Download to read offline


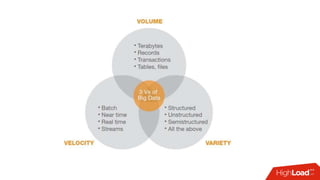
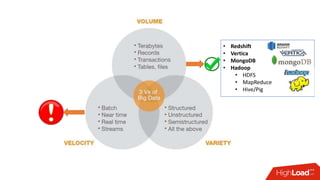


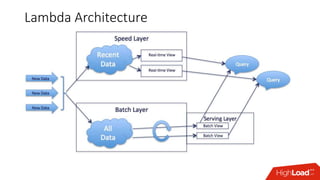

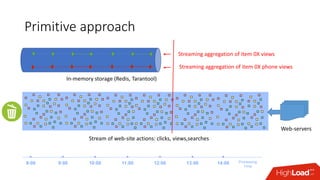
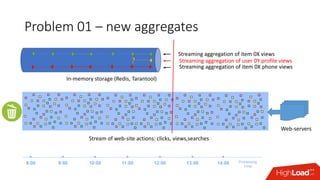
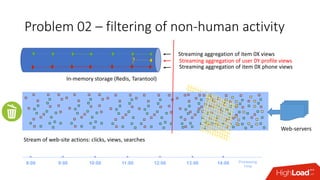
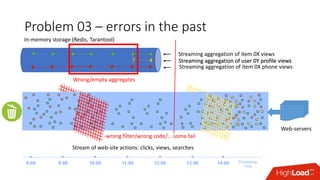
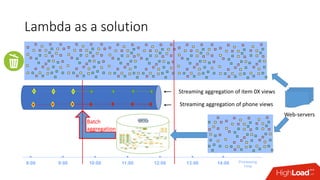
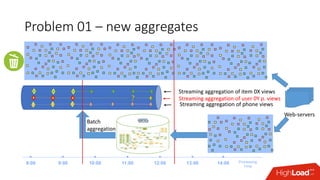
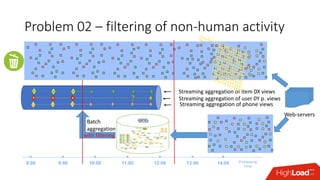
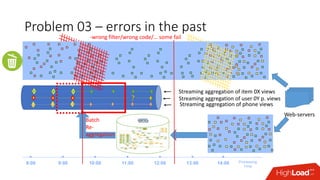
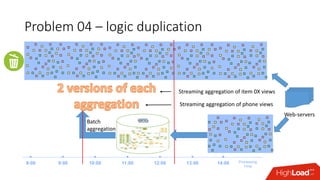
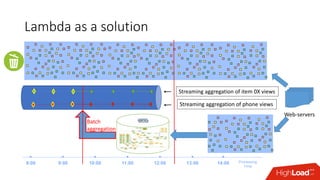

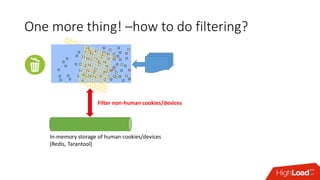
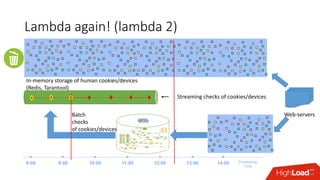



Документ обсуждает архитектуру Lambda для реального времени аналитики, выделяя ее риски и преимущества. Основное внимание уделяется различиям между потоковой агрегацией и пакетной обработкой данных, а также проблемам, связанным с фильтрацией не человечьей активности и обработкой ошибок. В заключение описаны недостатки архитектуры Lambda, включая дублирование логики и необходимость упрощения процессов в скоростном слое.












































































