Download as PDF, PPTX



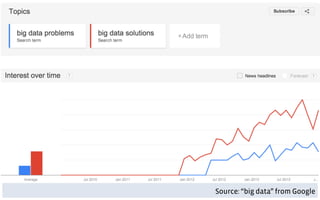









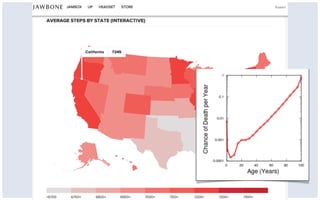
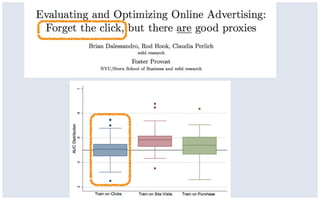


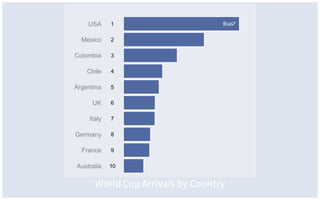
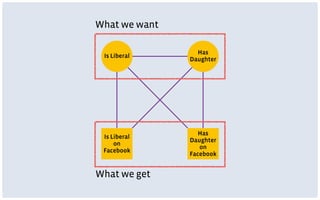



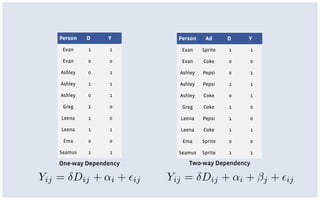
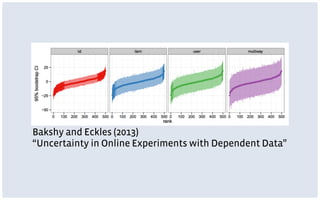


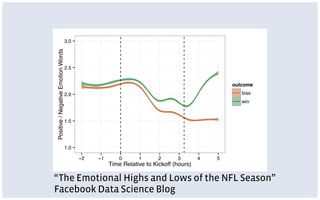









This document discusses common limitations that arise when working with large datasets, or "big data". It outlines four main limitations: 1) Measuring the wrong thing if the available data does not directly measure the variable of interest. 2) Biased samples if the data is not representative of the target population. 3) Dependence if observations are not independent due to repeated measurements. 4) Uncommon support if qualifying cases that satisfy criteria like matching are rare in the data. For each limitation, common patterns are described and opportunities for addressing the issues through better measurement, modeling, or experimental design are presented. The conclusion emphasizes that generating high quality data is better than relying on convenience data alone, and there are research opportunities in overcoming limitations




















































































