Downloaded 38 times




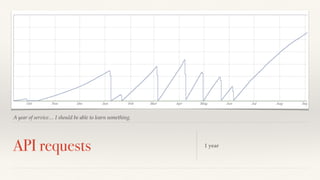
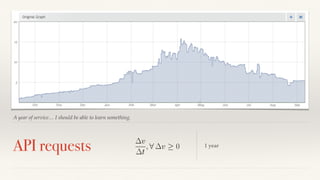



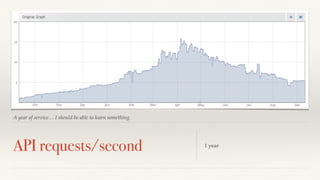
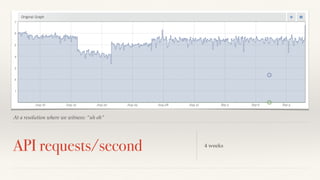
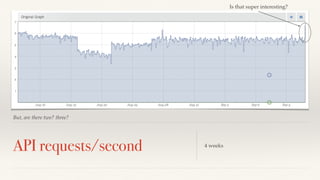
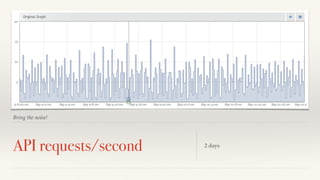
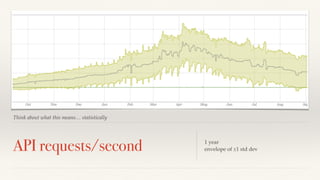



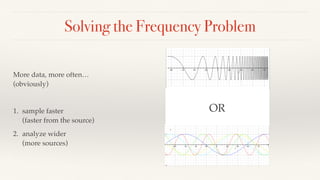








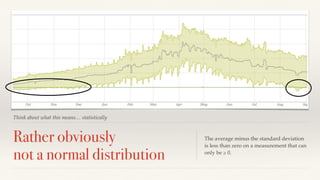
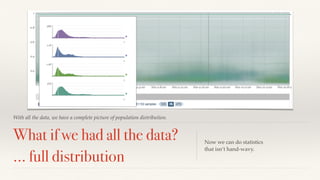
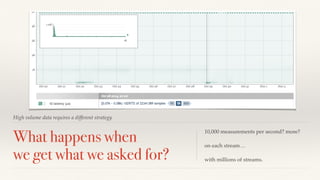


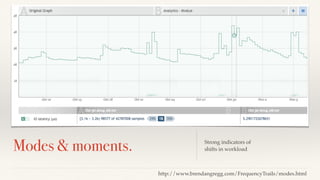
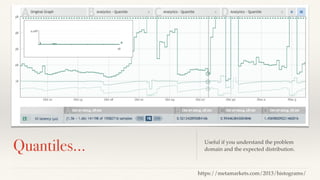
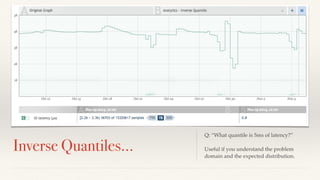


The document discusses mathematical methods for analyzing systems telemetry data, addressing issues such as signal classification, offline modeling, and online fault detection in the context of big data. It emphasizes the importance of statistical models and how they can be challenged by infrequent data and deviations from normal distributions, leading to the need for alternative approaches like the tukey test. Overall, it highlights the necessity of adapting algorithms to handle high-frequency data efficiently while ensuring reliable and repeatable outcomes.





















































































