Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Takami Sato
PDF, PPTX
5,373 views
Data Science Bowl 2017 Winning Solutions Survey
社内勉強回用の資料ですが、変な点を指摘してもらうためにコチラで先行公開 I might make a English slide, if there are some requests.
Science
◦
Read more
5
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 15
2
/ 15
3
/ 15
4
/ 15
5
/ 15
6
/ 15
7
/ 15
8
/ 15
9
/ 15
10
/ 15
11
/ 15
12
/ 15
13
/ 15
14
/ 15
15
/ 15
More Related Content
PPTX
Xgboost for share
by
Shota Yasui
PDF
High performance python computing for data science
by
Takami Sato
PDF
Word2vecで大谷翔平の二刀流論争に終止符を打つ!
by
Takami Sato
PDF
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
by
Ryo Sakamoto
PDF
AAをつくろう!
by
Takami Sato
PPT
30分で博士号がとれる画像処理講座
by
Sakiyama Kei
PDF
NIPS2016論文紹介 Riemannian SVRG fast stochastic optimization on riemannian manif...
by
Takami Sato
PDF
明日使えないすごいビット演算
by
京大 マイコンクラブ
Xgboost for share
by
Shota Yasui
High performance python computing for data science
by
Takami Sato
Word2vecで大谷翔平の二刀流論争に終止符を打つ!
by
Takami Sato
GPUが100倍速いという神話をぶち殺せたらいいな ver.2013
by
Ryo Sakamoto
AAをつくろう!
by
Takami Sato
30分で博士号がとれる画像処理講座
by
Sakiyama Kei
NIPS2016論文紹介 Riemannian SVRG fast stochastic optimization on riemannian manif...
by
Takami Sato
明日使えないすごいビット演算
by
京大 マイコンクラブ
Similar to Data Science Bowl 2017 Winning Solutions Survey
PDF
Kaggle RSNA Pneumonia Detection Challenge 解法紹介
by
理 秋山
PDF
Kaggle勉強会: RSNA STR pulmonary_embolism_detection
by
634 kami
PPTX
End to-end lung cancer screening with three-dimensional deep learning on low-...
by
kento1109
PPTX
乳癌検出のためのディープラーニングモデル
by
理 秋山
PPTX
病院で働く技師による深層学習を用いた研究
by
Yutaka KATAYAMA
PDF
画像による脳腫瘍の検出
by
Masato Miwada
PDF
胸部単純撮影における画像診断のeラーニング開発について
by
NPO法人メディカル指南車
PPTX
ヘルスケア領域でのDeep Learnigの動向
by
Naoji Taniguchi
PDF
【DL輪読会】Monocular real time volumetric performance capture
by
Deep Learning JP
PPTX
[DL輪読会]Diagnose like a Radiologist: Attention Guided Convolutional Neural Net...
by
Deep Learning JP
PDF
【CVPR 2020 メタサーベイ】Medical, Biological and Cell Microscopy
by
cvpaper. challenge
Kaggle RSNA Pneumonia Detection Challenge 解法紹介
by
理 秋山
Kaggle勉強会: RSNA STR pulmonary_embolism_detection
by
634 kami
End to-end lung cancer screening with three-dimensional deep learning on low-...
by
kento1109
乳癌検出のためのディープラーニングモデル
by
理 秋山
病院で働く技師による深層学習を用いた研究
by
Yutaka KATAYAMA
画像による脳腫瘍の検出
by
Masato Miwada
胸部単純撮影における画像診断のeラーニング開発について
by
NPO法人メディカル指南車
ヘルスケア領域でのDeep Learnigの動向
by
Naoji Taniguchi
【DL輪読会】Monocular real time volumetric performance capture
by
Deep Learning JP
[DL輪読会]Diagnose like a Radiologist: Attention Guided Convolutional Neural Net...
by
Deep Learning JP
【CVPR 2020 メタサーベイ】Medical, Biological and Cell Microscopy
by
cvpaper. challenge
More from Takami Sato
PDF
Kaggle Santa 2019で学ぶMIP最適化入門
by
Takami Sato
PDF
NIPS2017読み会 LightGBM: A Highly Efficient Gradient Boosting Decision Tree
by
Takami Sato
PDF
Kaggle&競プロ紹介 in 中田研究室
by
Takami Sato
PDF
Quoraコンペ参加記録
by
Takami Sato
PDF
Overview of tree algorithms from decision tree to xgboost
by
Takami Sato
PDF
Icml2015 論文紹介 sparse_subspace_clustering_with_missing_entries
by
Takami Sato
PDF
Scikit learnで学ぶ機械学習入門
by
Takami Sato
PDF
最適化超入門
by
Takami Sato
PDF
セクシー女優で学ぶ画像分類入門
by
Takami Sato
Kaggle Santa 2019で学ぶMIP最適化入門
by
Takami Sato
NIPS2017読み会 LightGBM: A Highly Efficient Gradient Boosting Decision Tree
by
Takami Sato
Kaggle&競プロ紹介 in 中田研究室
by
Takami Sato
Quoraコンペ参加記録
by
Takami Sato
Overview of tree algorithms from decision tree to xgboost
by
Takami Sato
Icml2015 論文紹介 sparse_subspace_clustering_with_missing_entries
by
Takami Sato
Scikit learnで学ぶ機械学習入門
by
Takami Sato
最適化超入門
by
Takami Sato
セクシー女優で学ぶ画像分類入門
by
Takami Sato
Data Science Bowl 2017 Winning Solutions Survey
1.
Data Science Bowl
2017 Winning Solutions Survey Takami Sato 17-4-18DSB2017 Solutions Survey 1
2.
Data Science Bowl
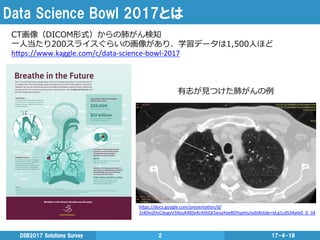
2017とは 17-4-18DSB2017 Solutions Survey 2 CT画像(DICOM形式)からの肺がん検知 ⼀一⼈人当たり200スライスぐらいの画像があり、学習データは1,500⼈人ほど h"ps://docs.google.com/presenta3on/d/ 1t40mZHzCdogvV3XeuK48SnKrA9tGK5eoaYoeBDYqoHs/edit#slide=id.g1cd534afe0_0_34 有志が⾒見見つけた肺がんの例例 h"ps://www.kaggle.com/c/data-‐science-‐bowl-‐2017
3.
注意 ある程度解釈を加えています 詳細は出典確認お願いします 17-4-18DSB2017 Solutions Survey
3
4.
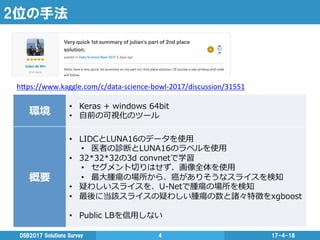
2位の手法 17-4-18DSB2017 Solutions Survey
4 環境 • Keras + windows 64bit • ⾃自前の可視化のツール 概要 • LIDCとLUNA16のデータを使⽤用 • 医者の診断とLUNA16のラベルを使⽤用 • 32*32*32の3d convnetで学習 • セグメント切切りはせず、画像全体を使⽤用 • 最⼤大腫瘍の場所から、癌がありそうなスライスを検知 • 疑わしいスライスを、U-‐‑‒Netで腫瘍の場所を検知 • 最後に当該スライスの疑わしい腫瘍の数と諸々特徴をxgboost • Public LBを信⽤用しない h"ps://www.kaggle.com/c/data-‐science-‐bowl-‐2017/discussion/31551
5.
2位の手法 17-4-18DSB2017 Solutions Survey
5 • 前処理理 • 全てを1x1x1 mmにスケーリング(恐らく1 pixcel) • LUNAとDSBデータを全て同じ向きに変換 • LUNAとLIDCをあわせるために座標を全て0〜~1にスケール • 教師ラベル • LIDCの医者の診断は全て正とした。(診断医師が⼀一⼈人でも) • LUNA16のラベルも正例例として追加 • 負例例を増やすために、肺以外の画像も追加 • フォーラムの肺部分抽出⼿手法で、抽出されなかった部分を使⽤用 • 40,000データ • (100,000の肺以外画像、10,000の偽陽画像、2000のLIDC正例例) • 偽陽データは、腫瘍だけど悪性でないもの • モデルが出来上がった後、⽬目検して癌と偽陽部分にアノテーションを追加 • LUNA16では3cm以上の腫瘍が正例例になっていないので除外
6.
2位の手法 17-4-18DSB2017 Solutions Survey
6 • 3d convnetでの肺腫瘍と癌のあるスライス検知 • 32x32x32 3D convnetを使⽤用 • バッチ版のC3Dの構成(VGGに似ている) • ネットワークのチューンには殆ど時間を使っていない • 腫瘍かどうかと悪性かどうかを、同時にマルチタスク学習 • この⽅方法は、Julianさんでは良良かったがDanielさんは2ステップ • データが不不均衡なので、1:20になるよう正例例をoversampling • 少しの正例例しか必要なかったのには驚きとのこと • 12m格⼦子のストライドと3種類のズームで癌の組織の場所を検知 • 最⼤大腫瘍とそのz座標(スライス位置)のみ後⼯工程で使⽤用 • 疑わしい腫瘍検知 • LUNAや過去のDSBから肺がん腫瘍の画像を収集 • ⼩小さいU-‐‑‒Netを使⽤用して、疑わしいスライスから怪しい腫瘍を抽出 • 全⾝身データや肺気腫のデータも⼊入れたが、⼤大きくは改善せず
7.
2位の手法 17-4-18DSB2017 Solutions Survey
7 • 最終モデル • xgboostで学習 • ズームの種類、スライスの位置、怪しい組織の数をデータに学習 • min_̲child_̲weightを60にして、過学習を抑制 • ⼿手元CVスコアは0.39、最終スコアは0.40117 • Danielsさんとのアンサンブル • 彼は64x64x64のResnetライクなモデルを使⽤用 • 肺腫瘍検知と悪性腫瘍検知の2段階 • LIDCの腫瘍情報も使⽤用 • 2⼈人の予測を平均して、最終submit
8.
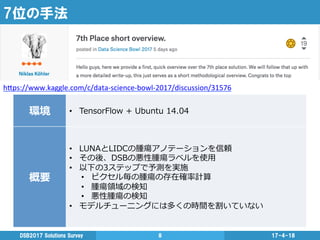
7位の手法 17-4-18DSB2017 Solutions Survey
8 h"ps://www.kaggle.com/c/data-‐science-‐bowl-‐2017/discussion/31576 環境 • TensorFlow + Ubuntu 14.04 概要 • LUNAとLIDCの腫瘍アノテーションを信頼 • その後、DSBの悪性腫瘍ラベルを使⽤用 • 以下の3ステップで予測を実施 • ピクセル毎の腫瘍の存在確率率率計算 • 腫瘍領領域の検知 • 悪性腫瘍の検知 • モデルチューニングには多くの時間を割いていない
9.
7位の手法 • ピクセル毎の腫瘍の存在確率率率計算 – 128x128のU-‐‑‒Netを使⽤用 –
LUNAとLIDCの腫瘍のアノテーションを使⽤用 – ランダムなスライスを作って学習 – 最終的には軸に沿ったスライスに予測し、3次元腫瘍存在確率率率テンソルを計算 • 各ピクセル3回計算されるので平均する • 腫瘍領領域の検知 – 以下の⼿手順で腫瘍の場所を特定 • ⼩小さい閾値を設定(0.2) • 閾値以上のpixcelの塊を列列挙 • 塊のサイズが⼀一定以上だった場合は、閾値を上げて再実⾏行行 – 腫瘍の中⼼心から64x64x64の領領域を切切り取る – 領領域の腫瘍存在確率率率の和が⼤大きい順に20領領域を選択 – LIDCの悪性腫瘍情報を使うべきだったとの事 17-4-18DSB2017 Solutions Survey 9
10.
7位の手法 • 悪性腫瘍の検知 – ⼀一⼈人当たり、20個の64x64x64のデータが存在 –
3D resnetを使⽤用 – 1チャネル⽬目にピクセルの値を⼊入れて、2チャネル⽬目に腫瘍存在確率率率を⼊入れた – (20, 64, 64, 64, 2)の5次元テンソルがラベルに紐紐づく – 3D resnet後は20個の予測が出揃い、そのmax値を取るのが最も良良かった • Noisy-‐‑‒ANDやNoisy-‐‑‒ORなども試したらしい • 解釈としても妥当 – ここに機械学習⼿手法を⽤用いたが、改善せず • 腫瘍存在確率率率の並び順は間違ってる家の姓があり、並び順に依存しないmax等が良良いとのこと 17-4-18DSB2017 Solutions Survey 10
11.
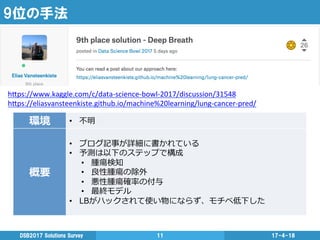
9位の手法 17-4-18DSB2017 Solutions Survey
11 h"ps://www.kaggle.com/c/data-‐science-‐bowl-‐2017/discussion/31548 h"ps://eliasvansteenkiste.github.io/machine%20learning/lung-‐cancer-‐pred/ 環境 • 不不明 概要 • ブログ記事が詳細に書かれている • 予測は以下のステップで構成 • 腫瘍検知 • 良良性腫瘍の除外 • 悪性腫瘍確率率率の付与 • 最終モデル • LBがハックされて使い物にならず、モチベ低下した
12.
9位の手法 17-4-18DSB2017 Solutions Survey
12 • 腫瘍検知 – LUNAデータのアノテーションで腫瘍の位置を学習 – 1 voxcelが1x1x1 mm cubeになるようにスケーリング – 学習にはU-‐‑‒Netベースのネットワークを使⽤用 – ⽬目的関数は、Dice類似度度を使⽤用 – LUNAのアノテーションは32x32x32だが、⼊入⼒力力は64x64x64にして 内部のアノテーションを回転したり歪ませたりして、データを増加 – 検知された領領域からDifference of Gaussian法で腫瘍を検知 – このままだと、⾮非常に多くの腫瘍が検知されるので、次に良良性腫瘍を除外する
13.
9位の手法 17-4-18DSB2017 Solutions Survey
13 • 良良性腫瘍の除外 – 肺領領域の検知 • 肺領領域以外の腫瘍は、肺がんではないので除外 • 肺領領域の検知⽅方法は、カーネル上で議論論しているのを参考にした • 最終的には3Dで肺を含む凸包から、肺以外っぽい領領域を除外するアプローチ – 3D Resnetベースモデルでの良良性腫瘍の除外 • LUNAの偽陽性判定トラックのラベルを使⽤用 • 48x48x48サイズの⼊入⼒力力のネットワークを作成 • 詳細はブログを参照 • 悪性腫瘍の予測 – LIDCデータに腫瘍の悪性度度のデータがあることを、終了了2週前に発⾒見見 – FPRネットワークベースのモデルで各腫瘍に悪性度度を付与
14.
9位の手法 17-4-18DSB2017 Solutions Survey
14 • 最終モデル – 腫瘍の悪性度度を、患者の癌ラベルに変換する – 2つのアプローチを使⽤用 • P(患者が肺がん) = 1 – (腫瘍iが良良性) – 直感的だが、ある腫瘍が悪性だとモデルが確信している場合、それ以上学習が進まない • Log Mean Exponet – ログをとって、⼩小さい確率率率は超⼩小さくした状態で平均取って戻すので、 ソフトバージョンのmax関数的に動く – モデルと共にFine-‐‑‒tuneできる – 上記⼿手法で30予測を作成し、アンサンブルして最終スコアを作成 • 最終の2 submitを以下で構成 • Defensive Ensemble – 各モデルの混合⽐比率率率をCVで決定 – ただし、結果的に最良良モデルの予測1つだけが選択された • Aggressive Ensemble – どのモデルを使うかをCVで学習して、選ばれたモデルの単純平均で構成
15.
意見募集中 スピード重視で資料を作ったので おかしな点がありましたら、 Twitterの@tkm2261までメンション頂けると助かります 17-4-18DSB2017 Solutions Survey
15
Download





























![[DL輪読会]Diagnose like a Radiologist: Attention Guided Convolutional Neural Net...](https://cdn.slidesharecdn.com/ss_thumbnails/180413dlseminarchestxray-180413032701-thumbnail.jpg?width=640&height=640&fit=bounds)









