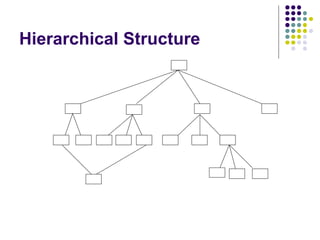
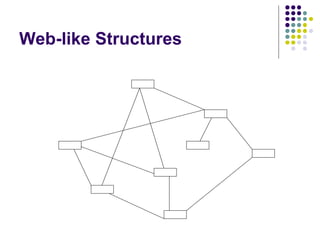
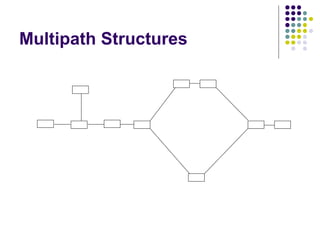
The document discusses web-based information retrieval and summarizes some key challenges, including: managing large amounts of hyperlinked web pages, crawling the web to find relevant sites to index, and measuring the quality and authority of information. It also covers techniques for text representation in information retrieval systems, including the inverted file approach and using probability methods.