Downloaded 173 times





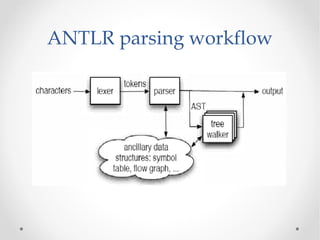



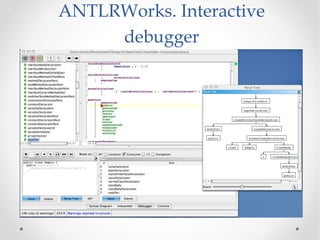
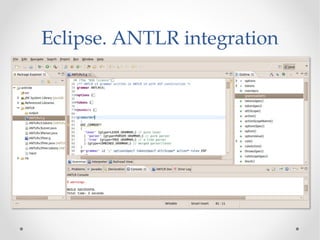
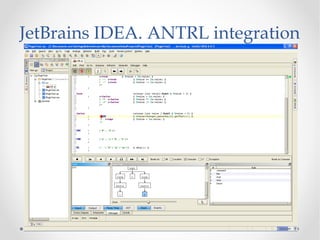
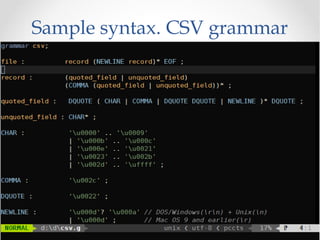

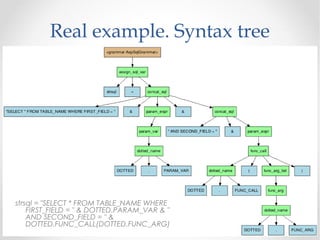
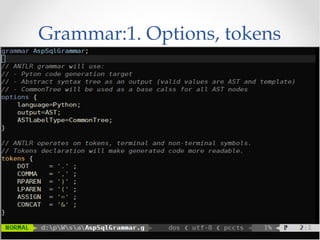
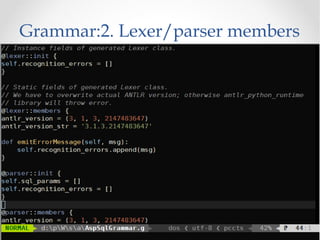
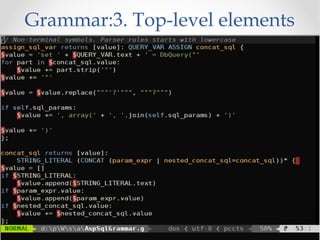


The document discusses the ANTLR tool, a parser generator that transforms grammars into source code for language recognition, highlighting its utility in parsing complex data and generating structured output such as abstract syntax trees. It contrasts ANTLR's capabilities with regular expressions, emphasizing ANTLR's advantages in error handling and detailed error messaging. Additionally, it lists various programming languages supported by ANTLR and provides examples of query syntax to demonstrate its practical applications.












































































