Recommended
PDF
第四回 全日本CV勉強会スライド(MOTS: Multi-Object Tracking and Segmentation)
PPTX
物体検出フレームワークMMDetectionで快適な開発
PPTX
[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
PPTX
【DL輪読会】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Dri...
PDF
PDF
【DL輪読会】Patches Are All You Need? (ConvMixer)
PPTX
近年のHierarchical Vision Transformer
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
PDF
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PPTX
Image Retrieval Overview (from Traditional Local Features to Recent Deep Lear...
PDF
kaggle Freesound Audio Tagging 2019 4th place solution
PDF
(2022年3月版)深層学習によるImage Classificaitonの発展
PPTX
Humpback whale identification challenge反省会
PDF
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本
PDF
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
PDF
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
PPTX
PPTX
【論文読み会】Alias-Free Generative Adversarial Networks(StyleGAN3)
PDF
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
PPTX
[DL輪読会]When Does Label Smoothing Help?
PDF
ドラレコ + CV = 地図@Mobility Technologies
PDF
Anomaly detection 系の論文を一言でまとめた
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
PDF
Kaggle勉強会: RSNA STR pulmonary_embolism_detection
PDF
【CVPR 2020 メタサーベイ】Medical, Biological and Cell Microscopy
More Related Content
PDF
第四回 全日本CV勉強会スライド(MOTS: Multi-Object Tracking and Segmentation)
PPTX
物体検出フレームワークMMDetectionで快適な開発
PPTX
[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
PPTX
【DL輪読会】DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Dri...
PDF
PDF
【DL輪読会】Patches Are All You Need? (ConvMixer)
PPTX
近年のHierarchical Vision Transformer
What's hot
PPTX
これからの Vision & Language ~ Acadexit した4つの理由
PDF
PPTX
[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
PDF
Deep Learningによる画像認識革命 ー歴史・最新理論から実践応用までー
PDF
PPTX
Image Retrieval Overview (from Traditional Local Features to Recent Deep Lear...
PDF
kaggle Freesound Audio Tagging 2019 4th place solution
PDF
(2022年3月版)深層学習によるImage Classificaitonの発展
PPTX
Humpback whale identification challenge反省会
PDF
深層学習の判断根拠を理解するための 研究とその意義 @PRMU 2017熊本
PDF
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
PDF
SSII2019TS: Shall We GANs? ~GANの基礎から最近の研究まで~
PPTX
PPTX
【論文読み会】Alias-Free Generative Adversarial Networks(StyleGAN3)
PDF
PDF
モデルアーキテクチャ観点からのDeep Neural Network高速化
PPTX
[DL輪読会]When Does Label Smoothing Help?
PDF
ドラレコ + CV = 地図@Mobility Technologies
PDF
Anomaly detection 系の論文を一言でまとめた
PPTX
[DL輪読会]ドメイン転移と不変表現に関するサーベイ
Similar to Kaggle RSNA Pneumonia Detection Challenge 解法紹介
PDF
Kaggle勉強会: RSNA STR pulmonary_embolism_detection
PDF
【CVPR 2020 メタサーベイ】Medical, Biological and Cell Microscopy
PPTX
[DL輪読会]Diagnose like a Radiologist: Attention Guided Convolutional Neural Net...
PDF
人が注目する箇所を当てるSaliency Detectionの最新モデル UCNet(CVPR2020)
PDF
Data Science Bowl 2017�Winning Solutions Survey
PPTX
[DL輪読会]End-to-End Object Detection with Transformers
PPTX
End to-end lung cancer screening with three-dimensional deep learning on low-...
PDF
夏のトップカンファレンス論文読み会 / Realtime Multi-Person 2D Pose Estimation using Part Affin...
PPTX
Unsupervised detection of lesions in brain mri using constrained adversarial ...
PDF
PDF
CVPR2018論文紹介「Pseudo Mask Augmented Object Detection」
PPTX
PDF
[DL輪読会]Combining Fully Convolutional and Recurrent Neural Networks for 3D Bio...
PPTX
[DL輪読会]医用画像解析におけるセグメンテーション
PDF
TensorFlow DevSummitを概観する
PPTX
SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習
PDF
PDF
PDF
PPTX
Kaggle RSNA Pneumonia Detection Challenge 解法紹介 1. 2. 1/24
コンペ概要
RSNA Pneumonia Detection Challenge: 肺炎検出コンペ
主催: Radiological Society of North America 北米放射線学会
Background:
• 肺炎は世界的に死因の多くを占め、日本国内の死因第3位。
• 肺炎の診断に胸部レントゲン写真がよく使われる。
• 肺炎は胸部レントゲンに白い影 opacity として現れる.
• しかし、肺水腫、出血、無気肺、肺がん、放射線治療痕、手術痕、胸
水なども白い影として現れるため診断が難しい。
• また姿勢や呼吸状況でも見え方が変わる。
• 放射線科医は日々、大量の画像を見ることを強いられており、機械学
習による自動診断が可能となれば診断が効率化され医療サービスが改
善されることが期待される。
• そこでRSNAはデータを用意しコンペを開いた。
3. 2/24
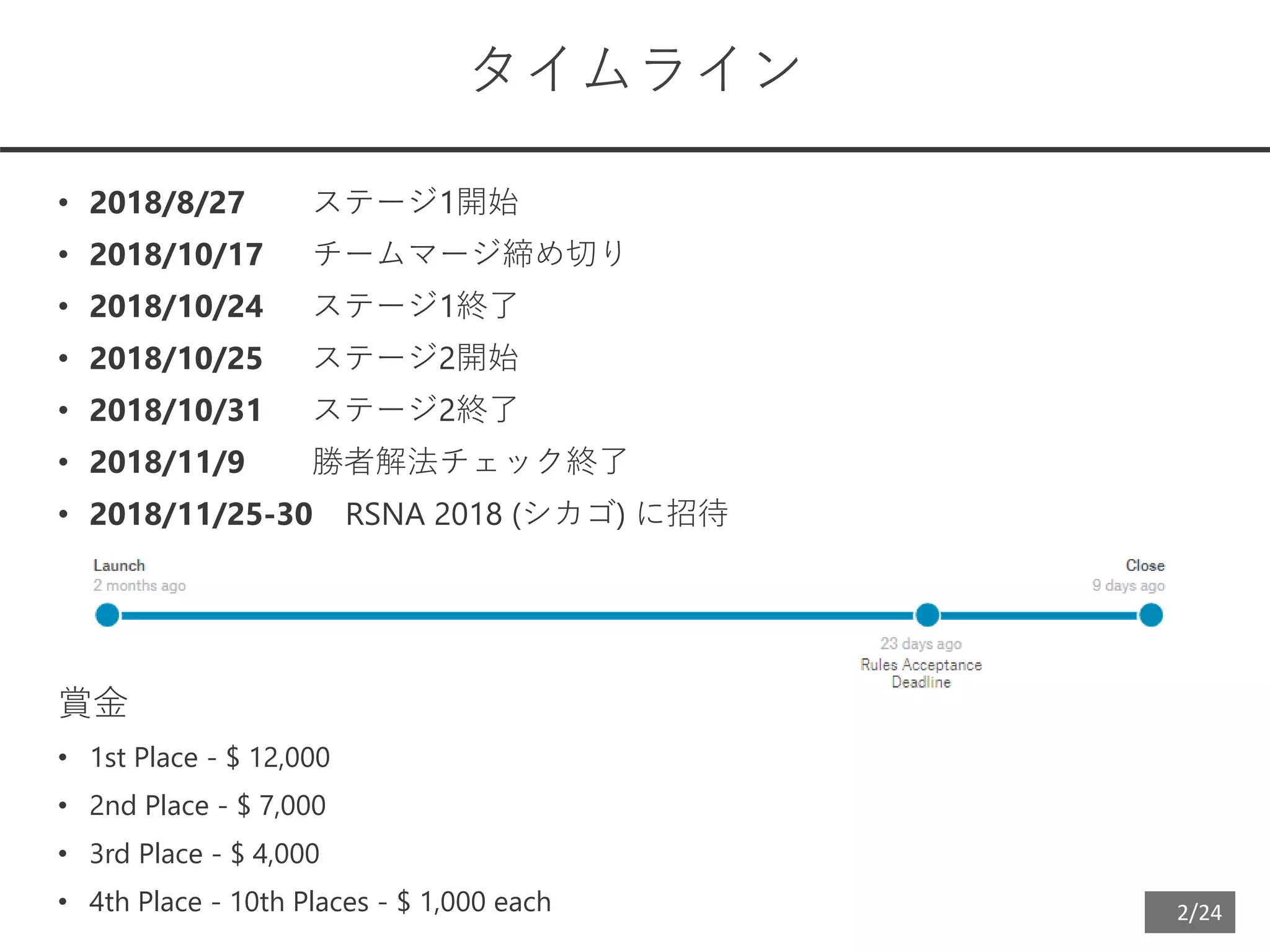
タイムライン
• 2018/8/27 ステージ1開始
• 2018/10/17 チームマージ締め切り
• 2018/10/24 ステージ1終了
• 2018/10/25 ステージ2開始
• 2018/10/31 ステージ2終了
• 2018/11/9 勝者解法チェック終了
• 2018/11/25-30 RSNA 2018 (シカゴ) に招待
賞金
• 1st Place - $ 12,000
• 2nd Place - $ 7,000
• 3rd Place - $ 4,000
• 4th Place - 10th Places - $ 1,000 each
4. 5. 6. 7. 6/24
Chest X-ray 14
Wang X, Peng Y, Lu L, et al. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised
Classification and Localization of Common Thorax Diseases. arXiv. 2017.
2017年にNIHにより公開された過去最大規模の胸部レントゲン画像データセット
ラベルは電子カルテのテキストマイニングによって付けられておりノイズが多い
患者数: 30,000 データ数: 114,000, メタデータ: 性別, 年齢, 撮影条件 (AP/PA)
ラベル: 14 疾患 (重複あり)
1. Atelectasis 無気肺
2. Cardiomegaly 心肥大
3. Effusion 胸水
4. Infiltration 浸潤 (consolidationのことをかつてinfiltrationと呼んでいた)
5. Mass 腫瘤
6. Nodule 結節
7. Pneumonia 肺炎
8. Pneumothorax 気胸
9. Consolidation コンソリデーション (主にpneumoniaによって生じる)
10. Edema 肺水腫
11. Emphysema 肺気腫
12. Fibrosis 間質性肺炎
13. Pleural Thickening 胸膜肥厚
14. Hernia 横隔膜ヘルニア
CheXNet: Chest X-ray 14を使ってCNNを学習させ、放射線科医以上の肺炎診断精度を達成
Rajpurkar P, Irvin J, Zhu K, et al. CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep
Learning. arXiv. 2017.
8. 7/24
アノテーション作成手順
1. Chest X-ray 14 (112k) から
• 肺炎関連ラベル画像 (infiltration, pneumonia, consolidation) 15k
• それ以外の疾患ラベル画像 7.5k
• 正常像 7.5k
をランダムに選択 (計30k)
2. 6人の放射線科専門医が画像ラベルを付けなおし、bounding box
(bbox) をつけた
1. Opacity
2. No Opacity / Not Normal
3. Normal
3. 30kのうち4.5kの画像はさらに12人の胸部放射線学会 (Society of
Thoracic Radiology) 会員 が1枚につき2人bboxを作成
4. 意見が割れた場合は2人の10年以上のベテラン医が再ジャッジをした
それ以外の場合、3人のbboxの重複部分を採用した
3人チェック画像の分布
• 1.5k in training dataset
• 1k in test dataset stage 1 (current LB stage)
• 2k in test dataset stage 2 (final stage)
→train と test でアノテーション方法が違う
9. 10. 11. 10/24
1
0
0.4 0.45 0.5 0.55 0.6 0.65 0.7 0.8
Evaluation
Pred Label
IoU > threshold -> True Positive
Average Precision (AP) =
mean AP (mAP) =
mAP
threshold
AP
ただし、肺炎がない画像に
• 肺炎があると予想した場合はスコア 0
• 肺炎がないと予想した場合はその画像をスコア計算から除外
12. 11/24
18th Solution:
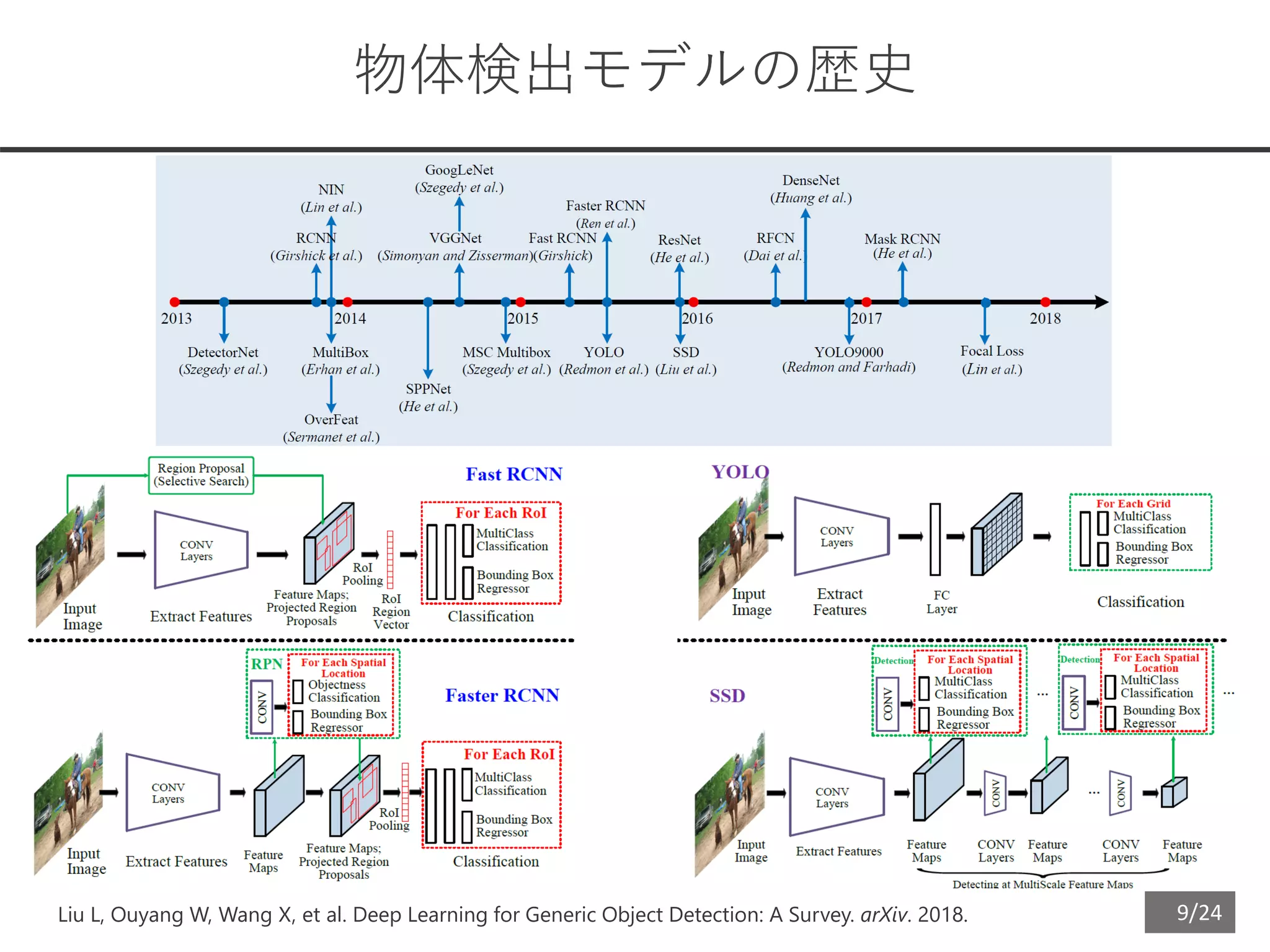
Segmentation approach
物体検出でなくSegmentationとして解いた
• There are a few objects and each object is well separated, so splitting objects from
segmentation mask must be easy.
• Shapes of opacity areas are ambiguous, so rough masks generated from bounding boxes
are not so unnatural.
• Training a segmentation model is easier than an object detection model, I believe.
• A segmentation model suits for ensemble compared to an object detection model.
U-Net (example of segmentation model)
Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv. 2015
医療画像トップカンファMICCAIで最も引用された論文
13. 12/24
18th Solution:
Model: SENet-DeepLabV3+
DeepLabV3+のbackboneをXceptionからSENet, SE-ResNeXt101に差替え
• SENet Hu J, Shen L, Sun G. Squeeze-and-Excitation Networks. arXiv. 2017.
画像分類モデル
ILSCRC 2017優勝
• DeepLabV3+
Chen L-C, Zhu Y, Papandreou G, et al. Encoder-Decoder with Atrous Separable Convolution for Semantic Image
Segmentation. arXiv. 2018
Semantic Segmentation State-of-the-art
3モデルを作成
1. SE-ResNext101-DeepLabV3+ (画像全体を入力)
2. SE-ResNext101-DeepLabV3+ (画像の一部を入力)
3. SENet-DeepLabV3+ (画像全体を入力)
全体の特徴と局所特徴の両方を捕らえる狙い
14. 13/24
18th Solution:
Training
Pre-processing
bboxに接する楕円をマスク領域とした。
Training
• 5 fold CV, Adam optimizer, batch size: 8
• クラス重み付きクロスエントロピー (背景: 肺炎 = 1:2)
• Learning rate is scheduled from 103 to 106 by cosine annealing with 3 cycles, 16
epochs per 1 cycle.
• Cycle 1: 肺炎画像のみ使用
• Cycle 2: 肺炎以外の画像も使用 (肺炎: 肺炎以外 = 1:1)
• Cycle 3: augmentationsを追加
Augmentations
平行移動, 拡縮, 回転, 明度調節, 左右反転, コントラスト平滑化, コントラスト調節, 輝度,
ガンマ補正, ガウスノイズ, カットアウト
15. 14/24
18th Solution:
Post-processing
Test Time Augmentation and ensemble
• 3 モデル
• 5 fold CV
• 左右反転
• Cycle 2 の重み, Cycle 3 の重み, Cycle 3 の重み + コントラスト平滑化
合計 3 x 5 x 2 x 3 = 90 の推定結果を平均
Post-processing
• 推定結果で値が一定閾値を超えたピクセルを肺炎領域マスクとした
• マスクを囲んでbboxとした
• マスク内の一番大きい値を確度スコアとして定義し、確度スコアが一定閾値以下の
bboxは除外した
• Train と testのアノテーション方法が違うため、適切なマスク閾値、確度閾値は
Public LBの結果を見て探索した。
• TestはTrainでは見落とされる肺炎が検出され、bboxはTrainより小さめのようだった。
16. 15/24
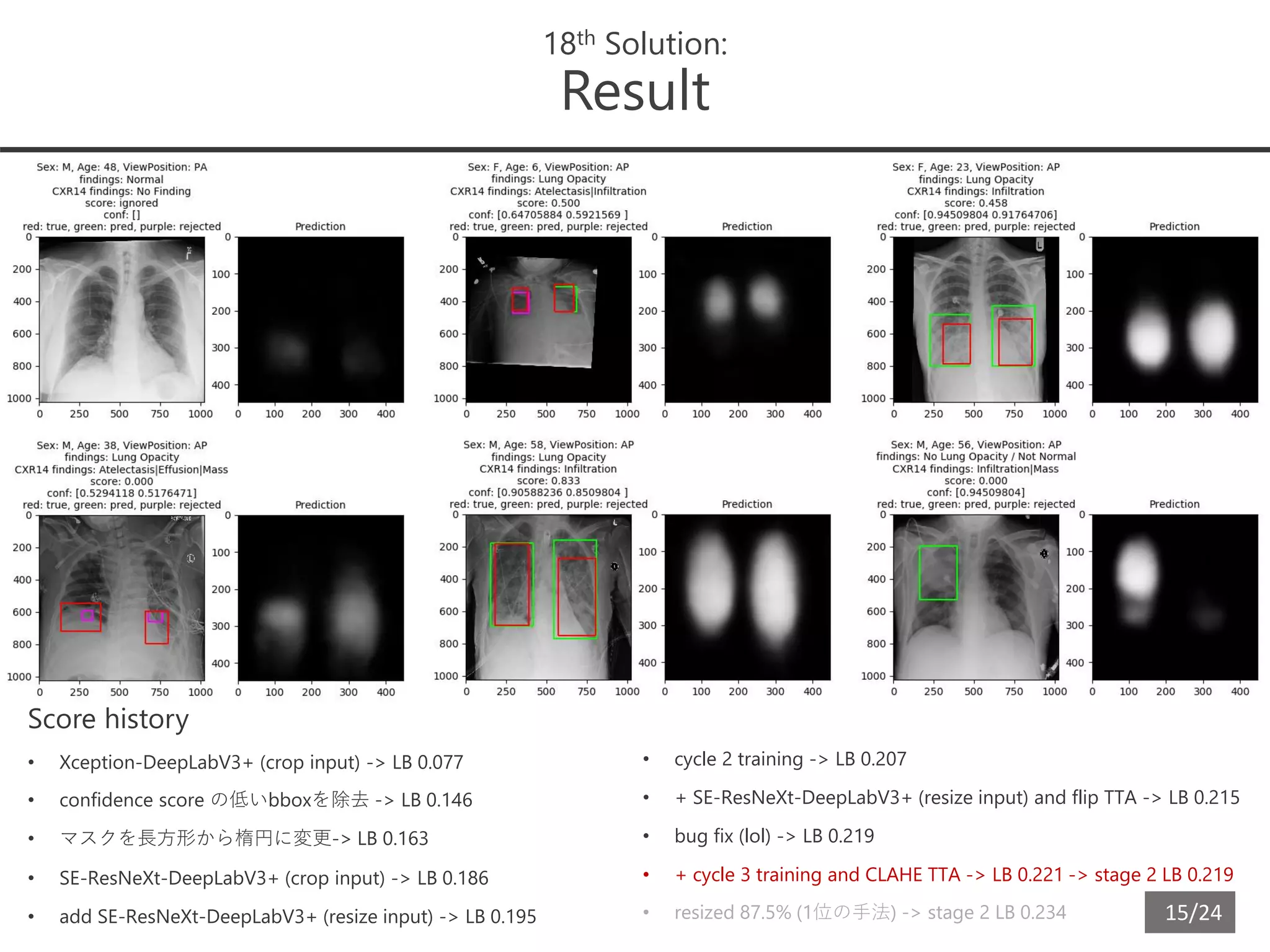
18th Solution:
Result
Score history
• Xception-DeepLabV3+ (crop input) -> LB 0.077
• confidence score の低いbboxを除去 -> LB 0.146
• マスクを長方形から楕円に変更-> LB 0.163
• SE-ResNeXt-DeepLabV3+ (crop input) -> LB 0.186
• add SE-ResNeXt-DeepLabV3+ (resize input) -> LB 0.195
• cycle 2 training -> LB 0.207
• + SE-ResNeXt-DeepLabV3+ (resize input) and flip TTA -> LB 0.215
• bug fix (lol) -> LB 0.219
• + cycle 3 training and CLAHE TTA -> LB 0.221 -> stage 2 LB 0.219
• resized 87.5% (1位の手法) -> stage 2 LB 0.234
17. 16/24
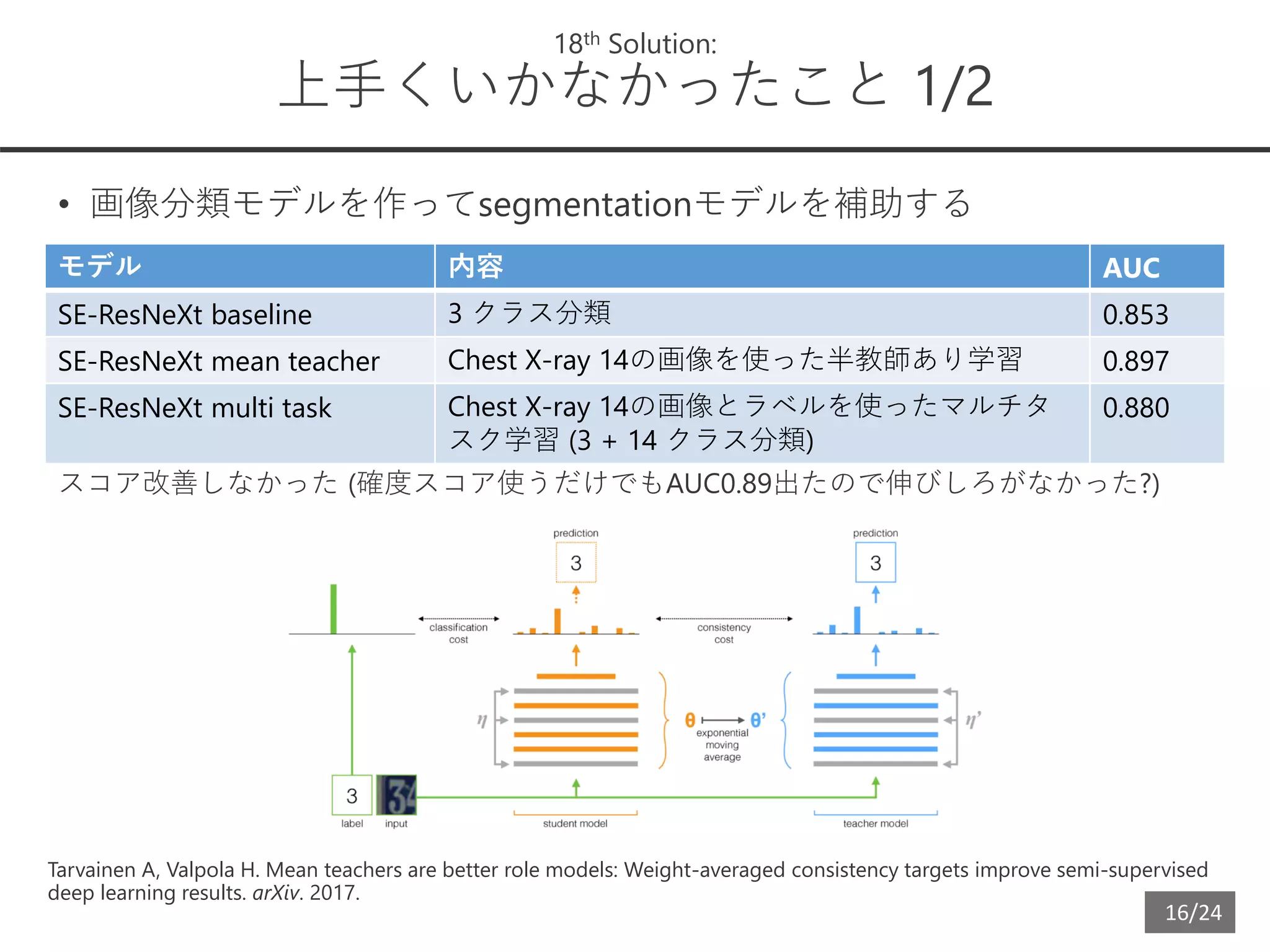
18th Solution:
上手くいかなかったこと 1/2
• 画像分類モデルを作ってsegmentationモデルを補助する
スコア改善しなかった (確度スコア使うだけでもAUC0.89出たので伸びしろがなかった?)
モデル 内容 AUC
SE-ResNeXt baseline 3 クラス分類 0.853
SE-ResNeXt mean teacher Chest X-ray 14の画像を使った半教師あり学習 0.897
SE-ResNeXt multi task Chest X-ray 14の画像とラベルを使ったマルチタ
スク学習 (3 + 14 クラス分類)
0.880
Tarvainen A, Valpola H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised
deep learning results. arXiv. 2017.
18. 17/24
18th Solution:
上手くいかなかったこと 2/2
• 最新のobject detection, segmentation用のロス (Focal loss, Lovasz loss)
ラフなマスクを使っているのでエッジを厳密に推定するためのロスは向かなかったかも
• segmentation modelに対するmean teacherによる半教師あり学習
Perone CS, Cohen-Adad J. Deep semi-supervised segmentation with weight-averaged consistency targets. arXiv. 2018.
モデルが劣化した。精度の低いモデルで半教師あり学習は無謀
• 検出されたbboxが当たりかどうかをLGBMで分類する
Data Science Bowl 2018 1位の手法
Overfitして上手くいかなかった
19. 20. 19/24
1st Solution:
Classification-Detection Pipeline
Ian Pan アメリカ、医学部3年生 / Alexandre Cadrin-Chênevert カナダ、放射線科医
Classification-Detection Pipeline
まず画像に肺炎があるか分類し、あるならbboxを物体検出する
• Classification
Chest X-ray 14のデータでpre-train
3 classes: opacity vs. not normal/no opacity vs. normal
2 classes: opacity or not
アンサンブル結果 AUC 0.93
Model Architecture Num Classes Img Size
InceptionResNetV2 2 256 or 320
InceptionResNetV2 3 256 or 320
Xception 2 384 or 448
Xception 3 384 or 448
DenseNet169 2 or 3 512
21. 20/24
1st Solution:
Detection models 1-3 (2 stage model)
1. ResNet101-deformable R-FCN
10 fold CV, img size 224, 肺炎画像のみで学習
Deformable Convolutional Networks: 画像に対して適切な受容野のサイズ・形を学習で
きるCNN
Dai J, Qi H, Xiong Y, et al. Deformable Convolutional Networks. arXiv. 2017.
R-FCN: ROIだけでなく画像全体の情報を利用して物体検出を行うモデル
Dai J, Li Y, He K, et al. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv. 2016
2. ResNet101-Deformable relation networks
Relation networks: 物体候補間の関係を考慮する物体検出モデル
Hu H, Gu J, Zhang Z, et al. Relation Networks for Object Detection. arXiv. 2017.
学習条件は#1と同様
どんなモデルか知らずに使った
3. ResNet101-Deformable relation networks (freeze)
Backboneをフリーズして学習
それ以外は#2と同様
22. 21/24
1st Solution:
Detection models 4-5 (1 stage model)
4. ResNet101-RetinaNet
10 fold CV, img size 384
5. ResNet101-RetinaNet (positive only)
肺炎画像のみで学習, それ以外は#4と同様
RetinaNet (物体検出のState-of-the-art)
Lin T-Y, Goyal P, Girshick R, et al. Focal Loss for Dense Object Detection. arXiv. 2017.
• 1 stage detectorはクラス不均衡の影響で2 stage detectorに比べ精度が劣る。
• クラス不均衡: 画像のうち物体は一部分で多くは背景のため背景だけを学習してしまう
• Focal lossを提案: 予測が簡単なクラスのlossを0に近づける。珍しいクラスのlossを大きく
する
23. 22/24
1st Solution:
Ensemble and Post-Processing
アンサンブル
モデルごとの予測bboxがIOU 0.4 以上重なっていたら同じbboxとみなして統合する
1. まずfoldごとにアンサンブル
2. モデル(#1, #2, #3)と(#4, #5)をそれぞれアンサンブル
3. #1+#2+#3と#4+#5をアンサンブル
trainとtestの乖離のせいでlocal CVが上手くいかないので割とやみくもにたくさんアン
サンブルした
Post-Processing
• TrainとTestの乖離に対処する
• Trainのほとんどは1人の放射線科医がアノテートしているのに対し、Testは3人の放射線
科医がアノテートしている。したがってTestは肺炎の検出感度が高いと推定
• Testのbboxは3人のつけたbboxの重複部分を採用しているのでTrainに比べてbboxが小さ
いと推定
• これを模倣するためにモデルが予測したbboxの重複領域をbboxとして採用したところス
コアが10-15%アップした。
• もっと単純にbboxのサイズを87.5%に縮小したところスコアが大幅改善した
(stage 1 public LB 0.218 -> 0.260)
24. 23/24
2nd Solution
Model: SE-ReNeXt101-RetinaNet (single model, img size 512)
• シンプルで調整しやすいのでRetinNetを選択
• 4 fold CV
• 小さいbboxを予測するための出力レイヤーを追加
• 3クラス分類を同時に行うマルチタスク学習
• クラス分類はdetectionより先にoverfitするためdropoutを追加
Post-Processing
• 3人アノテーションの手順をシミュレートするために予測したbboxのサイズを20%小さ
くした
25. 24/24
6th Solution PFNeumonia
Model: ResNet152-U-net (Segmentation アプローチ)
• Faster R-CNNとU-netを試してこっちが良かった
• 10 fold CV
• Bboxを予測するためにはエッジが一番重要なので通常のsegmentationの出力レイヤーの
先にbboxの上・下・左・右のエッジを予測するedge出力レイヤーを追加
• seg レイヤーのロスは 1 – F1, edge レイヤーのロスはクロスエントロピー (segのロスをク
ロスエントロピーにすると分散が小さくなってedge推定の劣化を招く)
出力
• 画像を左右に分割してから推定
• 上・下・左・右を別々に予測したのでどのエッジの組み合わせが1つのbboxを構成するのか
推定する必要がある
• 上・下・左・右のエッジの予測結果が一番重なる組み合わせをbboxとした
Post-processing
• 10 fold を5 fold ずつの2組に分け、2組の予測結果の重複領域をbboxとした






















![[解説スライド] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/nerf20200327slideshare-200326131430-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://cdn.slidesharecdn.com/ss_thumbnails/swintransformer-210514020542-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]When Does Label Smoothing Help?](https://cdn.slidesharecdn.com/ss_thumbnails/yokota20191227dl-191227001522-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]ドメイン転移と不変表現に関するサーベイ](https://cdn.slidesharecdn.com/ss_thumbnails/20190614iwasawa-190614005939-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Diagnose like a Radiologist: Attention Guided Convolutional Neural Net...](https://cdn.slidesharecdn.com/ss_thumbnails/180413dlseminarchestxray-180413032701-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]End-to-End Object Detection with Transformers](https://cdn.slidesharecdn.com/ss_thumbnails/200529dlseminardetr-200529061512-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Combining Fully Convolutional and Recurrent Neural Networks for 3D Bio...](https://cdn.slidesharecdn.com/ss_thumbnails/20170203dlhacks-170203004925-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]医用画像解析におけるセグメンテーション](https://cdn.slidesharecdn.com/ss_thumbnails/20190301fujino4-190322072121-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2020 [OS2-02] 教師あり事前学習を凌駕する「弱」教師あり事前学習](https://cdn.slidesharecdn.com/ss_thumbnails/200611ssii2020os2weaksupervision-200609142553-thumbnail.jpg?width=640&height=640&fit=bounds)



