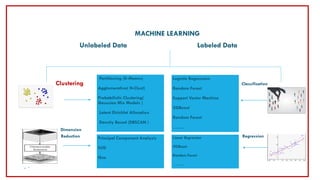
1. Clustering is an unsupervised machine learning technique used to group unlabeled data points into clusters based on similarity. There are several types of clustering including partitioning methods like k-means, hierarchical clustering, density-based clustering, and probabilistic clustering.
2. When choosing a clustering technique, factors to consider include the type of data, whether the number of clusters is known, the presence of noise or missing data, dimensionality of the data, shape of the clusters, and speed/scalability needs.
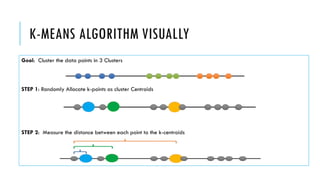
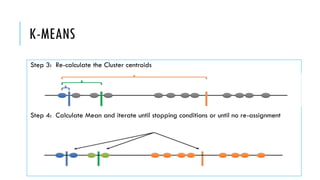
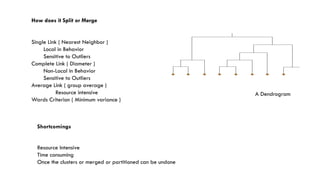
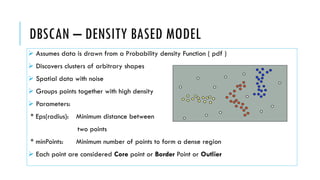
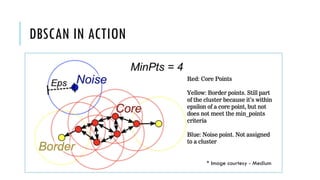
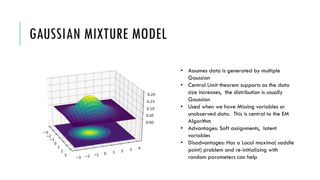
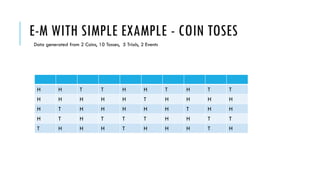
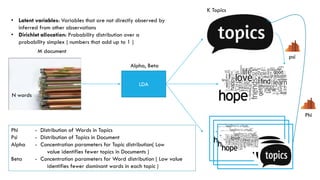
3. Popular clustering algorithms include k-means, hierarchical clustering, DBSCAN, Gaussian mixture models, and Latent Dirichlet Allocation (LDA) for text clustering. Each have their own pros and cons depending







































































![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)











