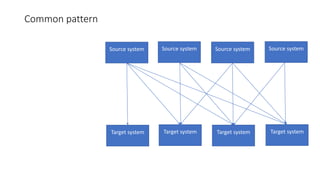
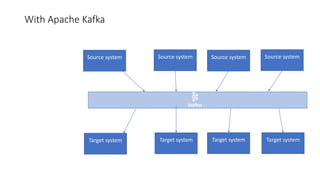
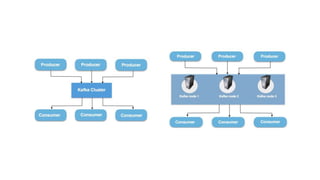
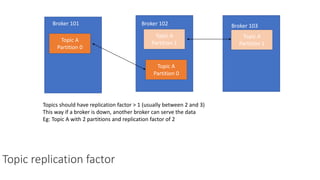
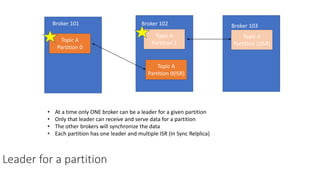
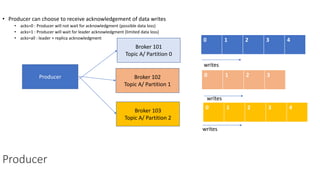
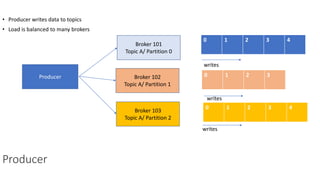
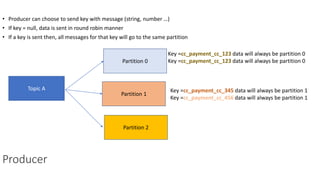
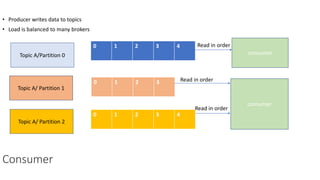
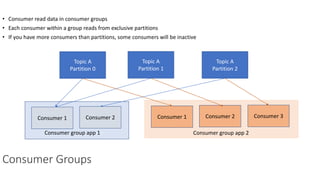
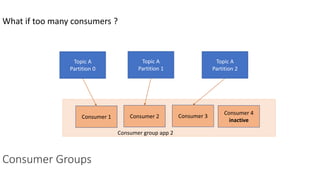
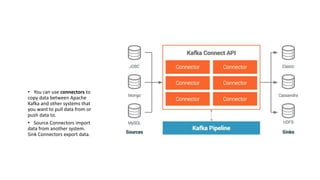
The document provides an overview of Apache Kafka, detailing its architecture, including producers, consumers, brokers, and topics, along with the concepts of partitions and offsets. It explains data writing and reading mechanisms, including different acknowledgment settings and consumer group functionalities. The document also introduces Kafka connectors and the Confluent KSQL for real-time data processing.