Download to read offline




































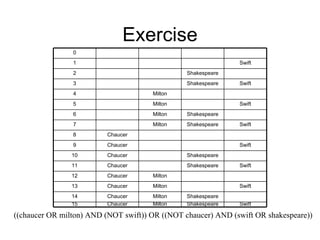

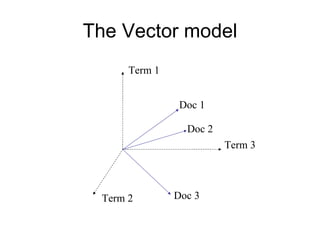






This document provides an overview of search engine technology and the goals of the SET FALL 2009 course. It discusses different types of search engines, what is required to build a search engine, and course logistics such as topics, readings, assignments, and projects. The key goals of the course are to understand how search engines work, their limitations, and learn how to analyze textual and structured data through coding, modeling, and evaluation.

















































































