Download as PDF, PPTX
















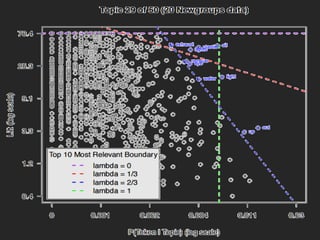





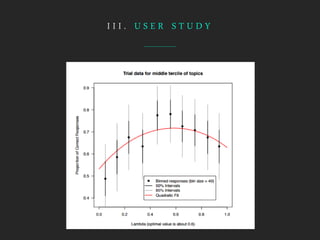
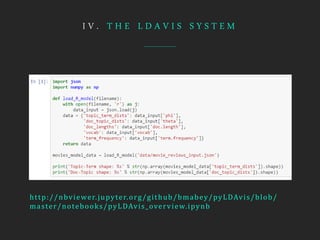



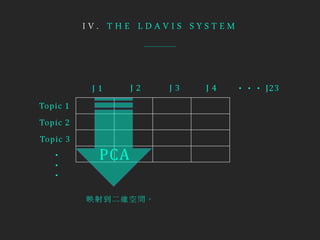



- LDAvis is an interactive visualization tool built using R and D3 to help users interpret topics estimated using Latent Dirichlet Allocation (LDA). - It aims to answer questions about the meaning of each topic, the prevalence of each topic, and how topics relate to each other. - The tool visualizes term relevance, topic prevalence, and inter-topic distances to help users understand the topics in a corpus.

































![Document Clustering using LDA | Haridas Narayanaswamy [Pramati]](https://cdn.slidesharecdn.com/ss_thumbnails/documentclusteringusinglda-190430091535-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Yang, Downey and Boyd-Graber 2015] Efficient Methods for Incorporating Knowl...](https://cdn.slidesharecdn.com/ss_thumbnails/sparse-constrained-lda-151024072334-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)




























