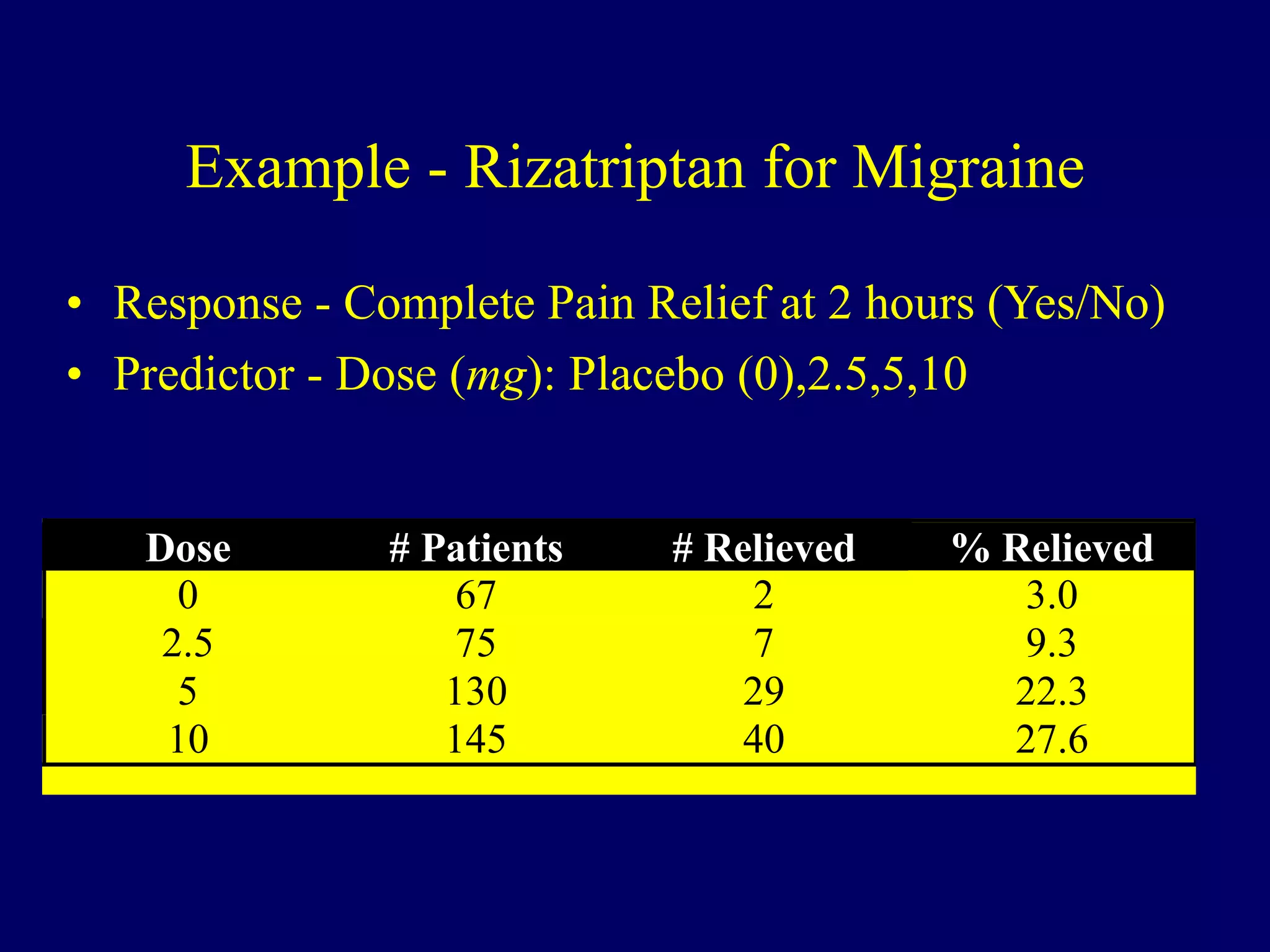
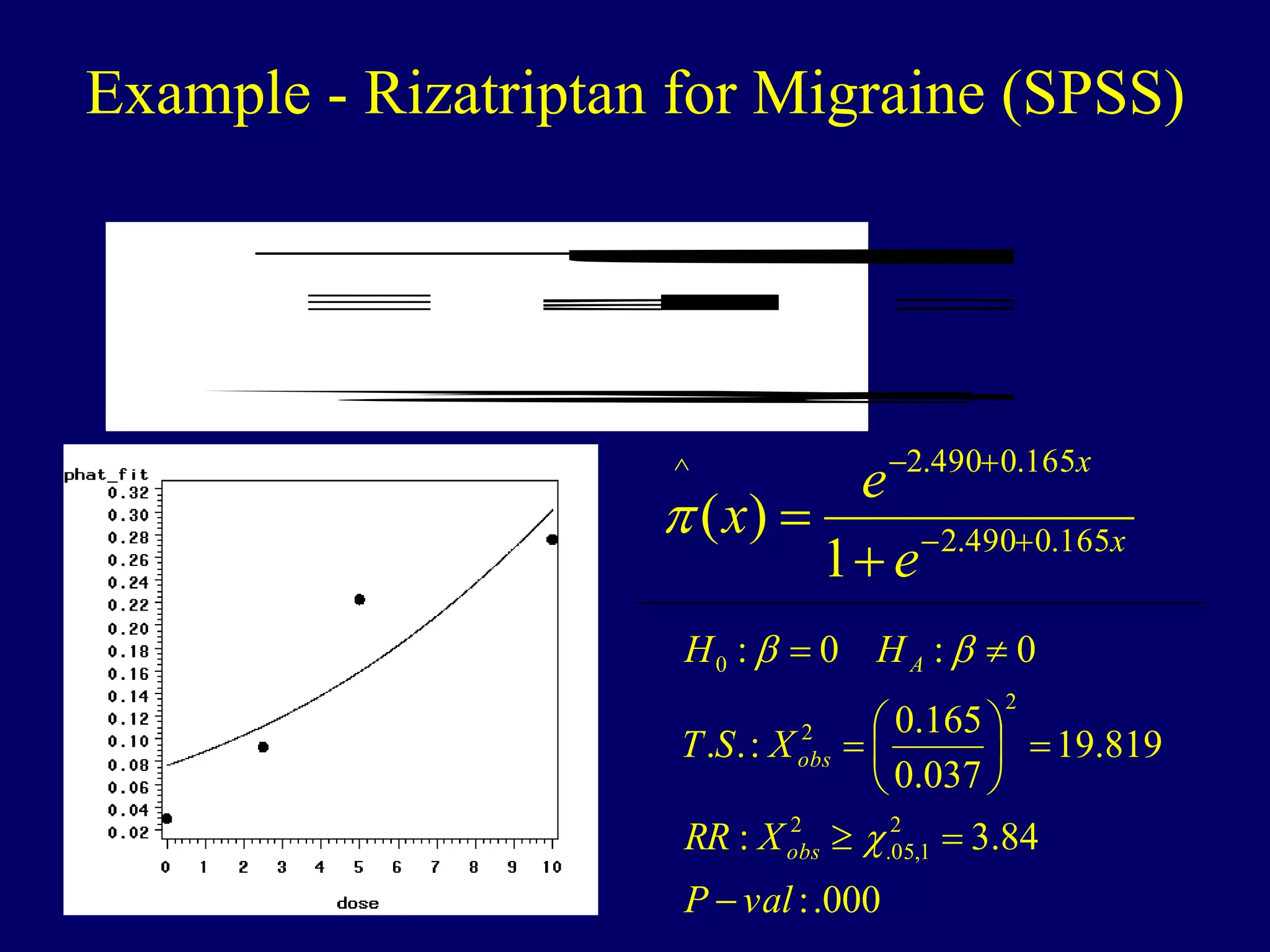
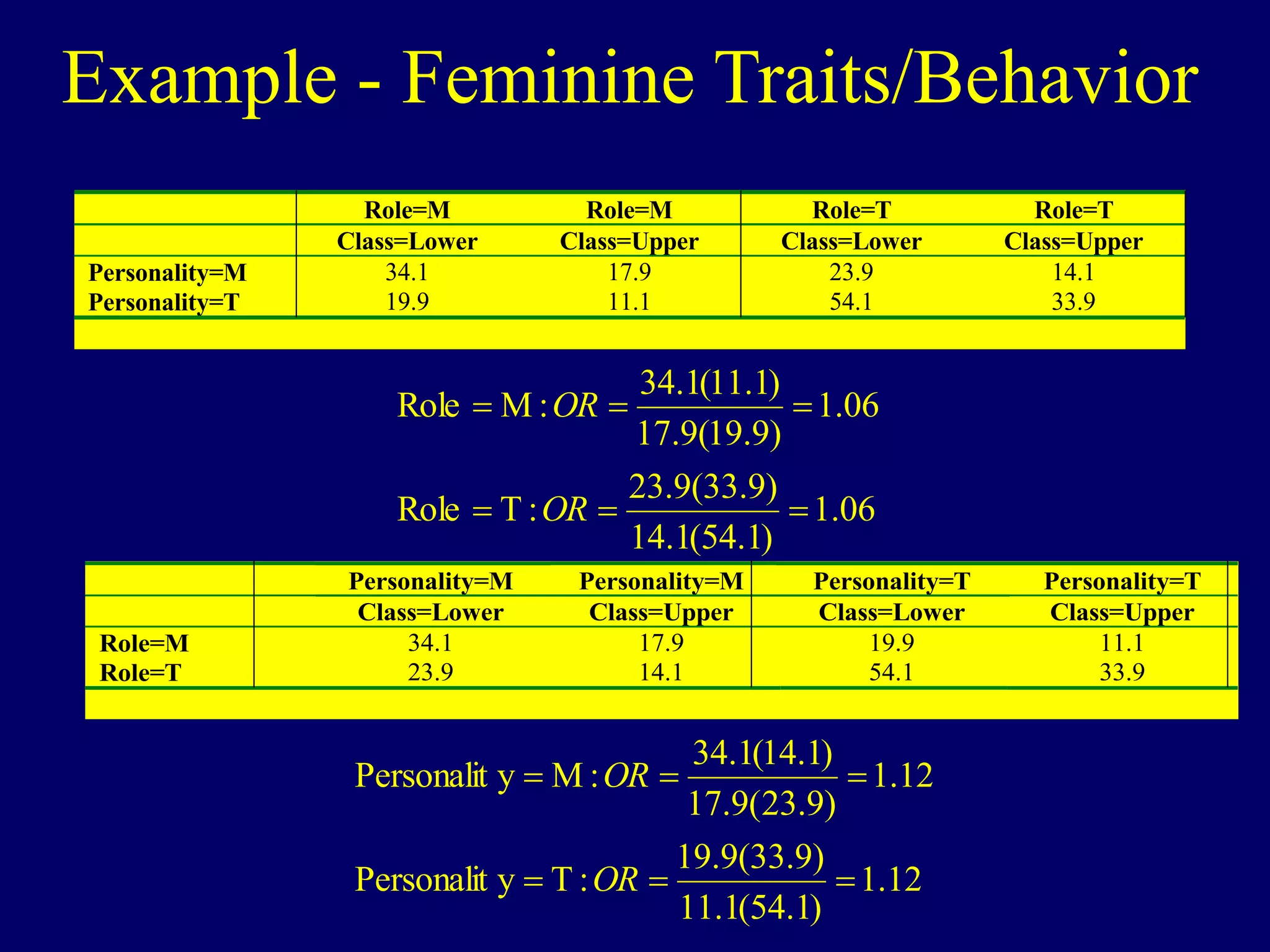
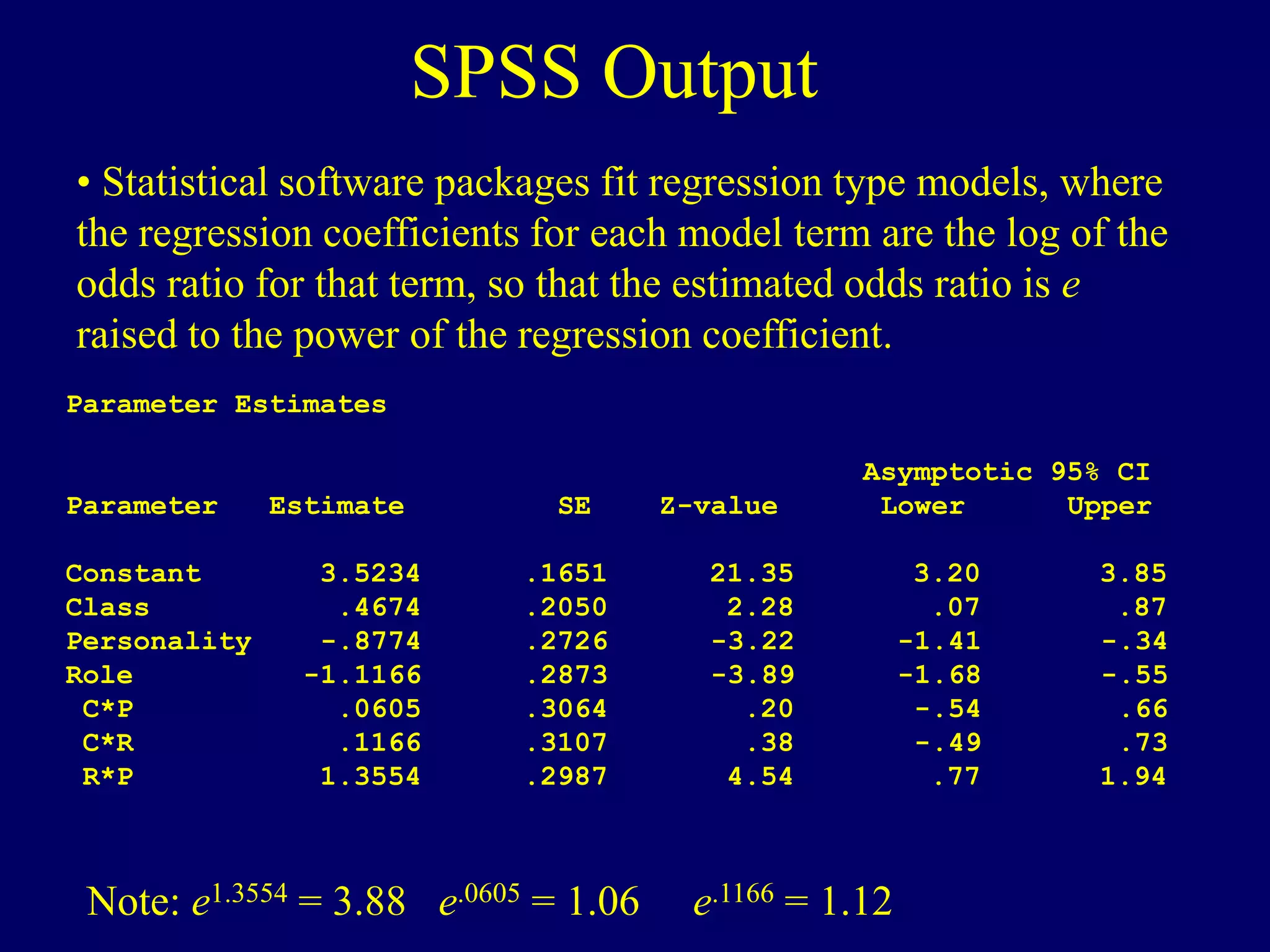
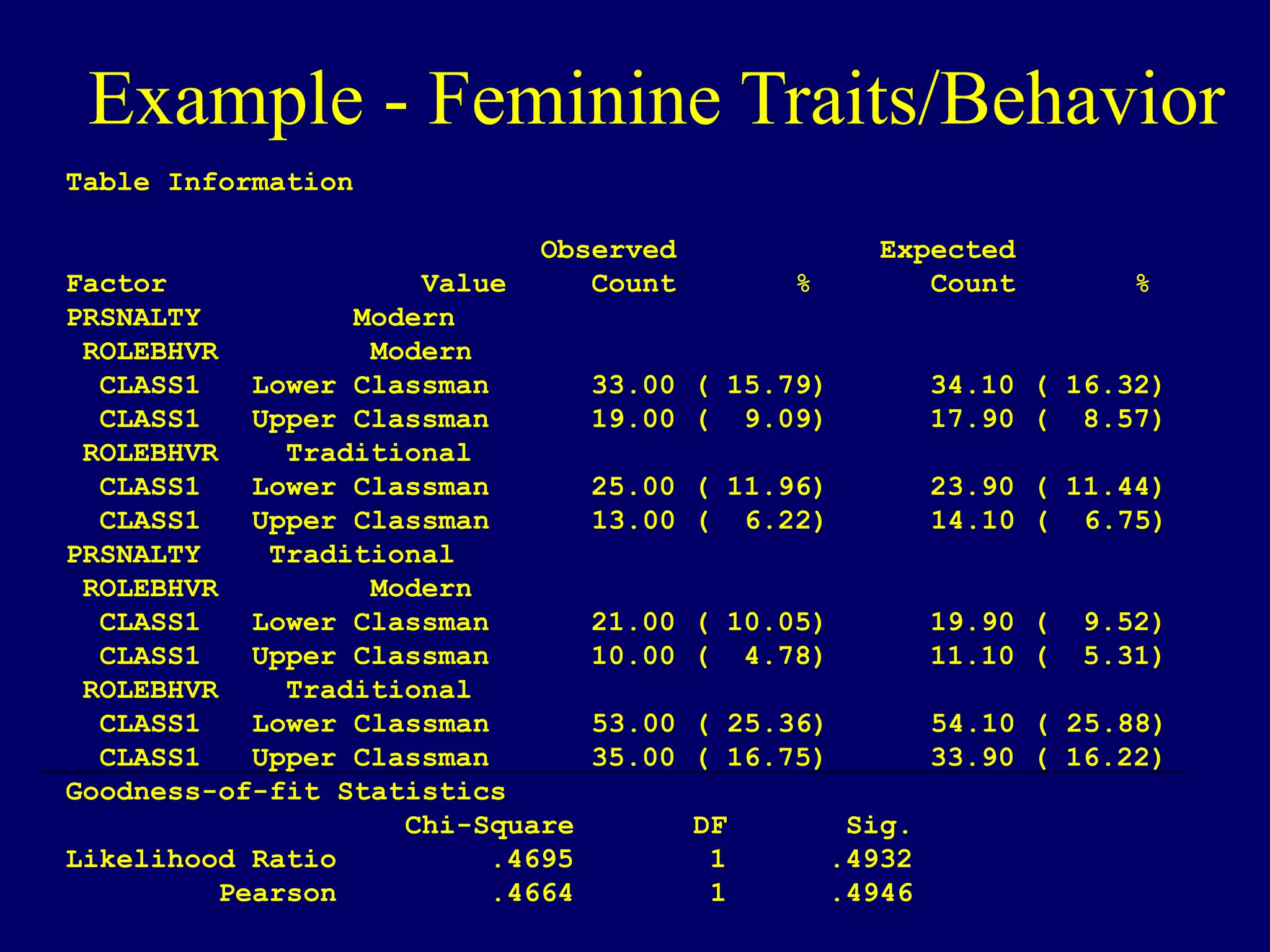
Logistic regression is used to model dichotomous outcome variables based on one or more predictor variables. It models the probability of an outcome as a function of the predictors using a logistic link function. The model estimates regression coefficients that represent the log odds ratios of the predictors. Odds ratios above 1 indicate increased odds of the outcome with higher predictor values, while odds ratios below 1 indicate decreased odds. Logistic regression allows testing of individual predictor coefficients and the overall model fit. Loglinear models generalize logistic regression to situations with categorical predictors where there is no clear outcome variable.




































![logistic model final_pptx__corected_one[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/finalpptxcorectedone1-251124022241-c29356b7-thumbnail.jpg?width=640&height=640&fit=bounds)







































![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)