Downloaded 85 times


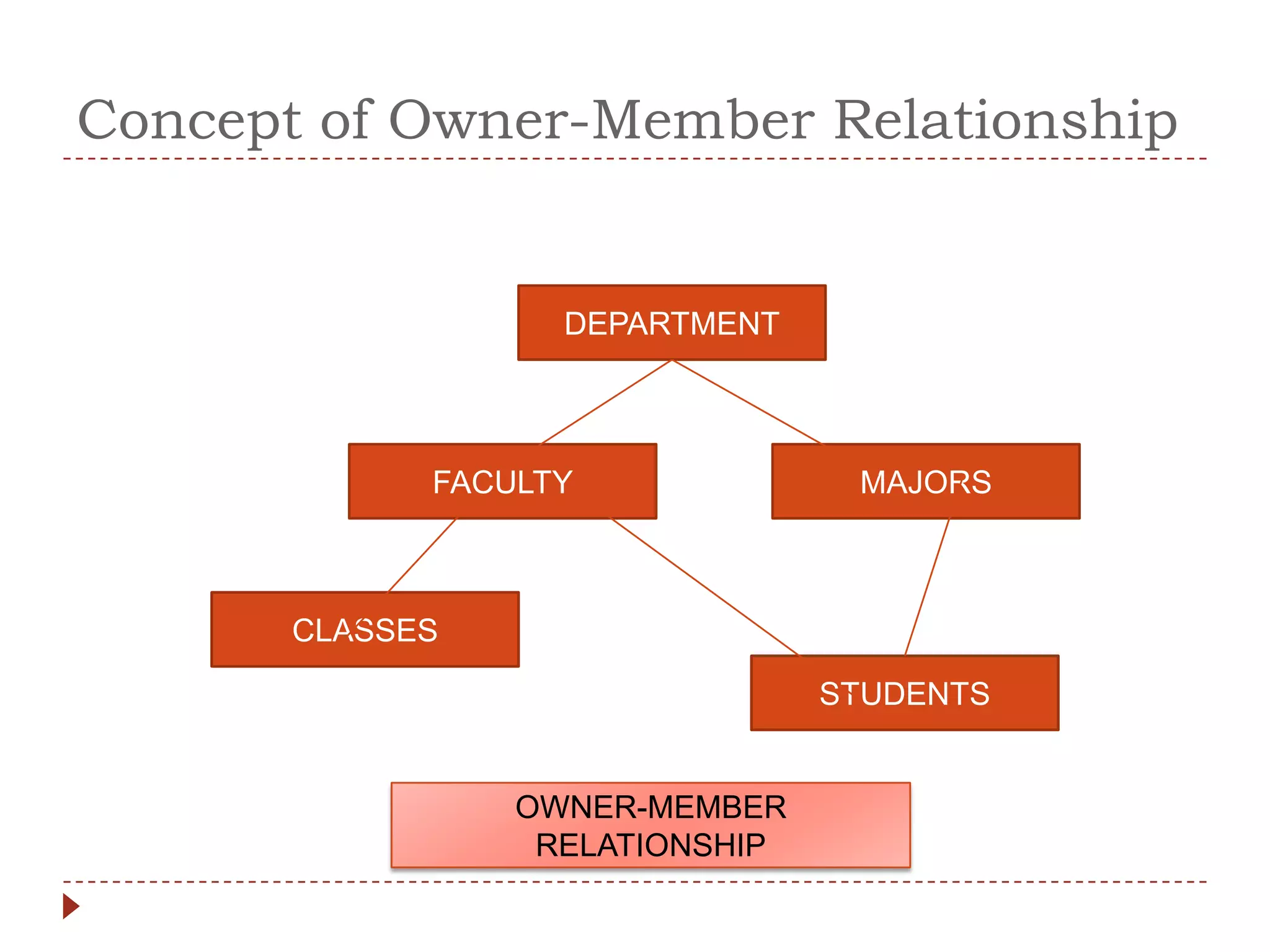

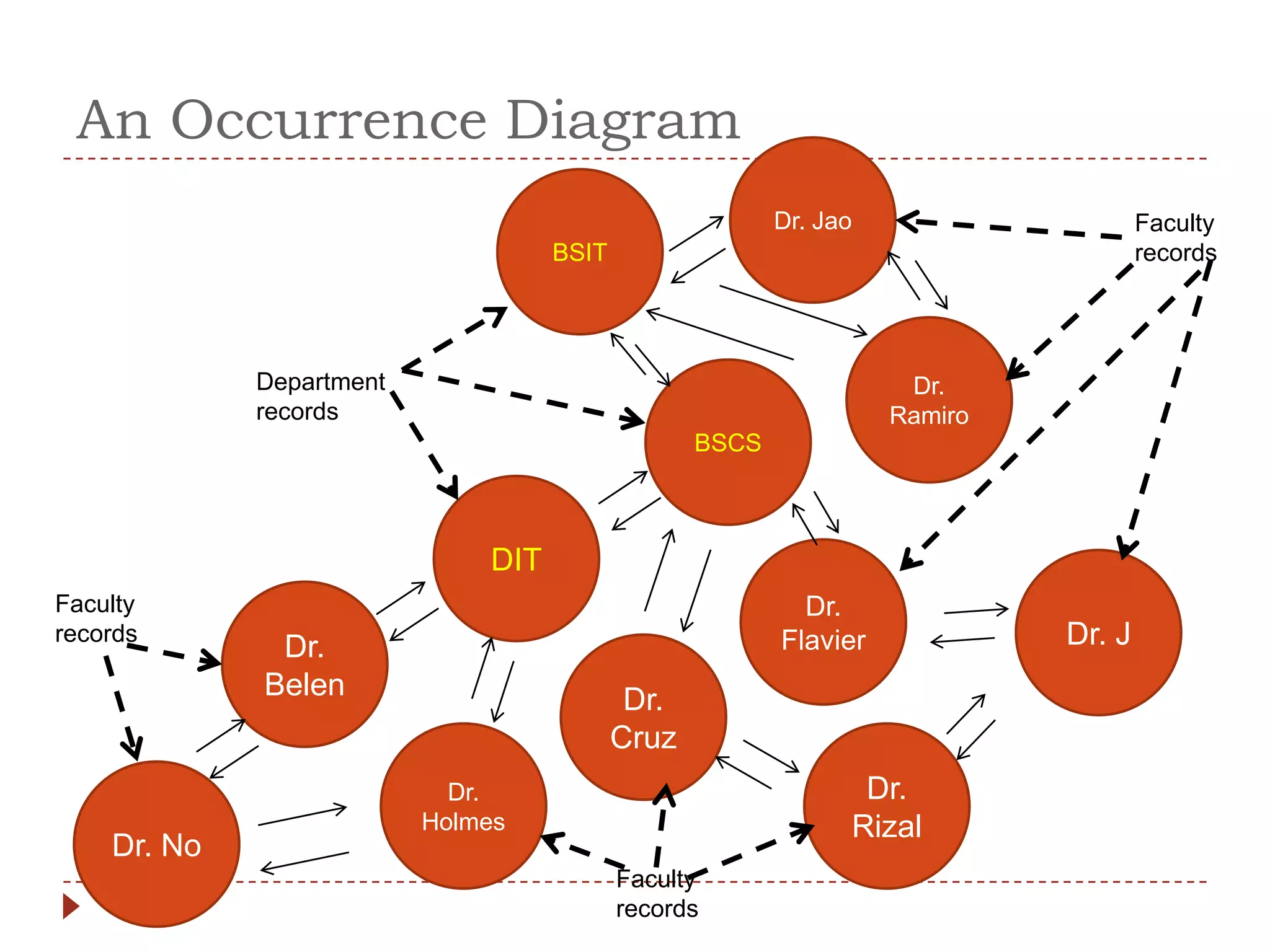


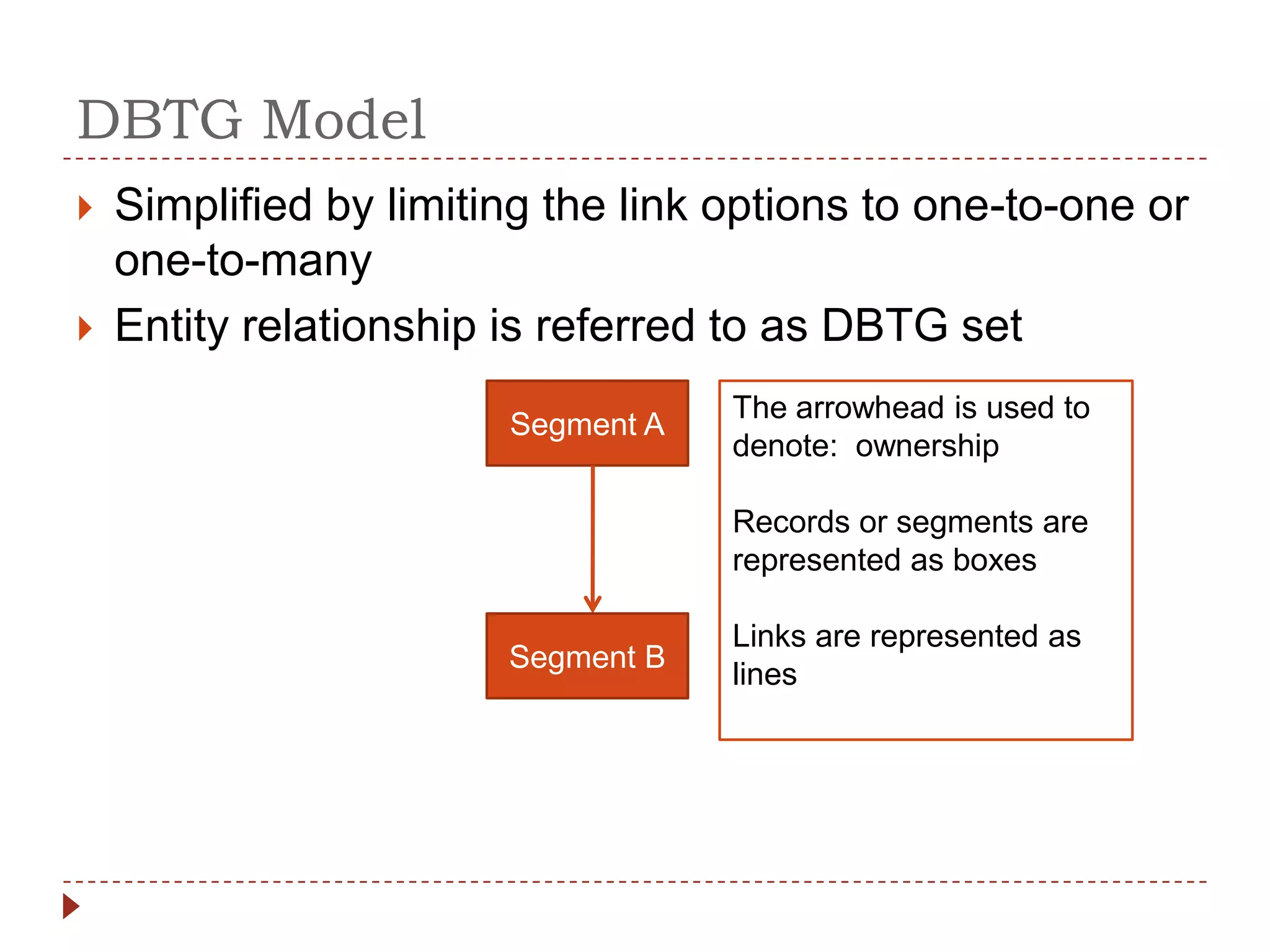
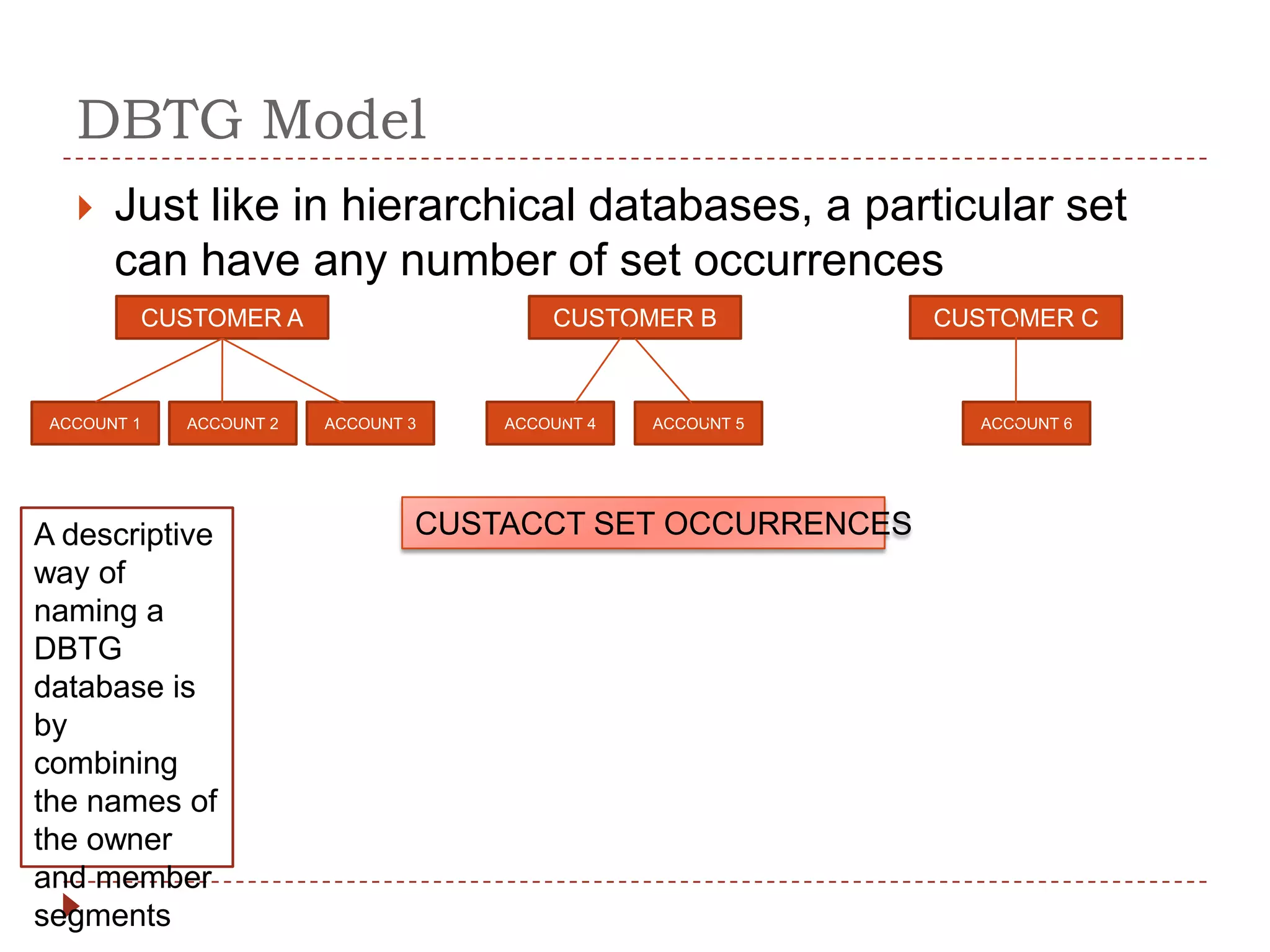
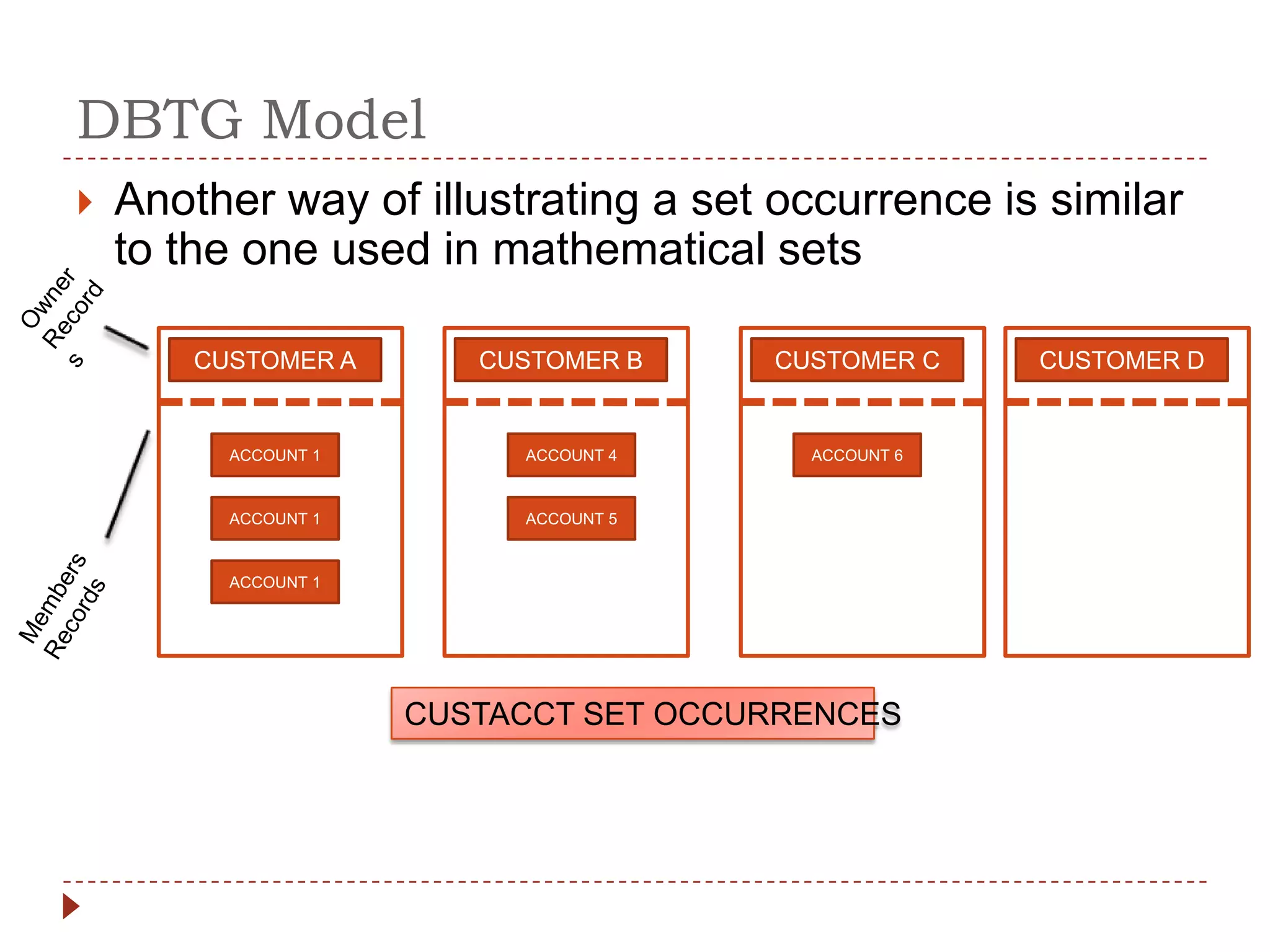
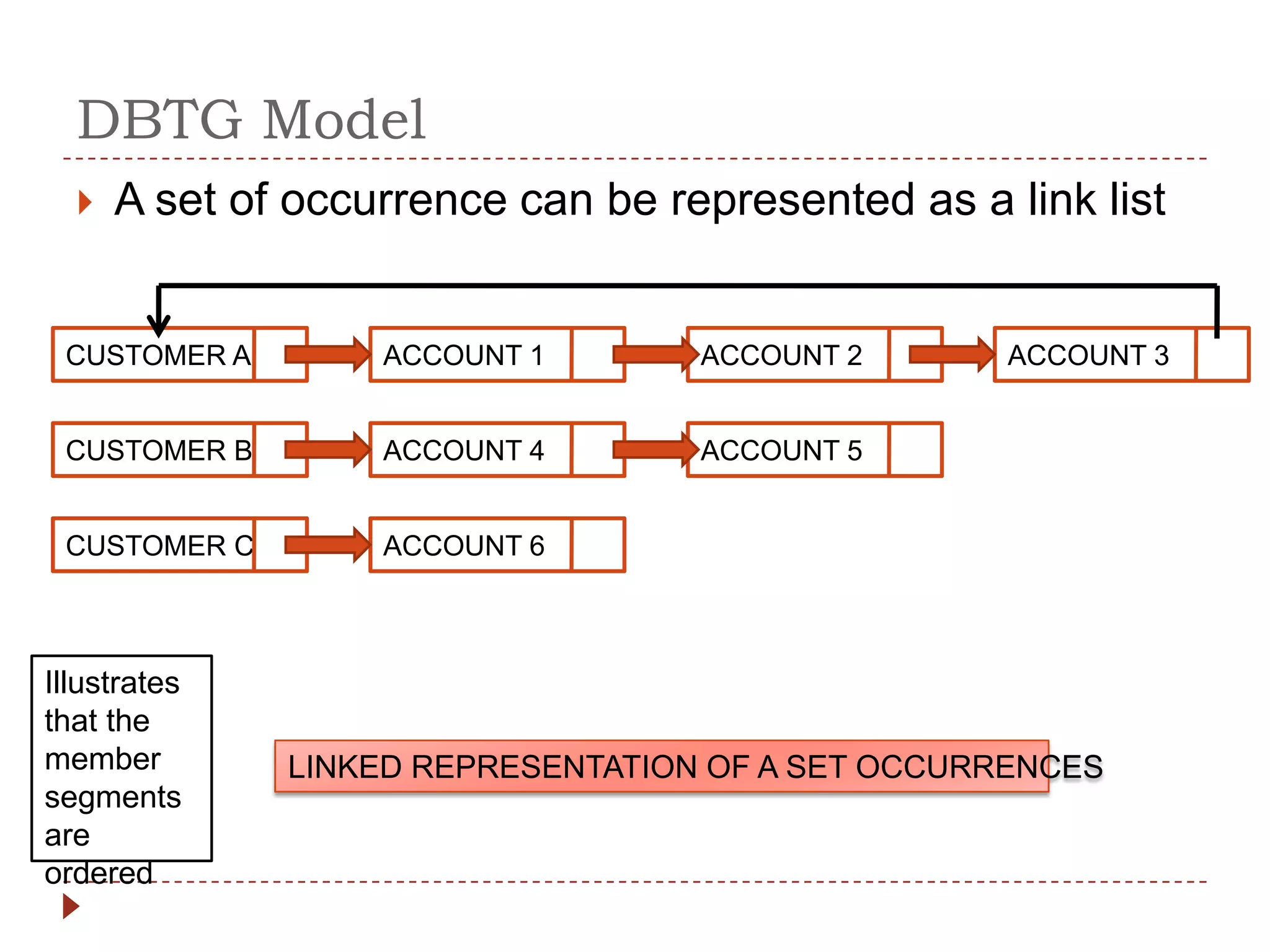
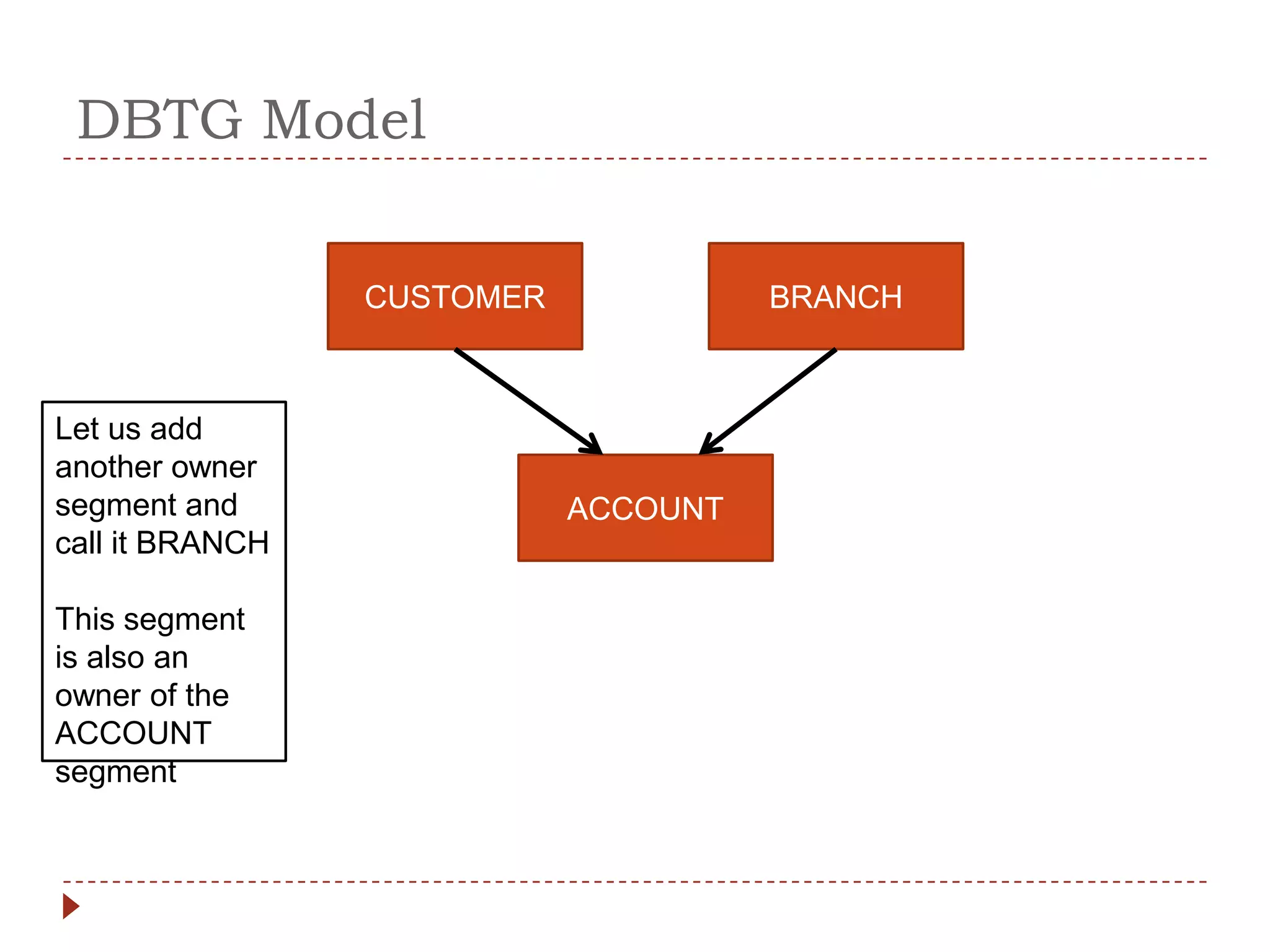
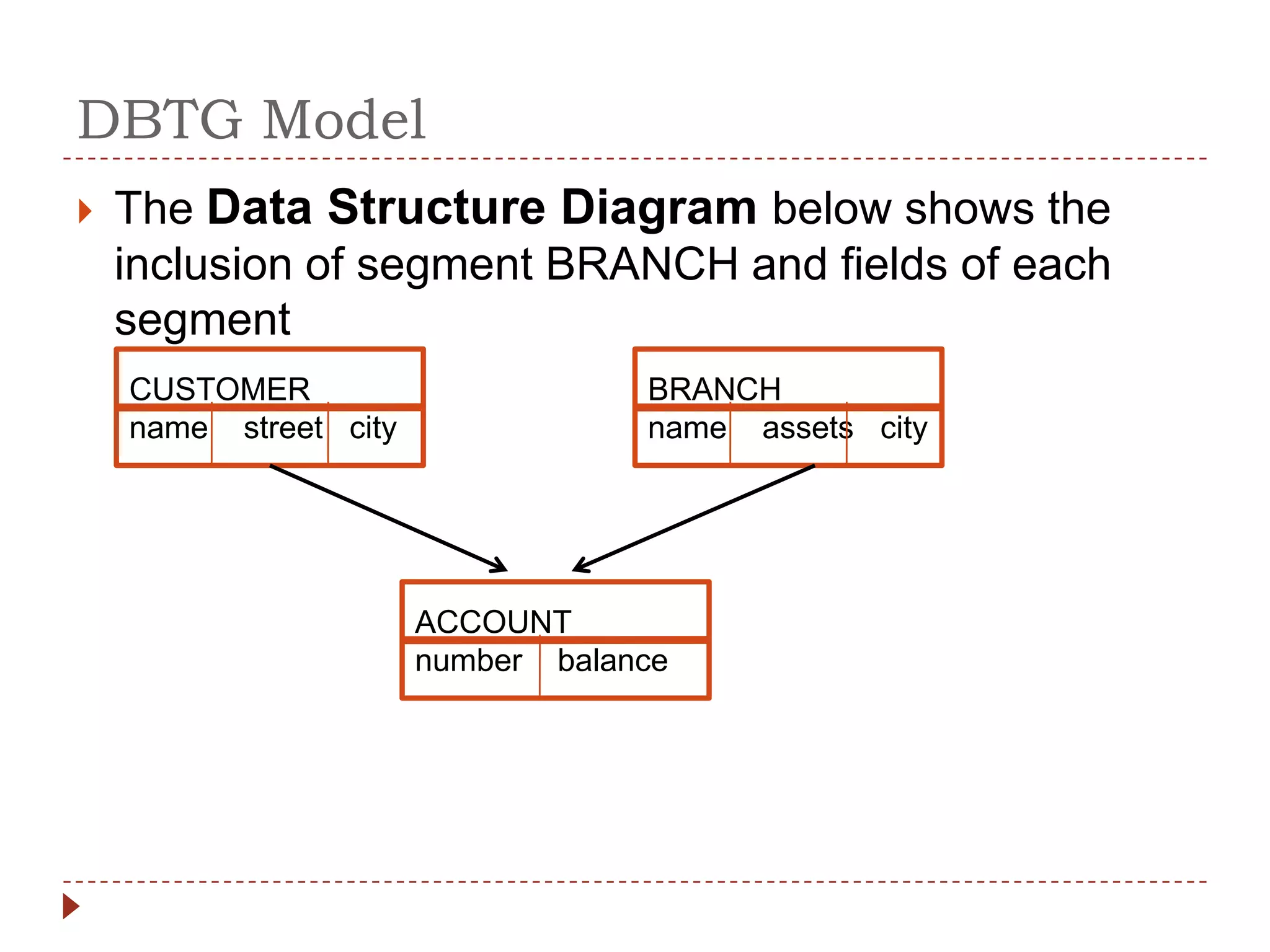
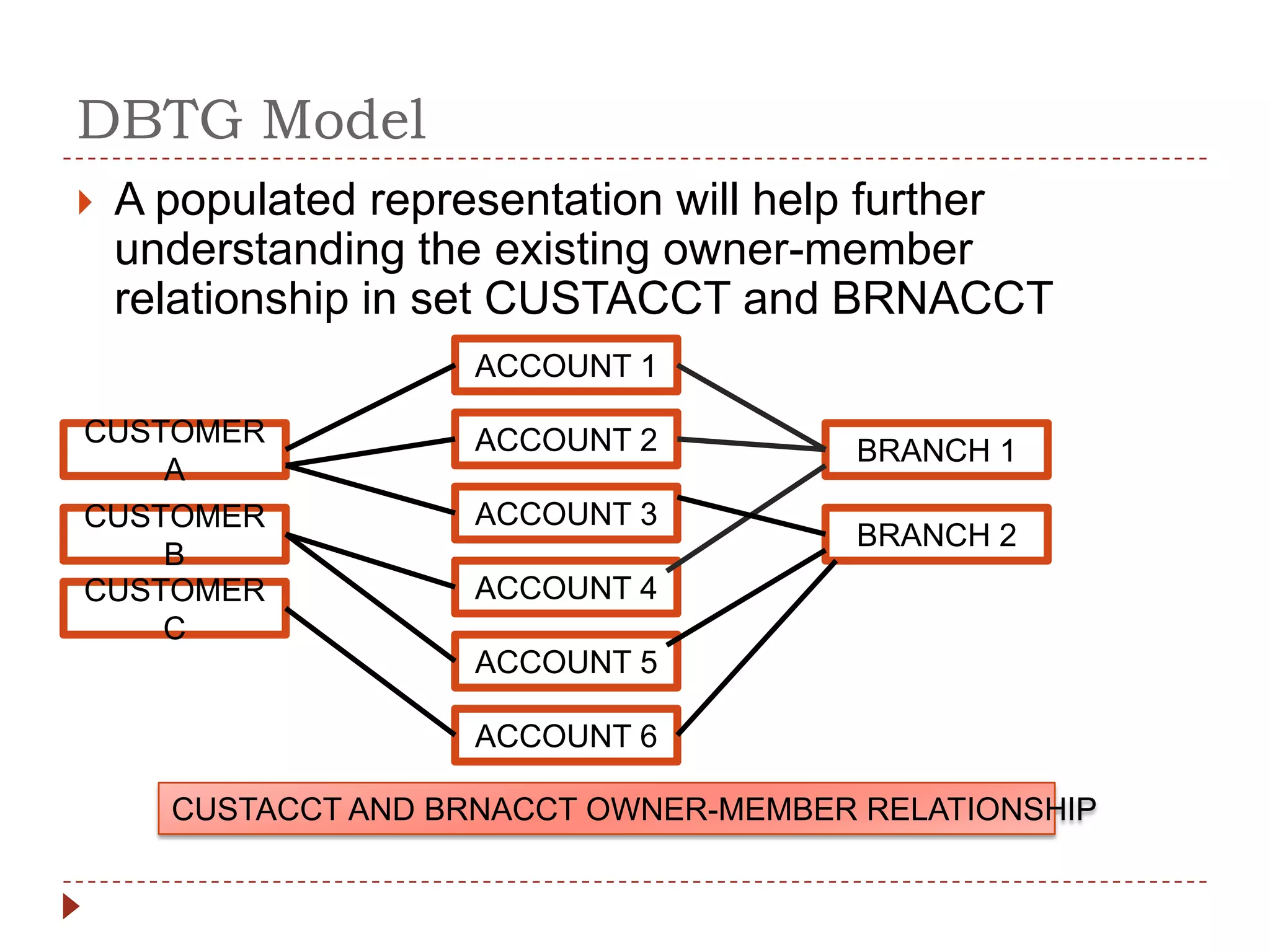


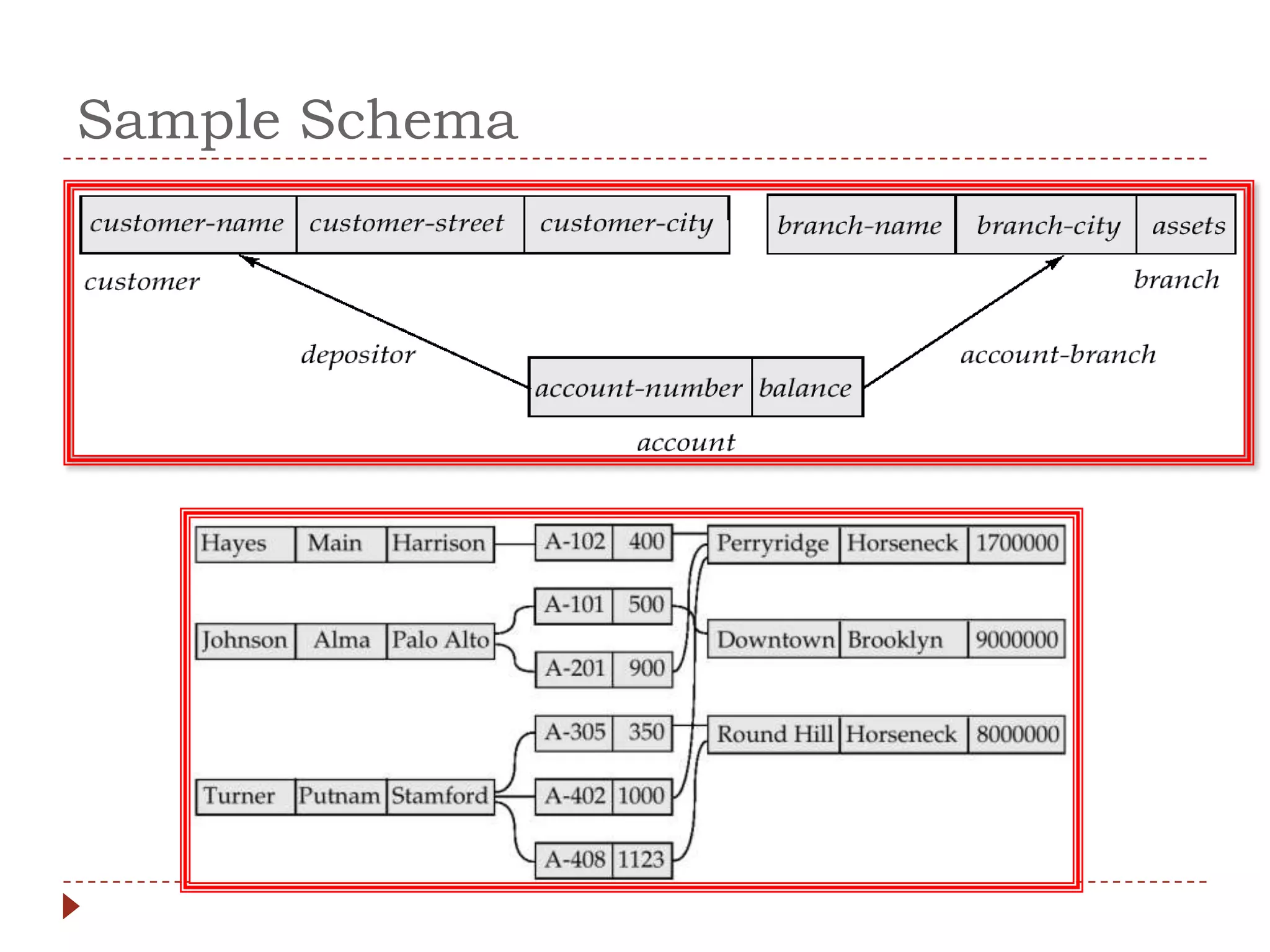



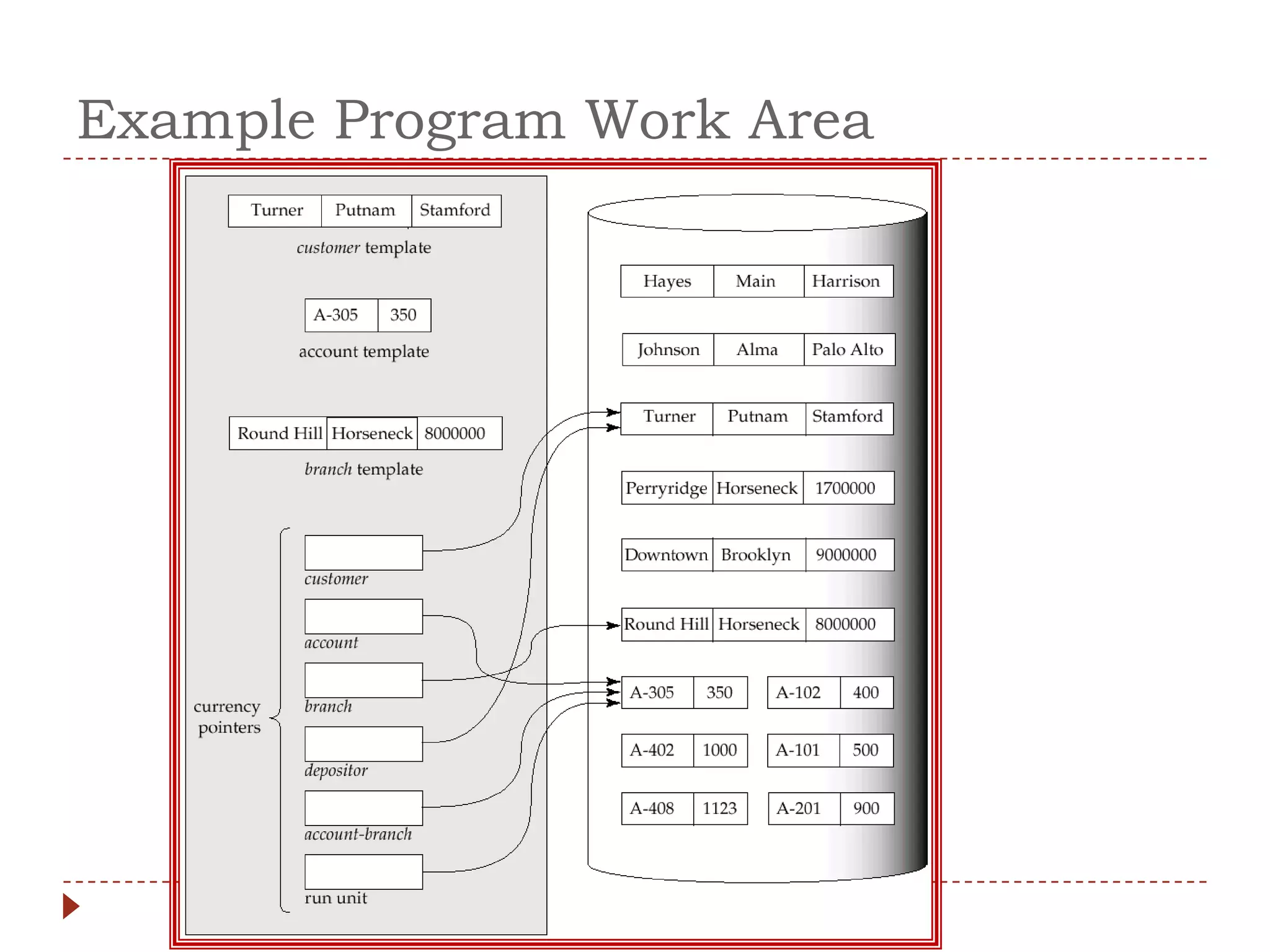







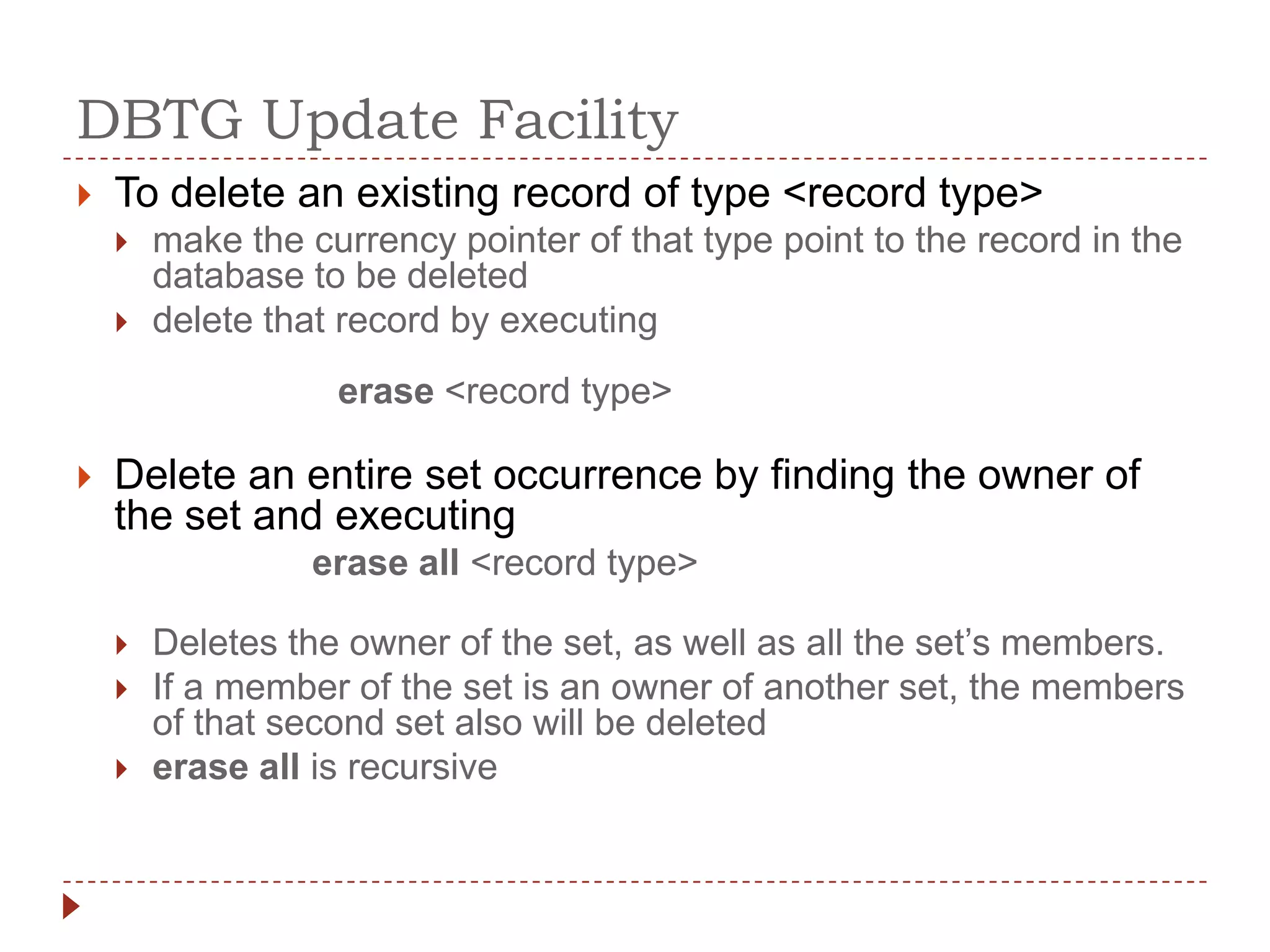







The document describes the network database model and CODASYL DBTG model. Some key points: - The network model uses a many-to-many relationship with owner and member records linked together. - The DBTG model simplified this to one-to-one and one-to-many relationships. It uses segments, sets, and links to represent records, relationships, and connections between records. - The DBTG model provides commands to retrieve, update, insert, and delete records as well as connect and disconnect them from sets. Programs access the database using templates, pointers, and status flags stored in a work area.






























































