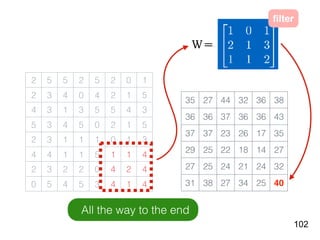
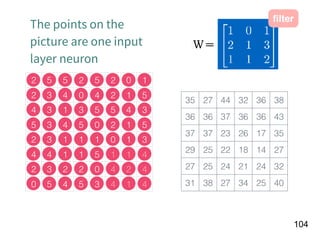
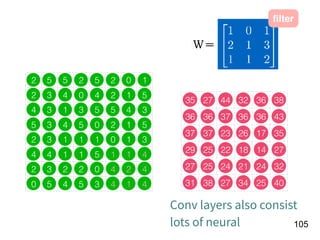
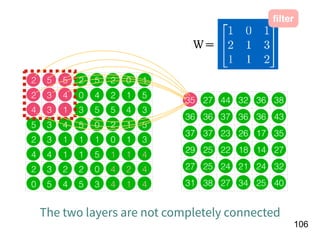
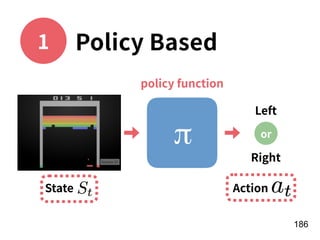
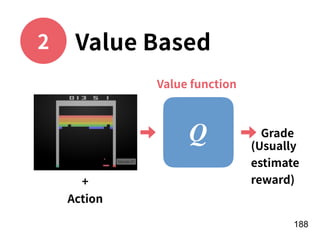
Download as PDF, PPTX


















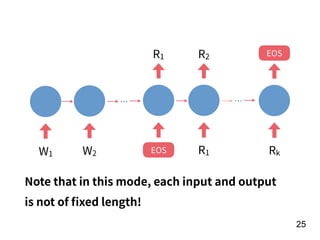
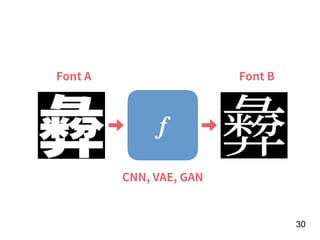
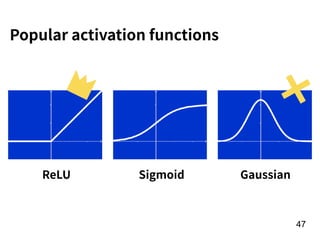
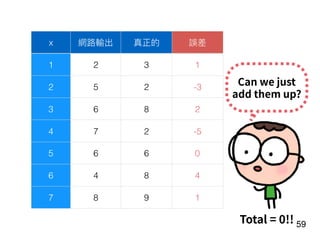
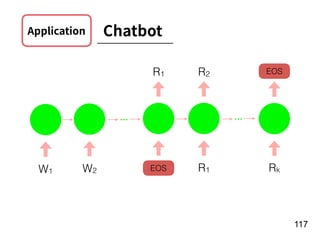
![!22
Player
preformance
in the year of
t-1
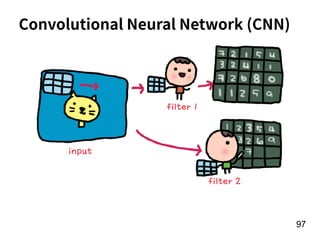
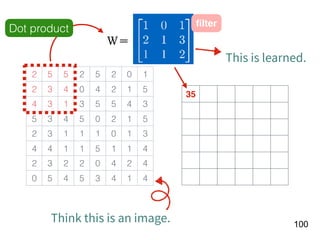
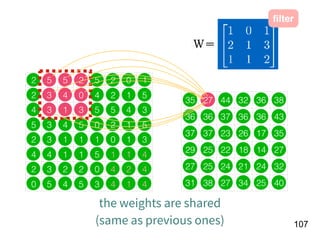
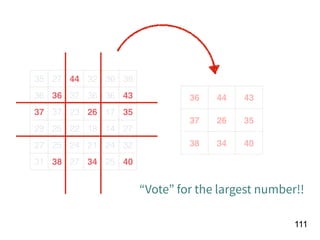
[Age, G, PA, AB, R, H, 2B, 3B, HR,
RBI, SB, BB, SO, OPS+, TB]
15 features!
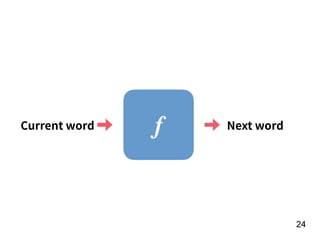
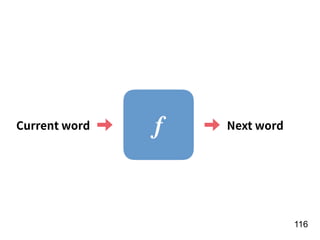
f
Number of
homers in the
year of t
RNN](https://image.slidesharecdn.com/deeplearninganddesignthinking-180509111347/85/Deep-Learning-and-Design-Thinking-22-320.jpg)




















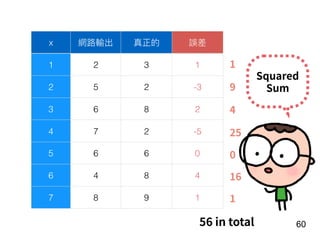

































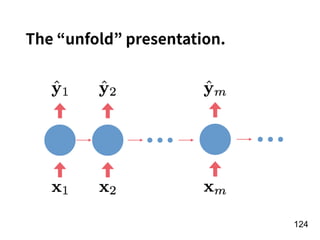
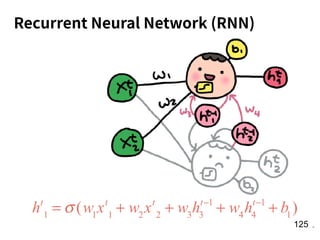
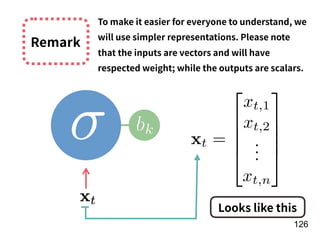
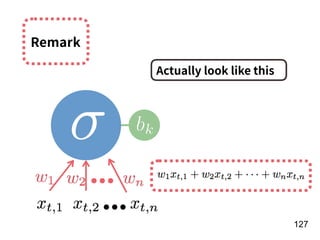
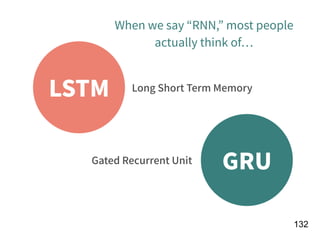

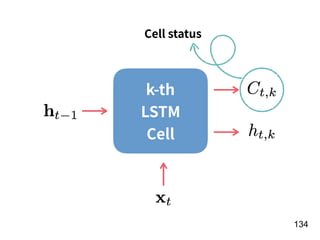

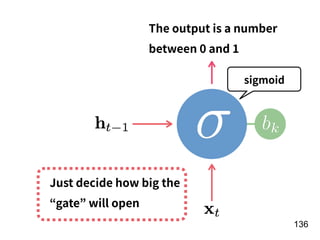

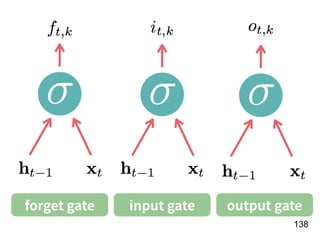
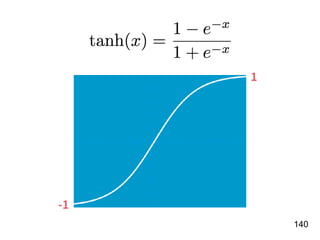
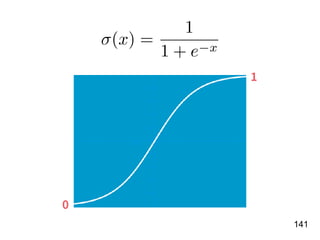
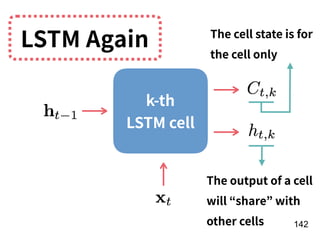
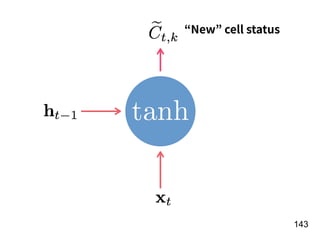
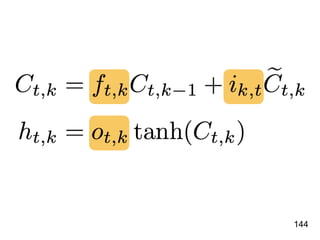



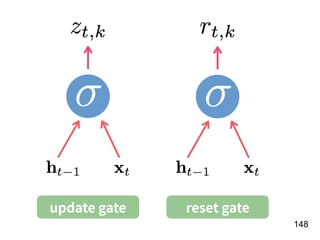
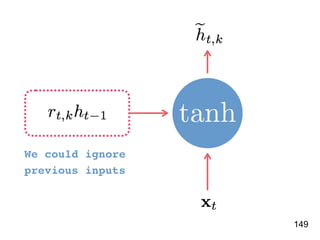
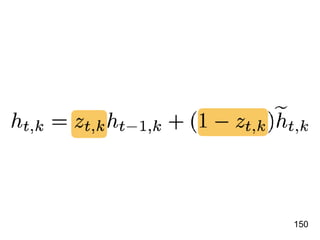




![!156
Year t-1
[Age, G, PA, AB, R, H, 2B, 3B, HR,
RBI, SB, BB, SO, OPS+, TB]
15 features
Number of
homers in the
year of t
f](https://image.slidesharecdn.com/deeplearninganddesignthinking-180509111347/85/Deep-Learning-and-Design-Thinking-156-320.jpg)



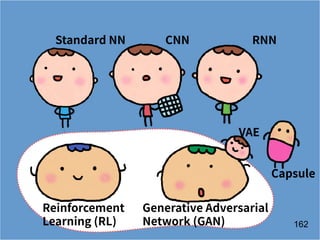
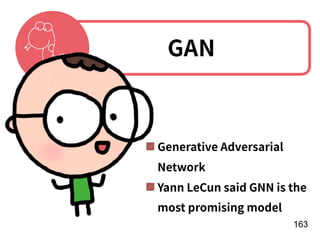


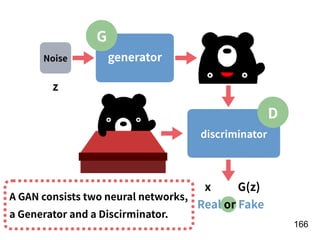
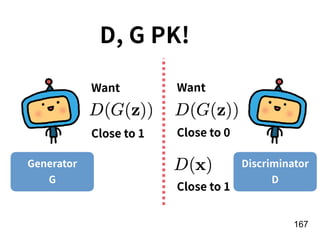

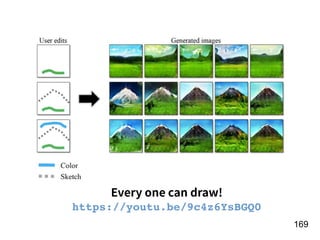








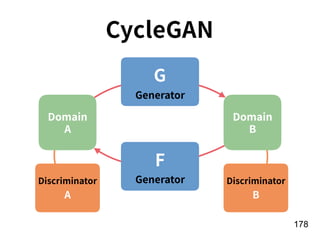




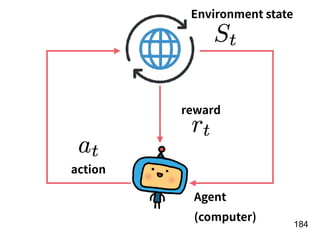







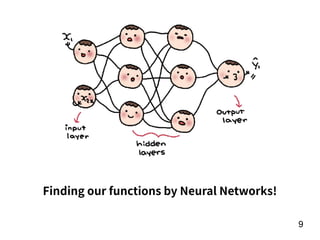
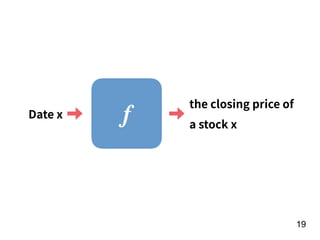
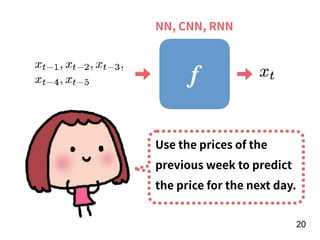
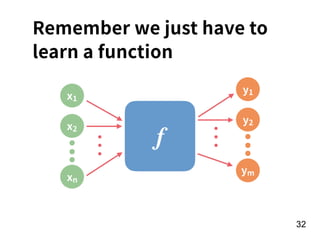
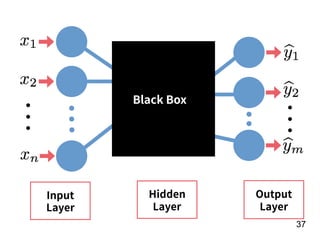
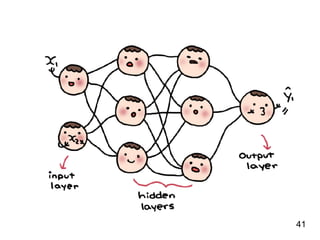
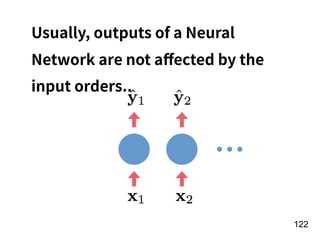
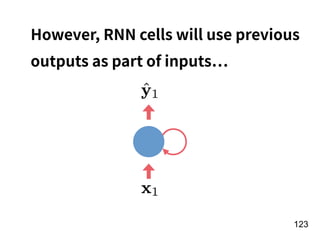
The document discusses the application of deep learning techniques in transforming real-world problems into functions that neural networks can solve. It covers various aspects of neural networks, including their structures, training methods, types like CNNs and RNNs, and key concepts like gradient descent and loss functions. Additionally, it highlights practical applications such as image recognition and chatbots.
![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 手把手的深度學實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidedlfinal1216-171213041058-thumbnail.jpg?width=640&height=640&fit=bounds)
![[系列活動] 手把手的深度學習實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharestepbystepdl-161213072731-thumbnail.jpg?width=640&height=640&fit=bounds)

![[系列活動] 一日搞懂生成式對抗網路](https://cdn.slidesharecdn.com/ss_thumbnails/gan-170813004356-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[한국어] Safe Multi-Agent Reinforcement Learning for Autonomous Driving](https://cdn.slidesharecdn.com/ss_thumbnails/safemultiagentrlforautonomousedriving4-170508165059-thumbnail.jpg?width=640&height=640&fit=bounds)
































![[數學、邏輯與人生] 05 數,三聲數](https://cdn.slidesharecdn.com/ss_thumbnails/05-161102062443-thumbnail.jpg?width=640&height=640&fit=bounds)
![[數學軟體應用] 05 HTML+CSS](https://cdn.slidesharecdn.com/ss_thumbnails/05htmlcss-161024122309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[數學、邏輯與人生] 03 集合和數學歸納法](https://cdn.slidesharecdn.com/ss_thumbnails/03-161019135315-thumbnail.jpg?width=640&height=640&fit=bounds)
![[數學、邏輯與人生] 01 基本邏輯和真值表](https://cdn.slidesharecdn.com/ss_thumbnails/01-161005134119-thumbnail.jpg?width=640&height=640&fit=bounds)




![[數學、邏輯與人生] 00 課程簡介](https://cdn.slidesharecdn.com/ss_thumbnails/00-160923023209-thumbnail.jpg?width=640&height=640&fit=bounds)


















