Download to read offline





![Copyright 2011 Trend Micro Inc.
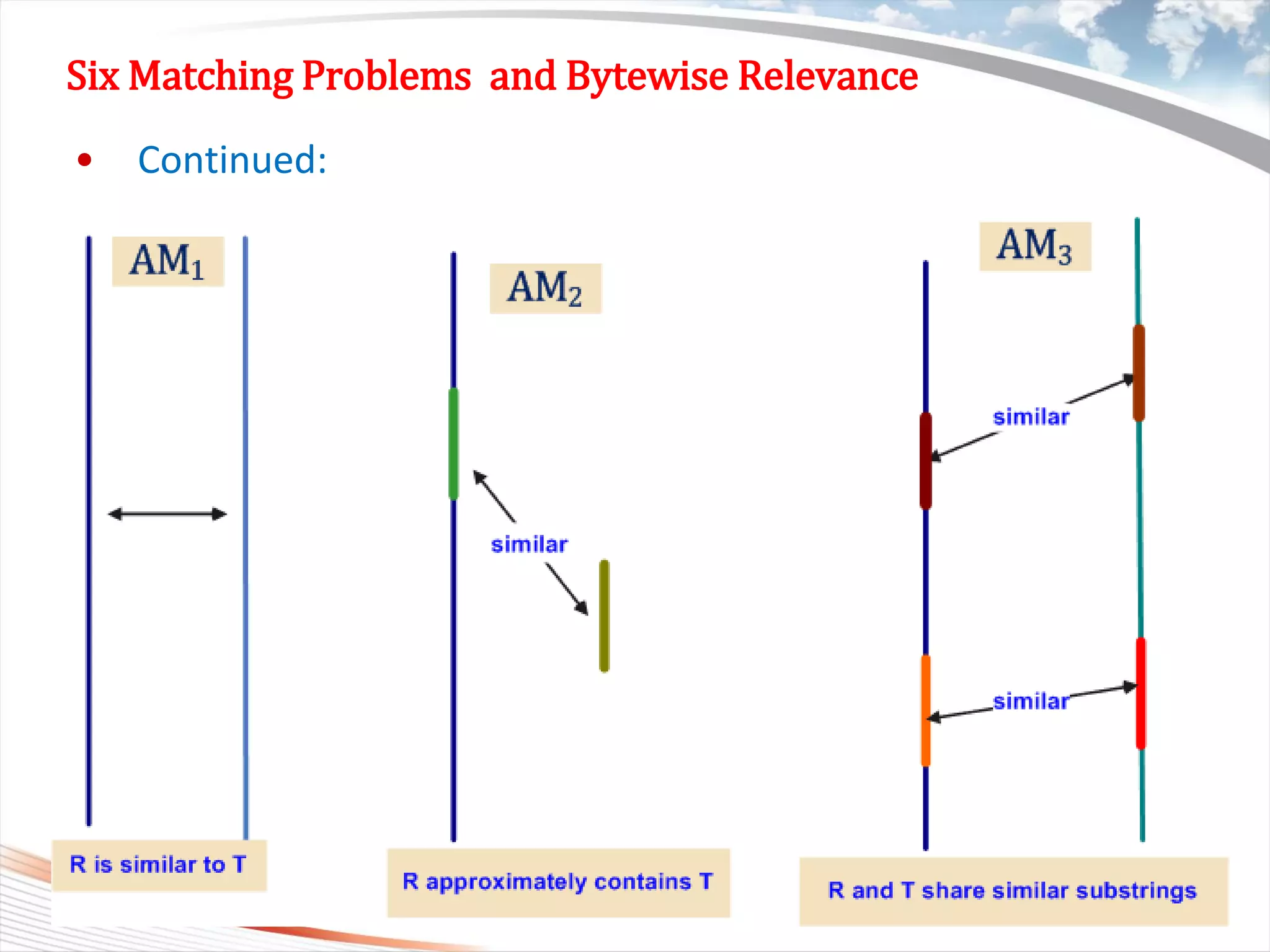
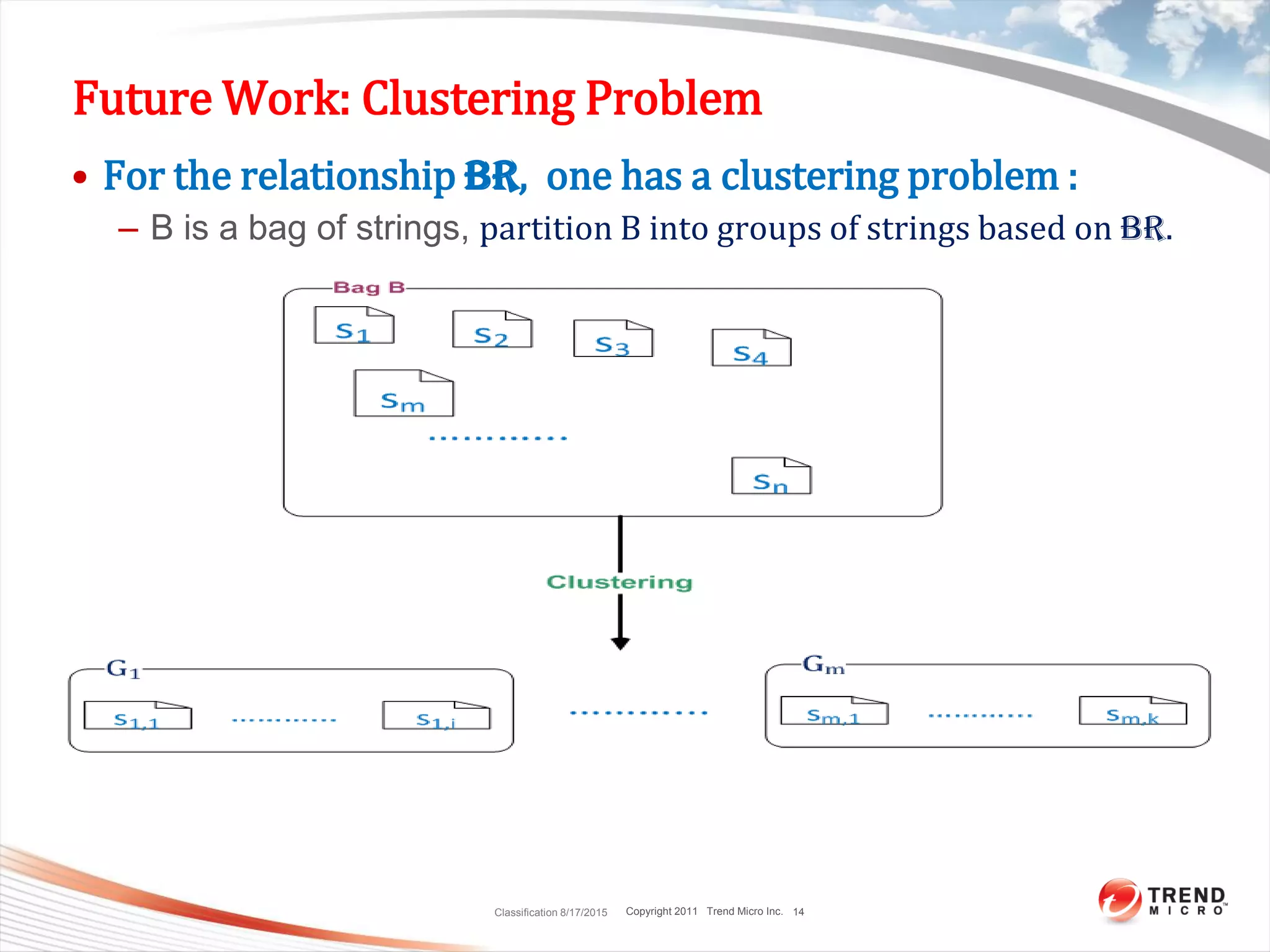
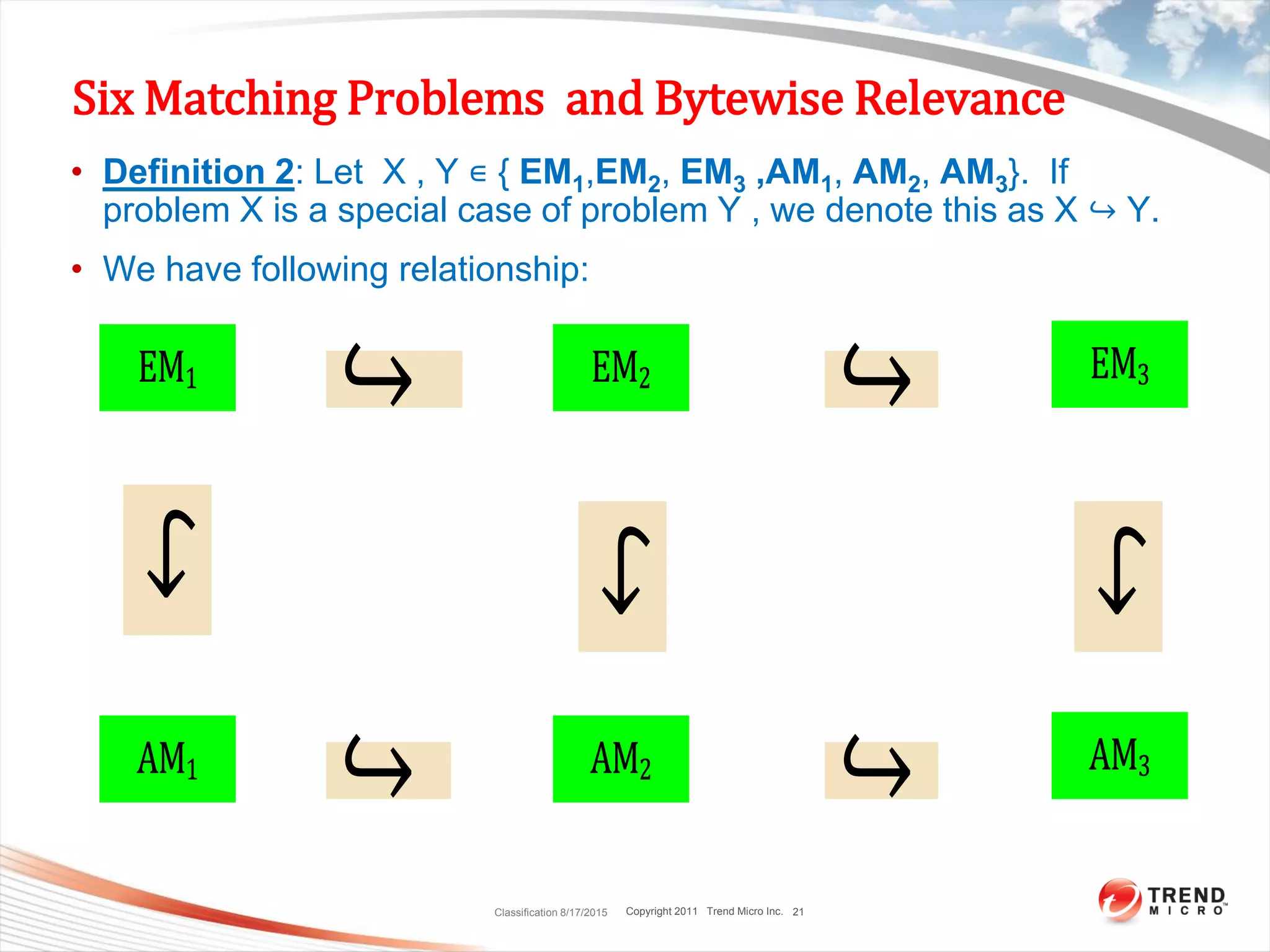
Six Matching Problems and Bytewise Relevance
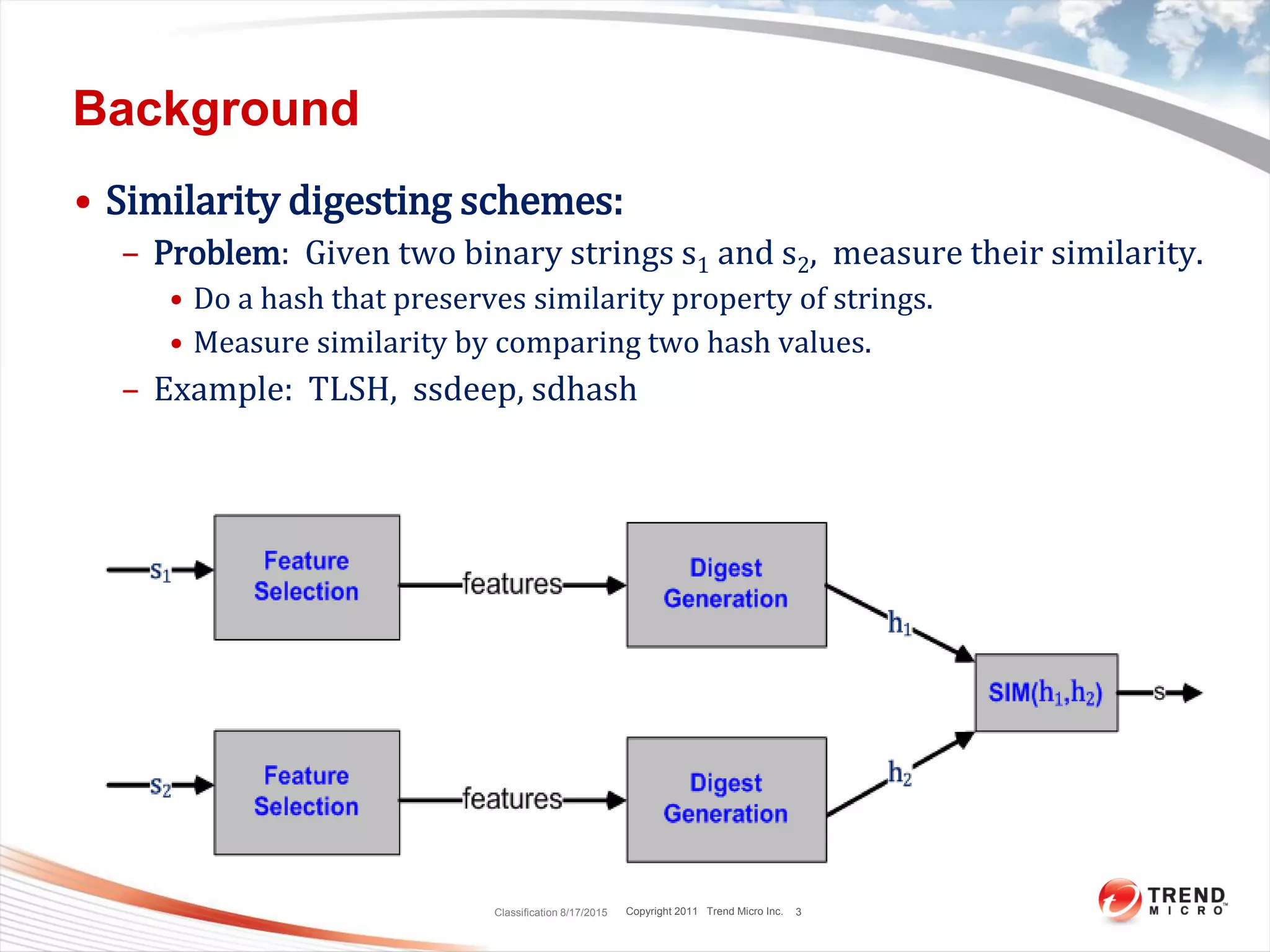
• Definition 1 : Given two strings R[1,..,n] and T[1,…,m], if one of
six cases is true, we say R and T are bytewise relevant.
– We denote this as BR(R,T)= 1, otherwise BR(R,T)= 0.
8](https://image.slidesharecdn.com/ray-speaks-at-dfrws-usa-2015-150818184624-lva1-app6891/75/Bytewise-approximate-matching-searching-and-clustering-8-2048.jpg)

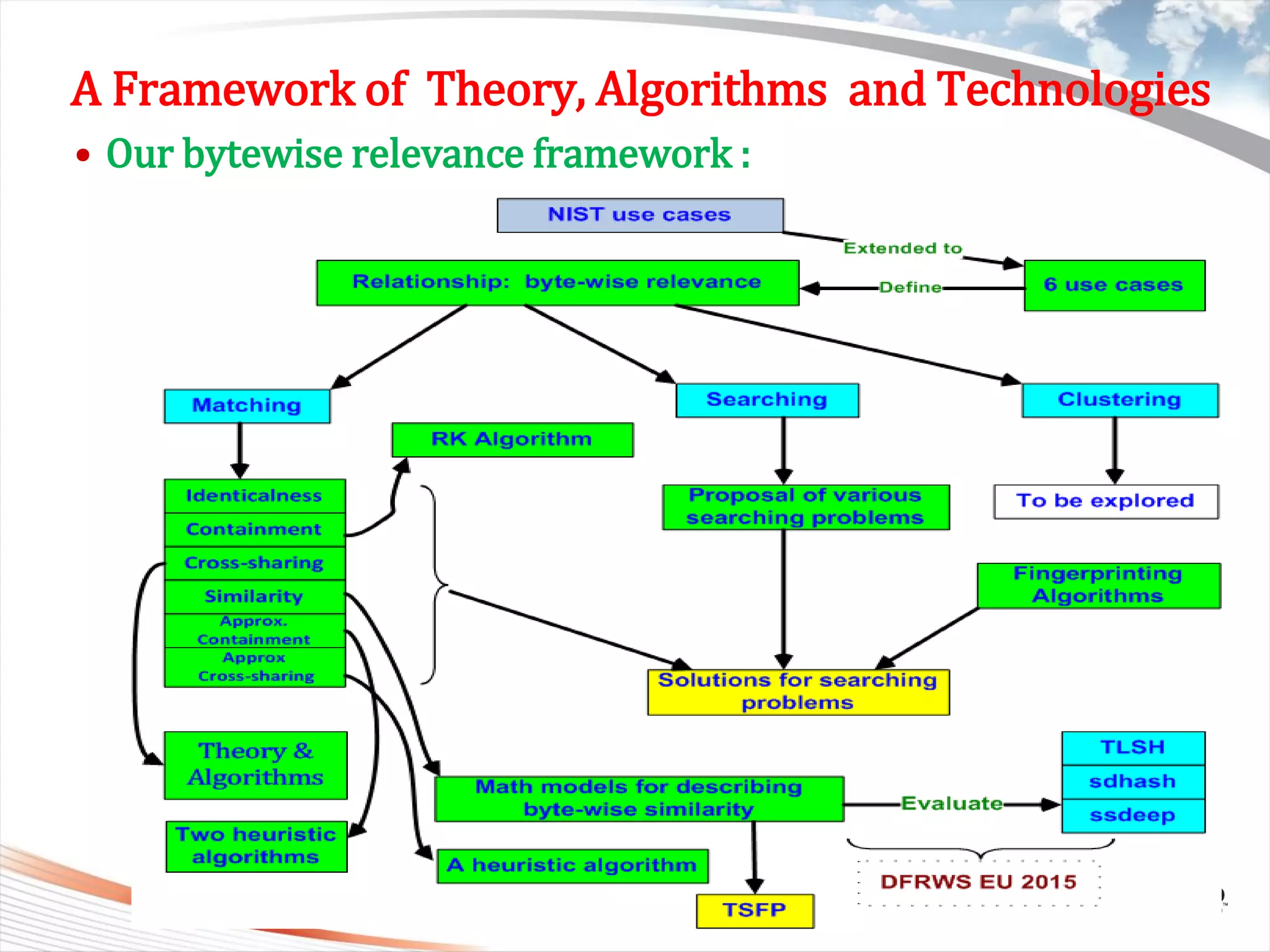

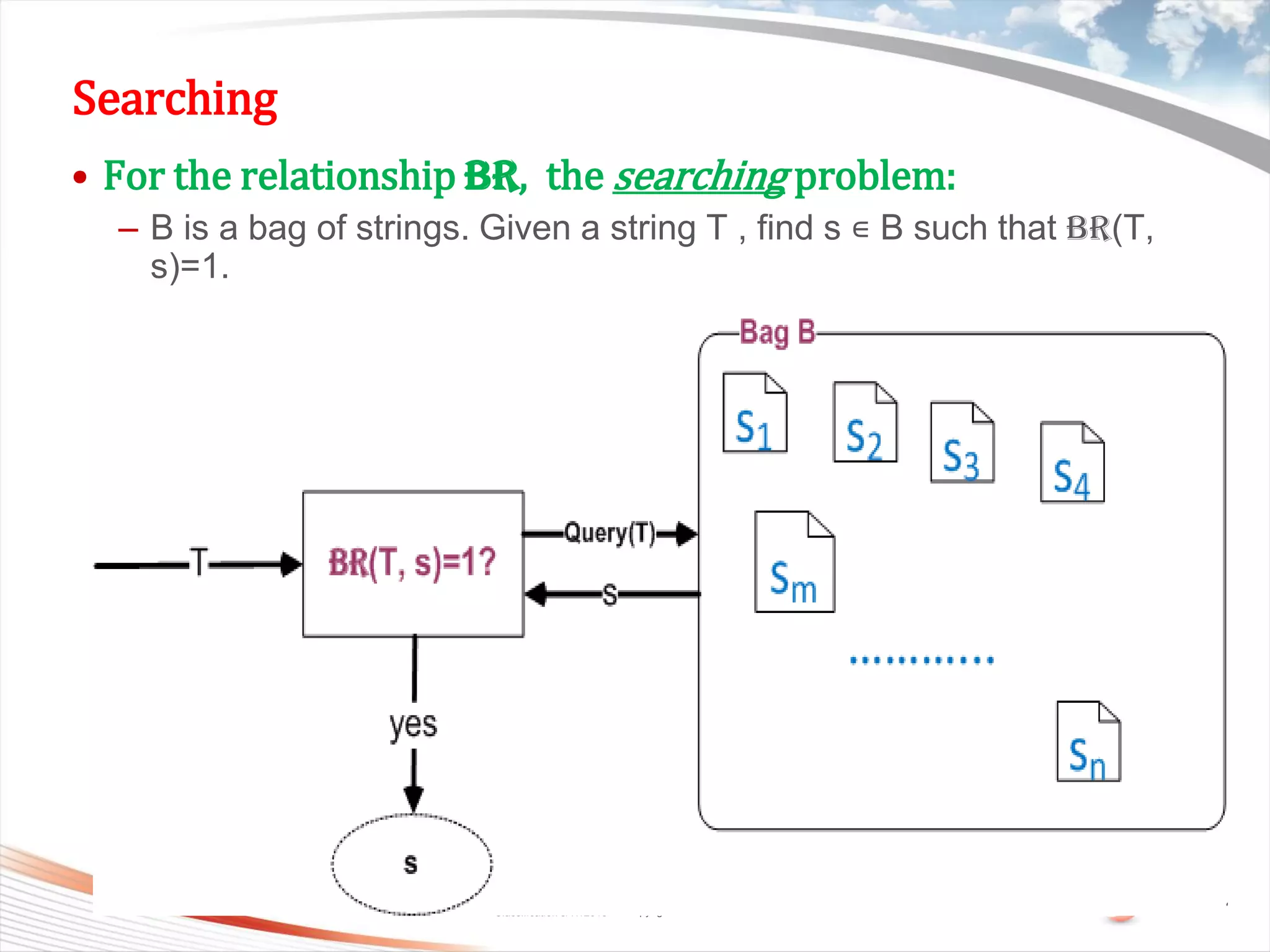




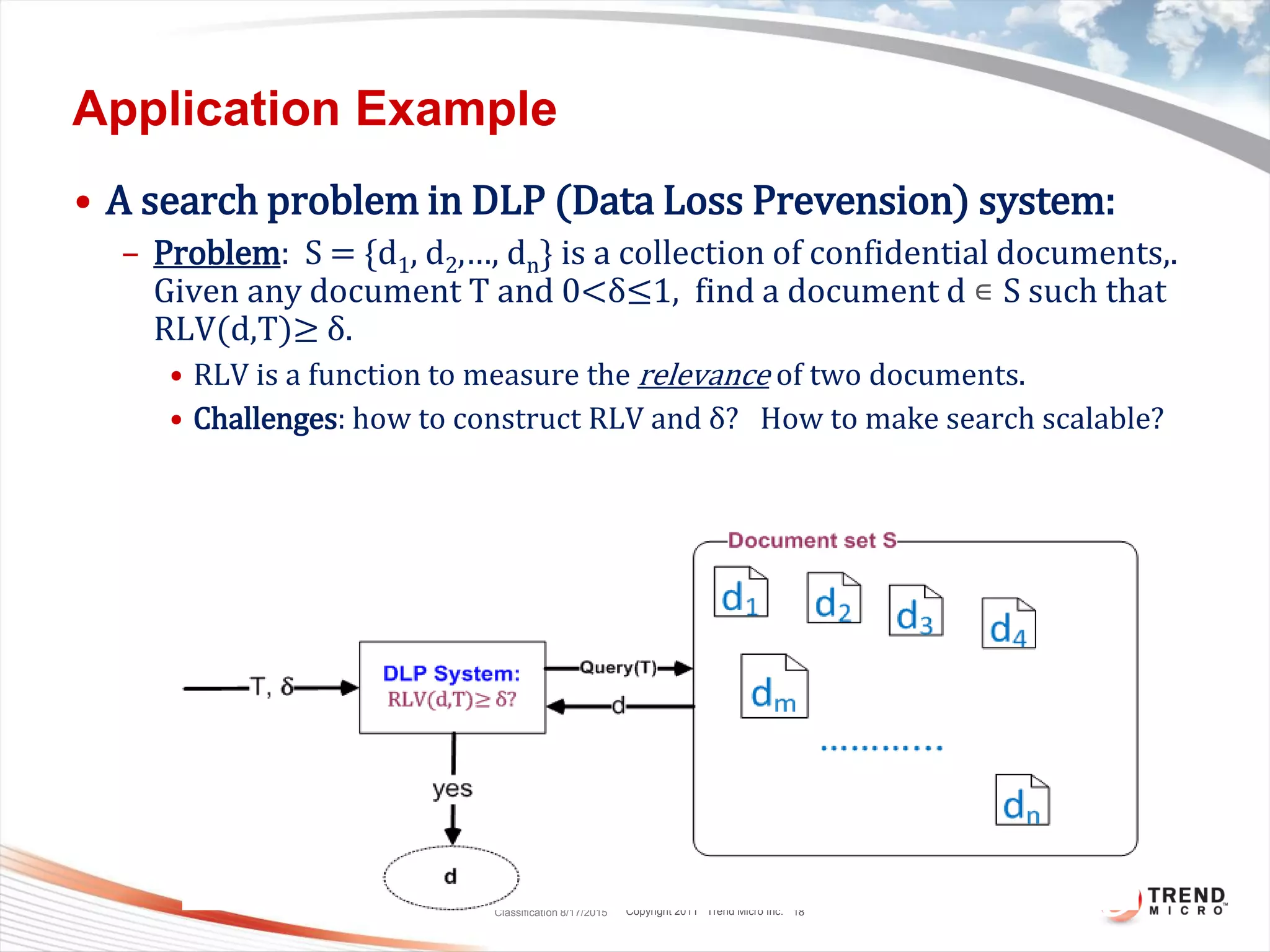
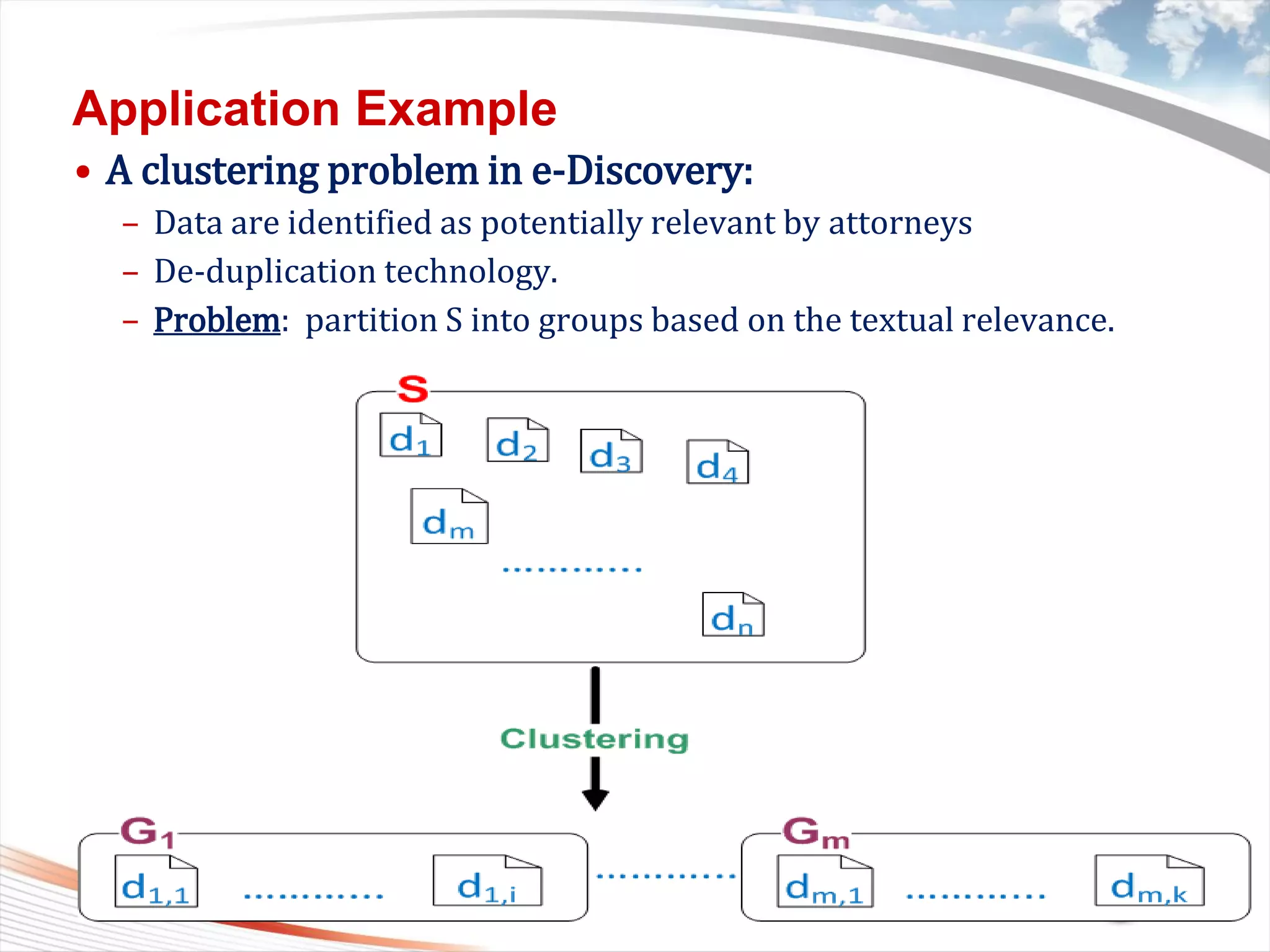
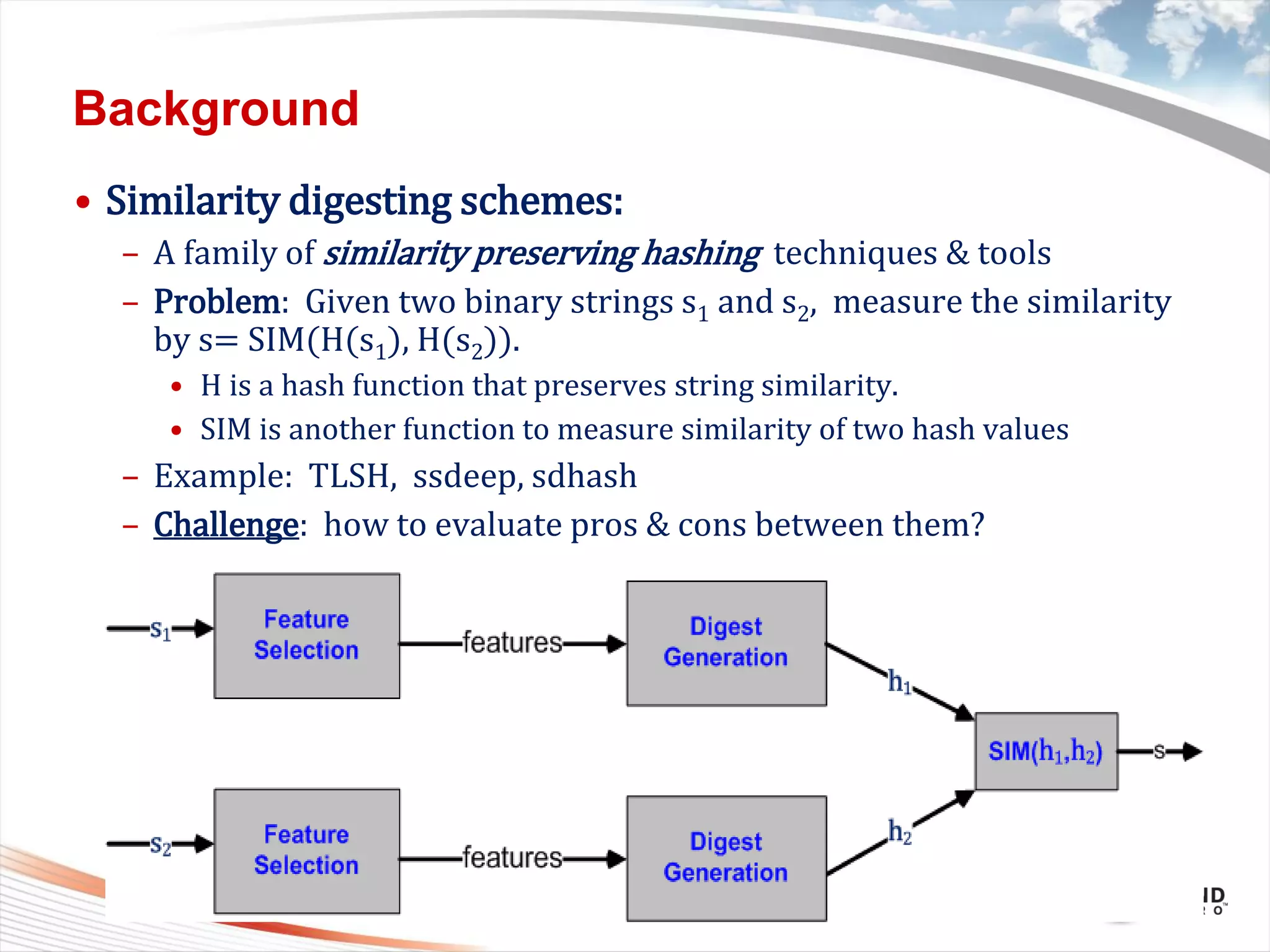

This document discusses bytewise approximate matching, searching, and clustering. It defines six matching problems - identicalness, containment, cross-sharing, similarity, approximate containment, and approximate cross-sharing. A framework is proposed that uses bytewise relevance to define matching, searching, and clustering problems and solutions. Current and future work includes algorithms, tools, and applications for approximate matching in domains like malware analysis, plagiarism detection, and digital forensics.


































































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







