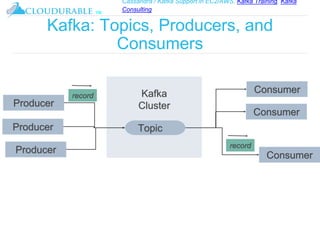
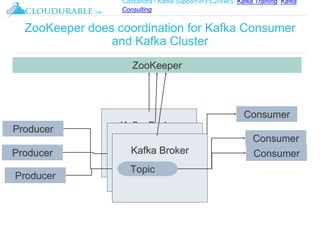
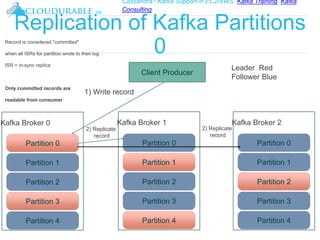
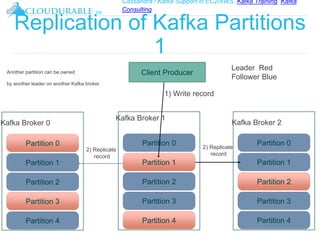
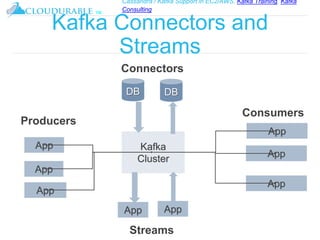
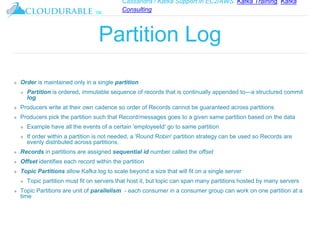
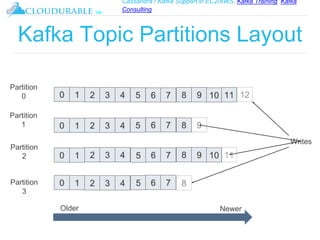
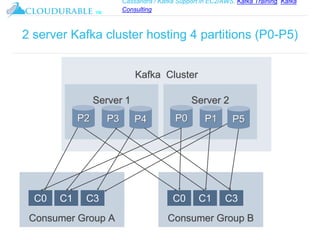
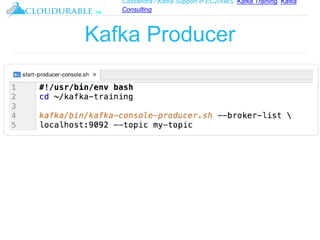
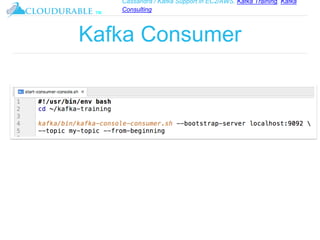
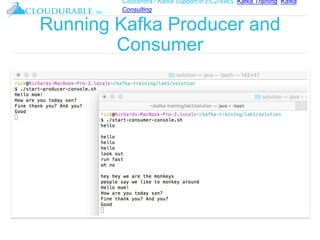
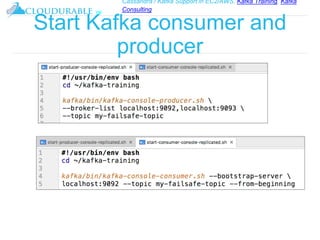
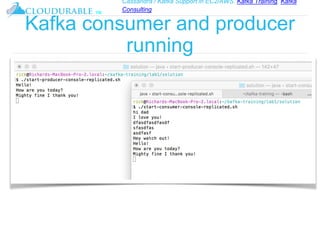
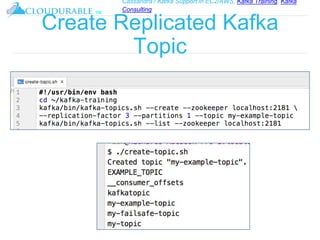
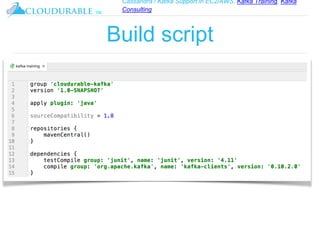
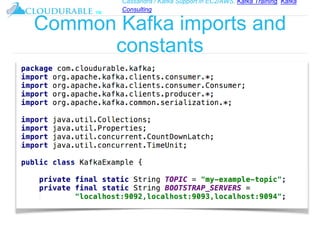
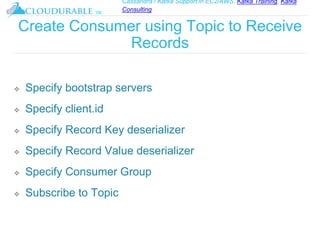
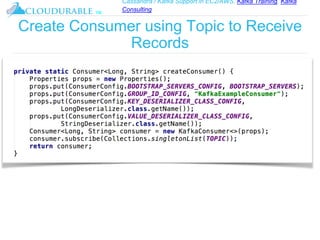
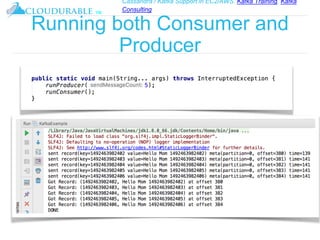
The document discusses Kafka, an open-source distributed event streaming platform. It provides an introduction to Kafka and describes how it is used by many large companies to process streaming data in real-time. Key aspects of Kafka explained include topics, partitions, producers, consumers, consumer groups, and how Kafka is able to achieve high performance through its architecture and design.