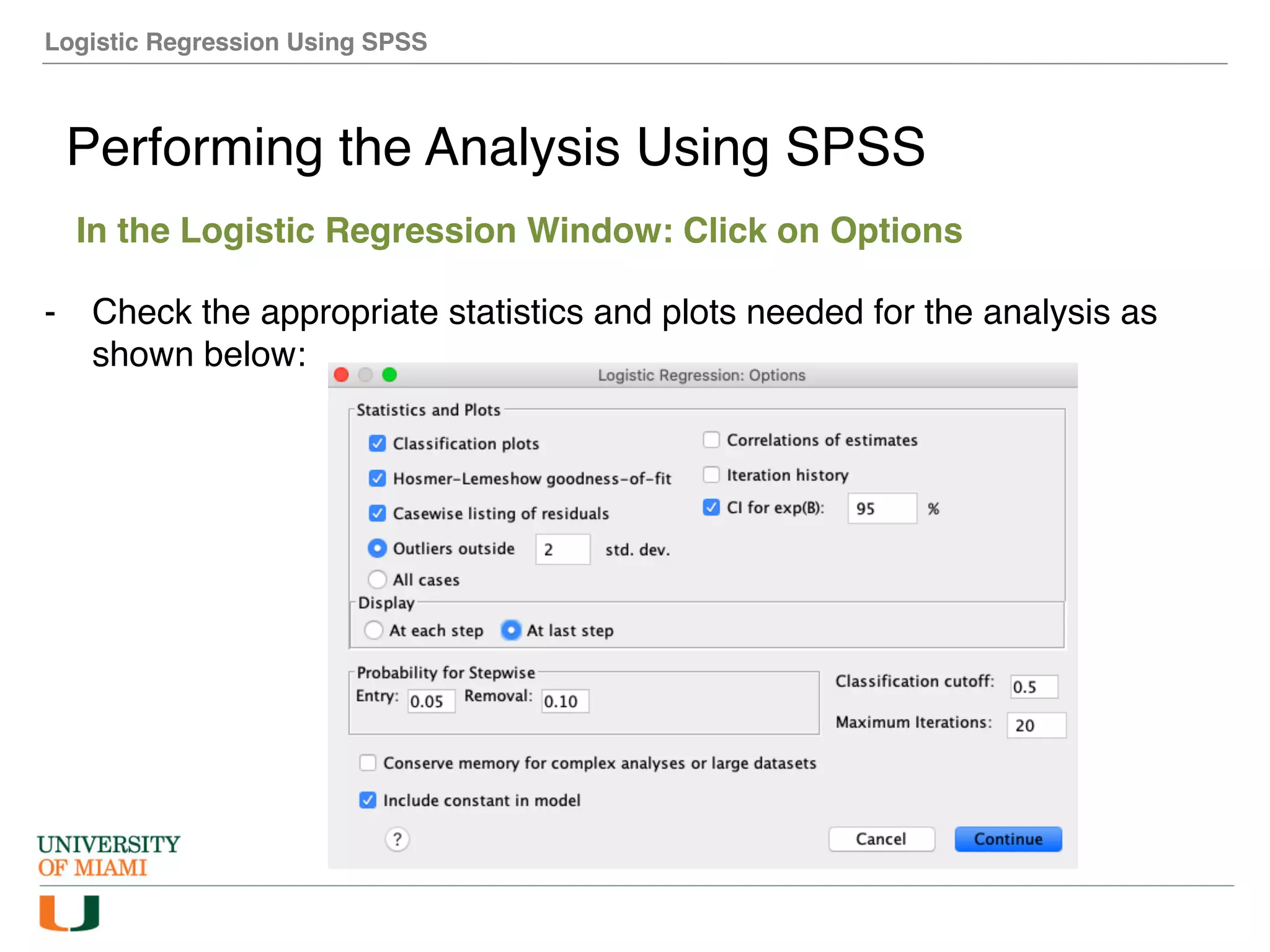
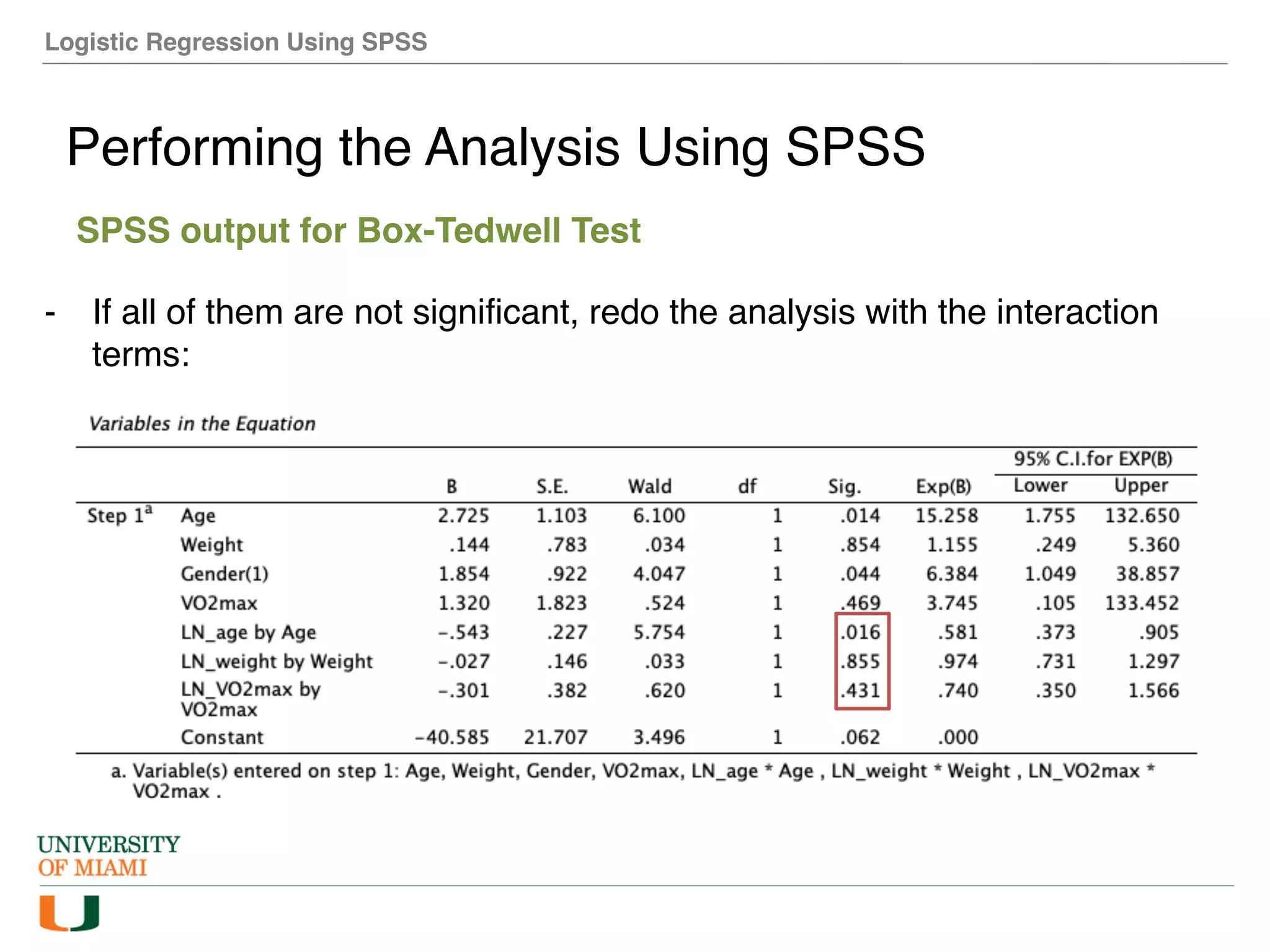
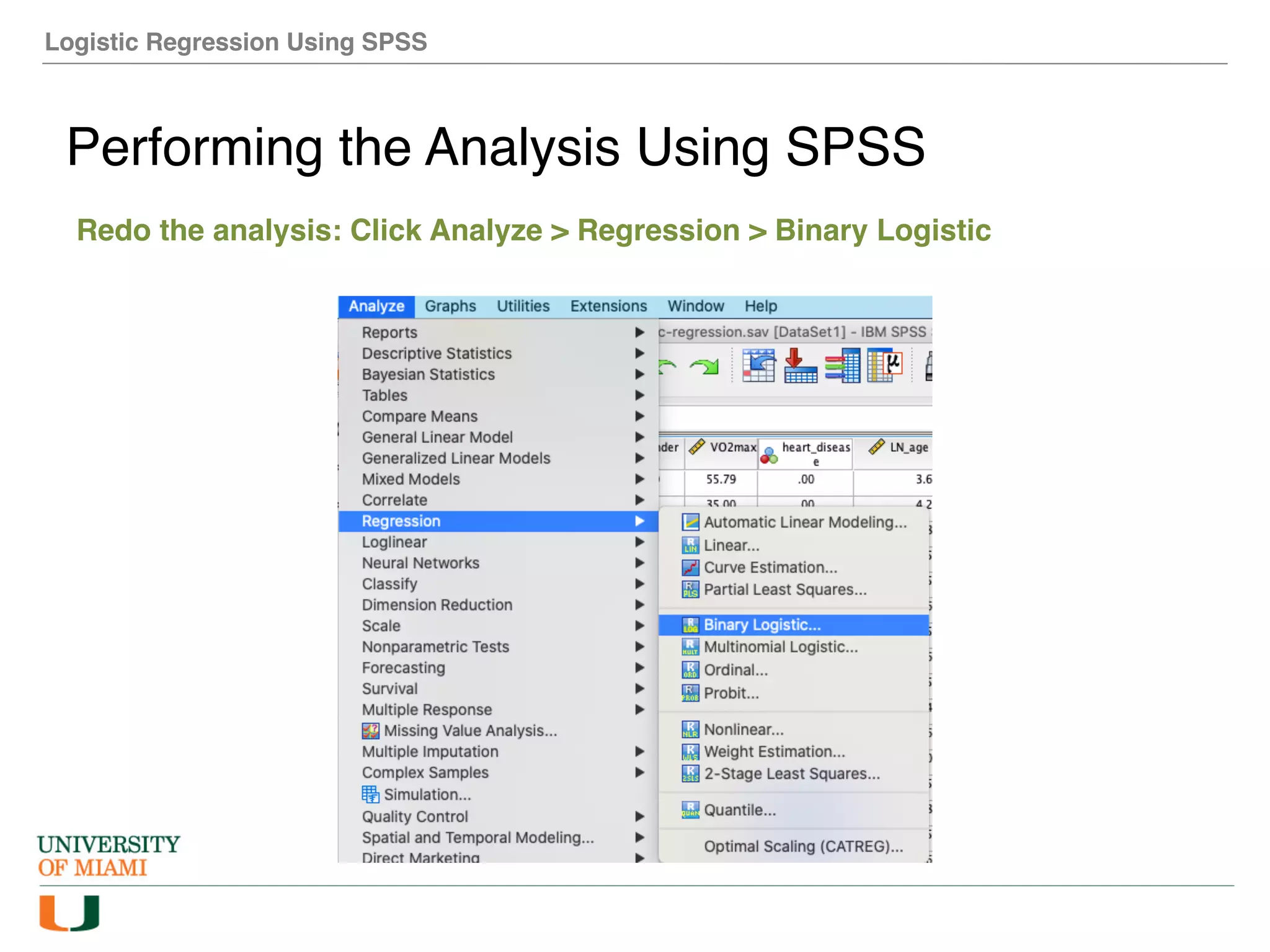
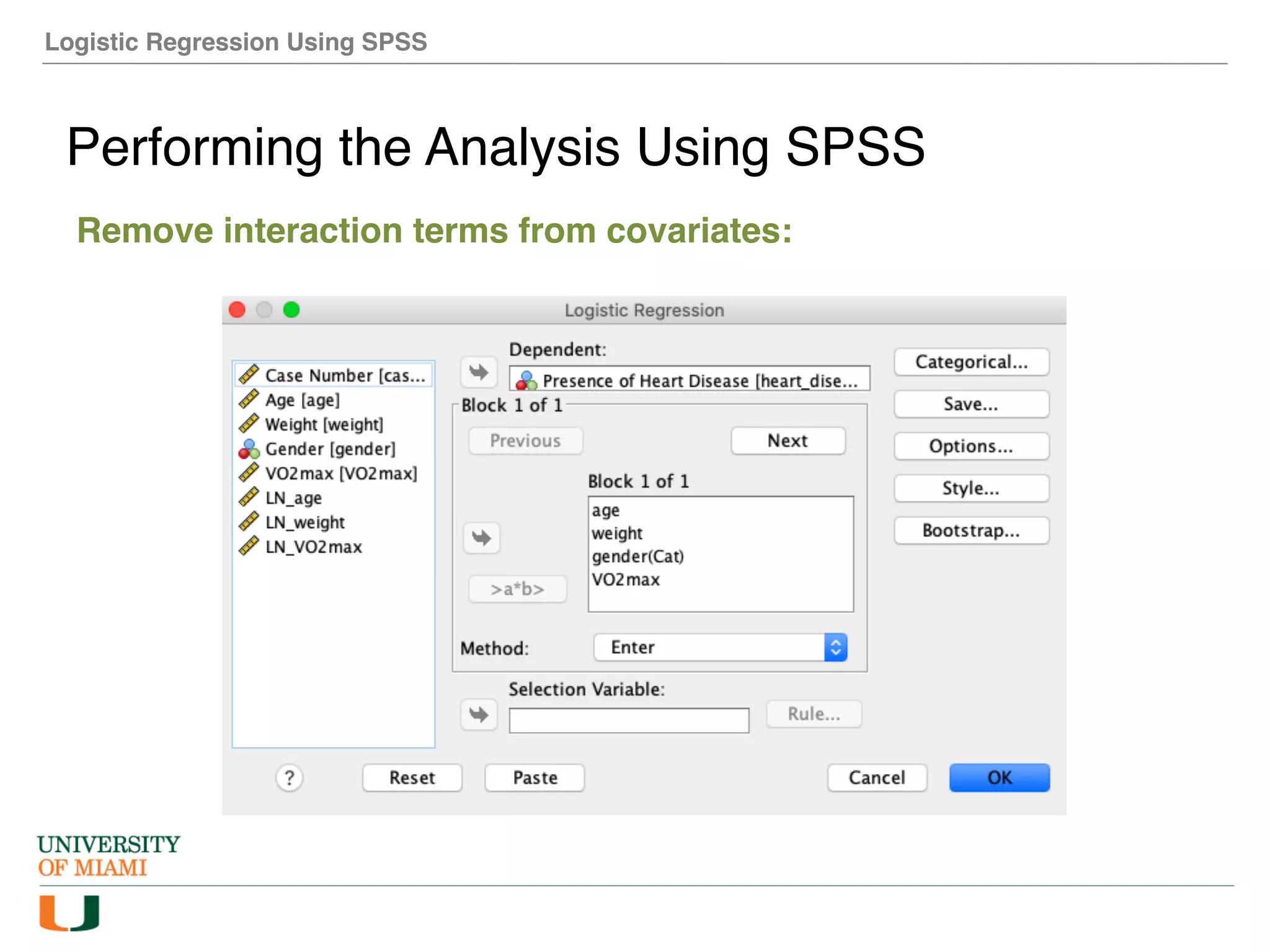
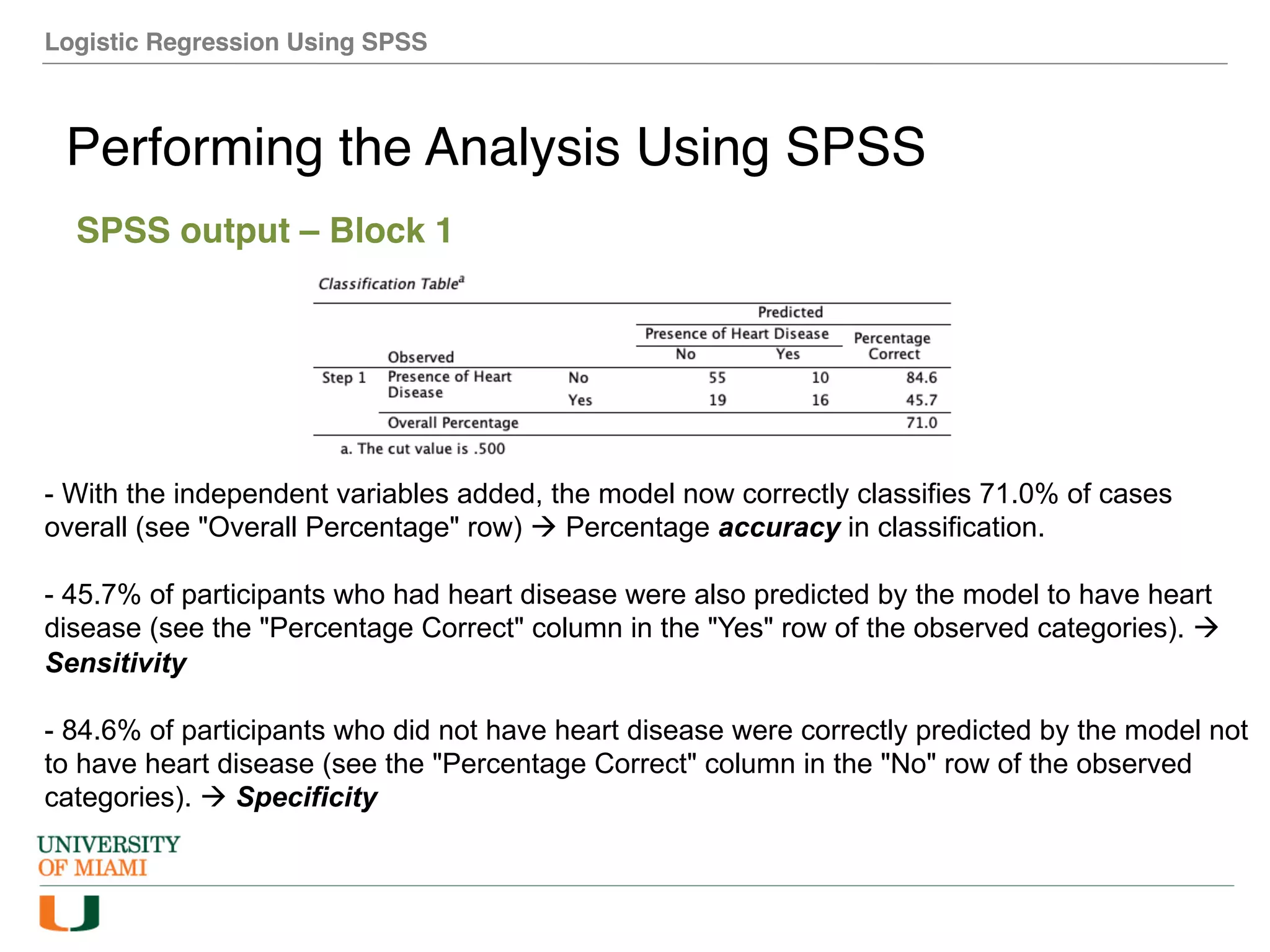
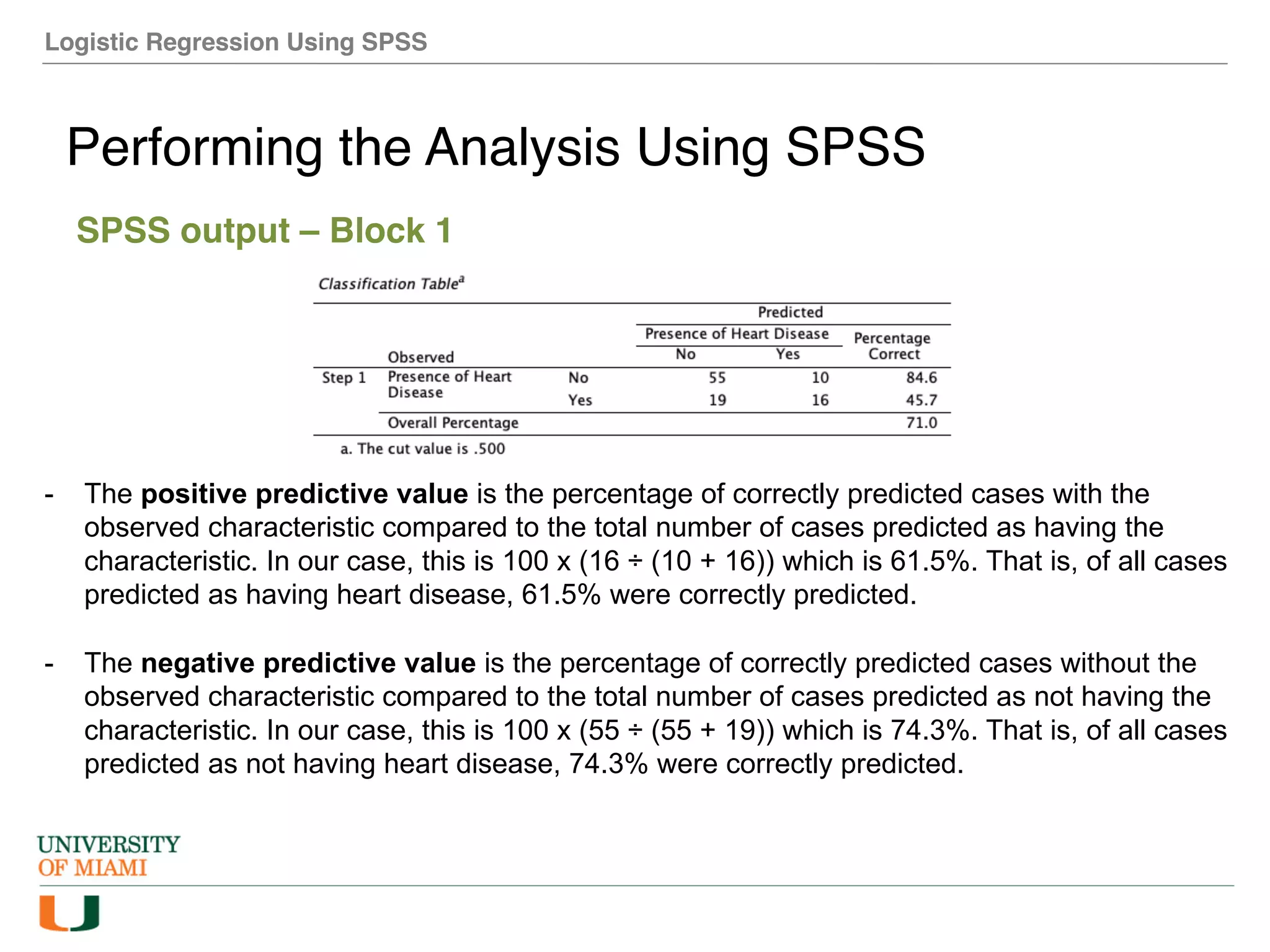
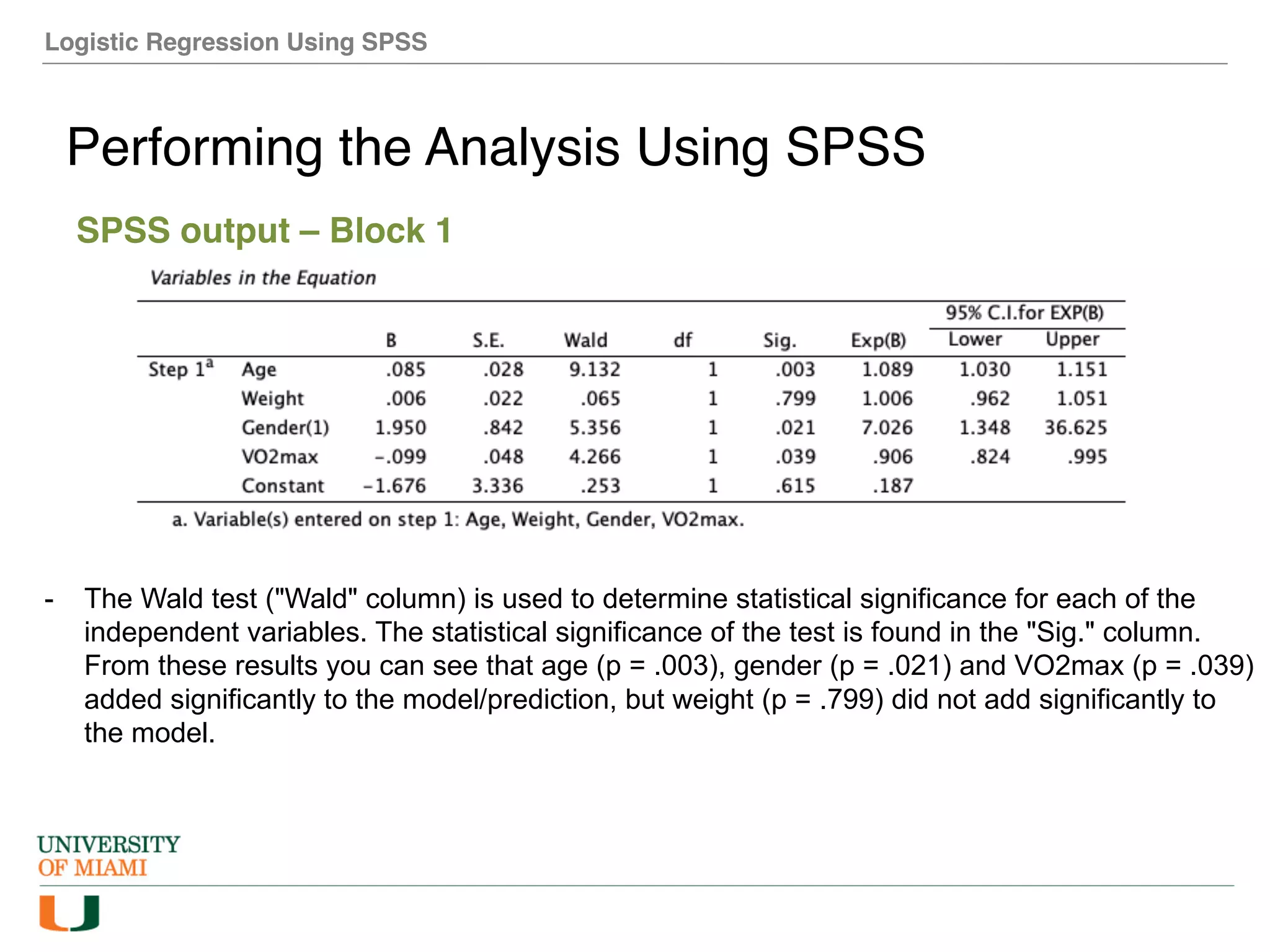
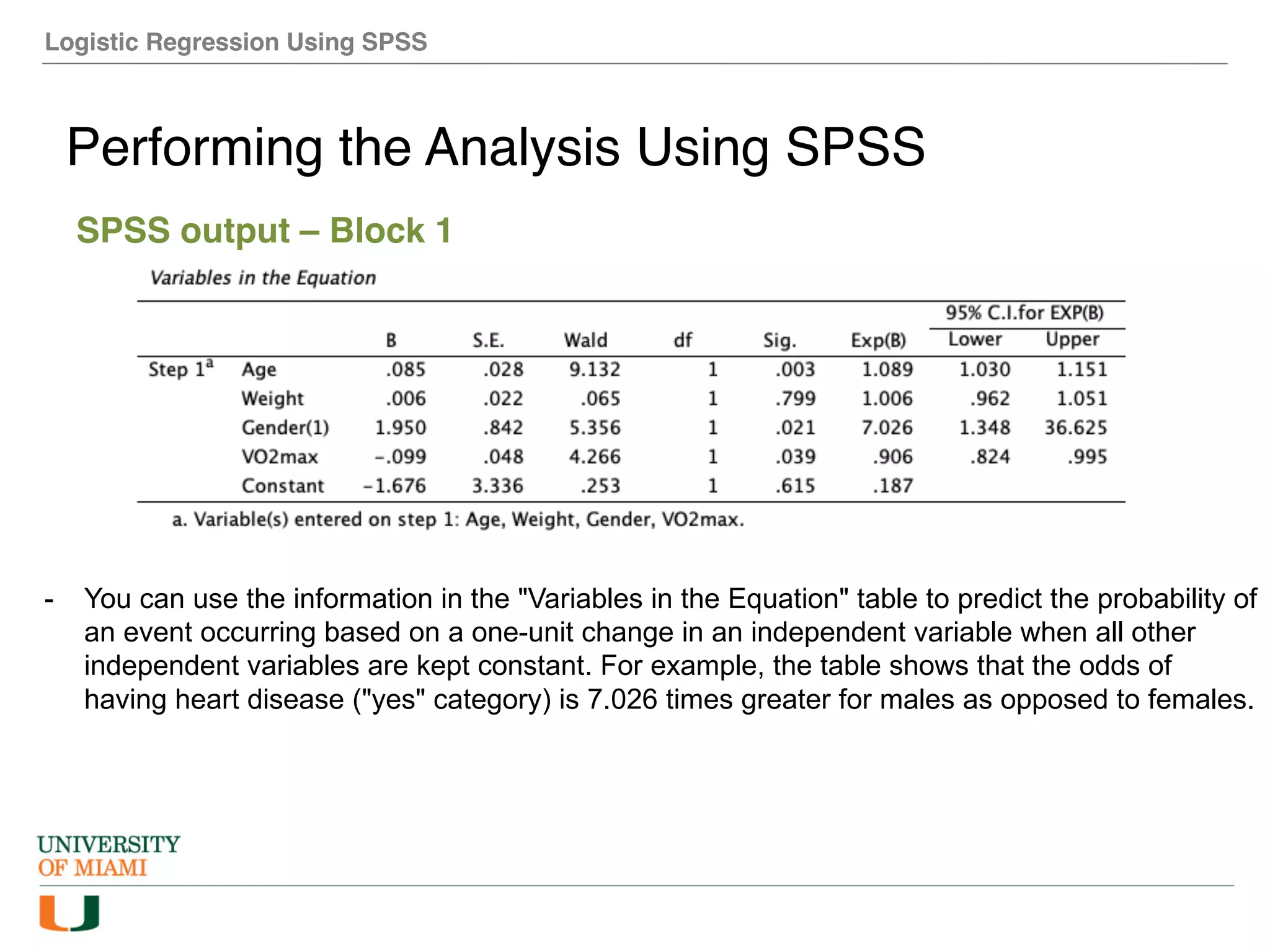
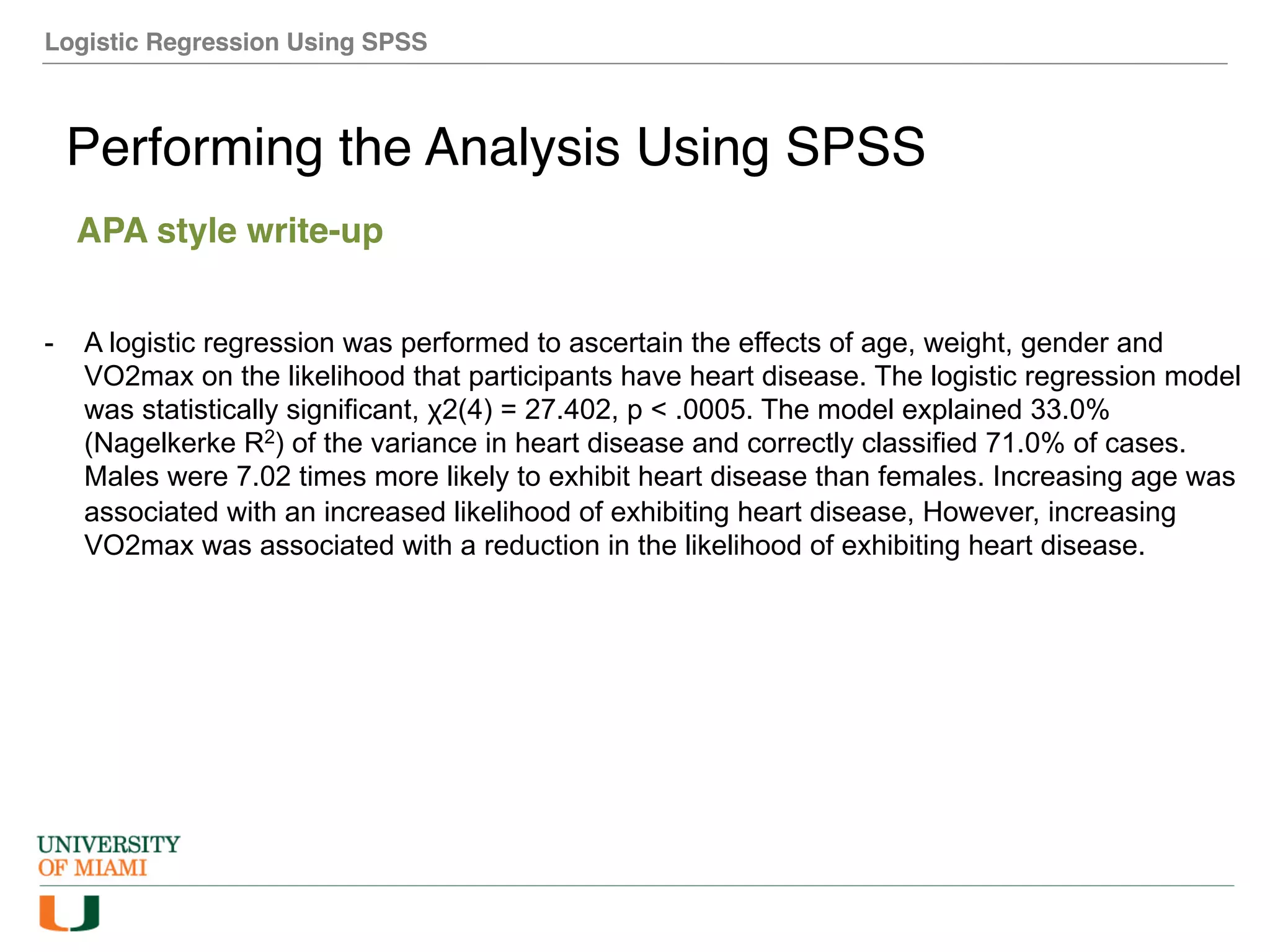
The document provides an overview of how to perform logistic regression analysis in SPSS. It discusses key concepts of logistic regression including using it to predict categorical outcomes from predictor variables. It also reviews assumptions of logistic regression and how to interpret outputs in SPSS including testing model fit and predicting probabilities. The document then demonstrates how to conduct a logistic regression analysis in SPSS to predict heart disease from variables like age, gender and VO2 max.































































![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)

