Downloaded 113 times









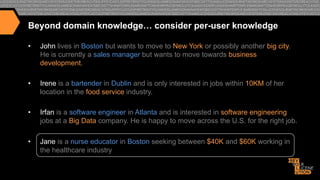
![Custom scoring with Payloads
•
In addition to boosting search terms and fields, content within Fields can also be
boosted differently using Payloads (requires a custom scoring implementation):
design [1] / engineer [1] / really [ ] / great [ ] / job [ ] / ten[3] / years[3] /
experience[3] / careerbuilder [2] / design [2], …
jobtitle: bucket=[1] boost=10; company: bucket=[2] boost=4;
jobdescription: bucket=[ ] weight=1; experience: bucket=[3] weight=1.5
We can pass in a parameter to solr at query time specifying the boost to apply to each
bucket i.e. …&bucketWeights=1:10;2:4;3:1.5;default:1;
•
This allows us to map many relevancy buckets to search terms at index time and adjust
the weighting at query time without having to search across hundreds of fields.
•
By making all scoring parameters overridable at query time, we are able to do A / B
testing to consistently improve our relevancy model](https://image.slidesharecdn.com/enhancingrelevancythroughpersonalizationsemanticsearch-131129103541-phpapp02/85/Enhancing-relevancy-through-personalization-semantic-search-18-320.jpg)





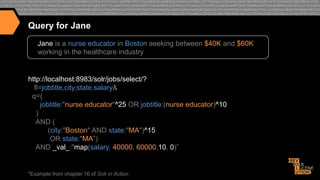
![Search Results for Jane
{ ...
"response":{"numFound":22,"start":0,"docs":[
{"jobtitle":"Clinical Educator
(New England/ Boston)",
"city":"Boston",
"state":"MA",
"salary":41503},
{"jobtitle":"Nurse Educator",
"city":"Braintree",
"state":"MA",
"salary":56183},
{"jobtitle":"Nurse Educator",
"city":"Brighton",
"state":"MA",
"salary":71359}
…]}}
*Example documents available @ http://github.com/treygrainger/solr-in-action/](https://image.slidesharecdn.com/enhancingrelevancythroughpersonalizationsemanticsearch-131129103541-phpapp02/85/Enhancing-relevancy-through-personalization-semantic-search-29-320.jpg)


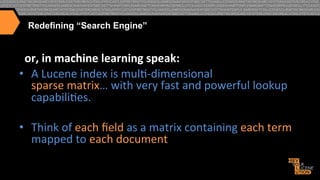
![The Lucene Inverted Index (traditional text example)
What
you
SEND
to
Lucene/Solr:
How
the
content
is
INDEXED
into
Lucene/Solr
(conceptually):
Document
Content
Field
Term
Documents
doc1
once
upon
a
>me,
in
a
land
far,
far
away
a
doc1
[2x]
brown
doc2
the
cow
jumped
over
the
moon.
doc3
[1x]
,
doc5
[1x]
cat
doc4
[1x]
doc3
the
quick
brown
fox
jumped
over
the
lazy
dog.
cow
doc2
[1x]
,
doc5
[1x]
…
...
doc4
the
cat
in
the
hat
once
doc1
[1x],
doc5
[1x]
doc5
The
brown
cow
said
“moo”
once.
over
doc2
[1x],
doc3
[1x]
the
…
…
doc2
[2x],
doc3
[2x],
doc4[2x],
doc5
[1x]
…
…](https://image.slidesharecdn.com/enhancingrelevancythroughpersonalizationsemanticsearch-131129103541-phpapp02/85/Enhancing-relevancy-through-personalization-semantic-search-33-320.jpg)



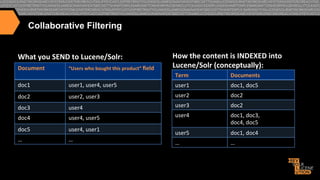
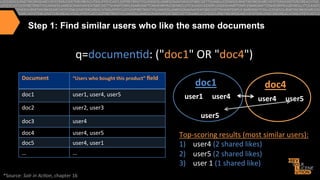
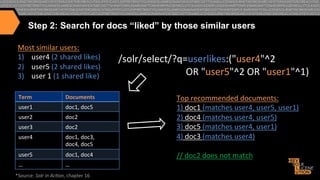








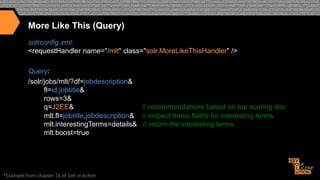
![More Like This (Results)
{"match":{"numFound":122,"start":0,"docs":[
{"id":"fc57931d42a7ccce3552c04f3db40af8dabc99dc",
"jobtitle":"Senior
Java / J2EE Developer"}]
},
"response":{"numFound":2225,"start":0,"docs":[
{"id":"0e953179408d710679e5ddbd15ab0dfae52ffa6c",
"jobtitle":"Sr
Core Java Developer"},
{"id":"5ce796c758ee30ed1b3da1fc52b0595c023de2db",
"jobtitle":"Applications
Developer"},
{"id":"1e46dd6be1750fc50c18578b7791ad2378b90bdd",
"jobtitle":"Java Architect/
Lead Java Developer WJAV Java - Java in Pittsburgh PA"},]},
"interes>ngTerms":[
"jobdescrip>on:j2ee",1.0,
"jobdescrip>on:java",0.68131137,
"jobdescrip>on:senior",0.52161527,
"job>tle:developer",0.44706684,
"jobdescrip>on:source",0.2417754,
"jobdescrip>on:code",0.17976432,
"jobdescrip>on:is",0.17765637,
"jobdescrip>on:client",0.17331646,
"jobdescrip>on:our",0.11985878,
"jobdescrip>on:for",0.07928475,
"jobdescrip>on:a",0.07875194,
"jobdescrip>on:to",0.07741922,
"jobdescrip>on:and",0.07479082]}}](https://image.slidesharecdn.com/enhancingrelevancythroughpersonalizationsemanticsearch-131129103541-phpapp02/85/Enhancing-relevancy-through-personalization-semantic-search-55-320.jpg)
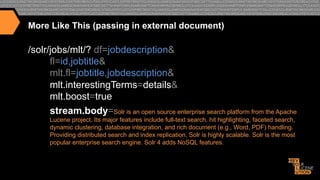
![More Like This (Results)
{"response":{"numFound":2221,"start":0,"docs":[
{"id":"eff5ac098d056a7ea6b1306986c3ae511f2d0d89 ",
•
"jobtitle":"Enterprise
Search Architect…"},
{"id":"37abb52b6fe63d601e5457641d2cf5ae83fdc799 ",
"jobtitle":"Sr.
Java Developer"},
{"id":"349091293478dfd3319472e920cf65657276bda4 ",
"jobtitle":"Java
Lucene Software Engineer"},]},
"interes>ngTerms":[
"jobdescrip>on:search",1.0,
"jobdescrip>on:solr",0.9155779,
"jobdescrip>on:features",0.36472517,
"jobdescrip>on:enterprise",0.30173126,
"jobdescrip>on:is",0.17626463,
"jobdescrip>on:the",0.102924034,
"jobdescrip>on:and",0.098939896]}
}](https://image.slidesharecdn.com/enhancingrelevancythroughpersonalizationsemanticsearch-131129103541-phpapp02/85/Enhancing-relevancy-through-personalization-semantic-search-57-320.jpg)




The document discusses enhancing search relevancy at CareerBuilder through personalization and semantic search, focusing on advanced relevancy scoring techniques using Solr. It highlights the importance of user behavior, contexts, and domain-specific knowledge in improving search outcomes, along with examples of recommendation engines and query optimization strategies. Additionally, it outlines future work on semantic search and automatic synonym discovery to further refine search capabilities.























































































