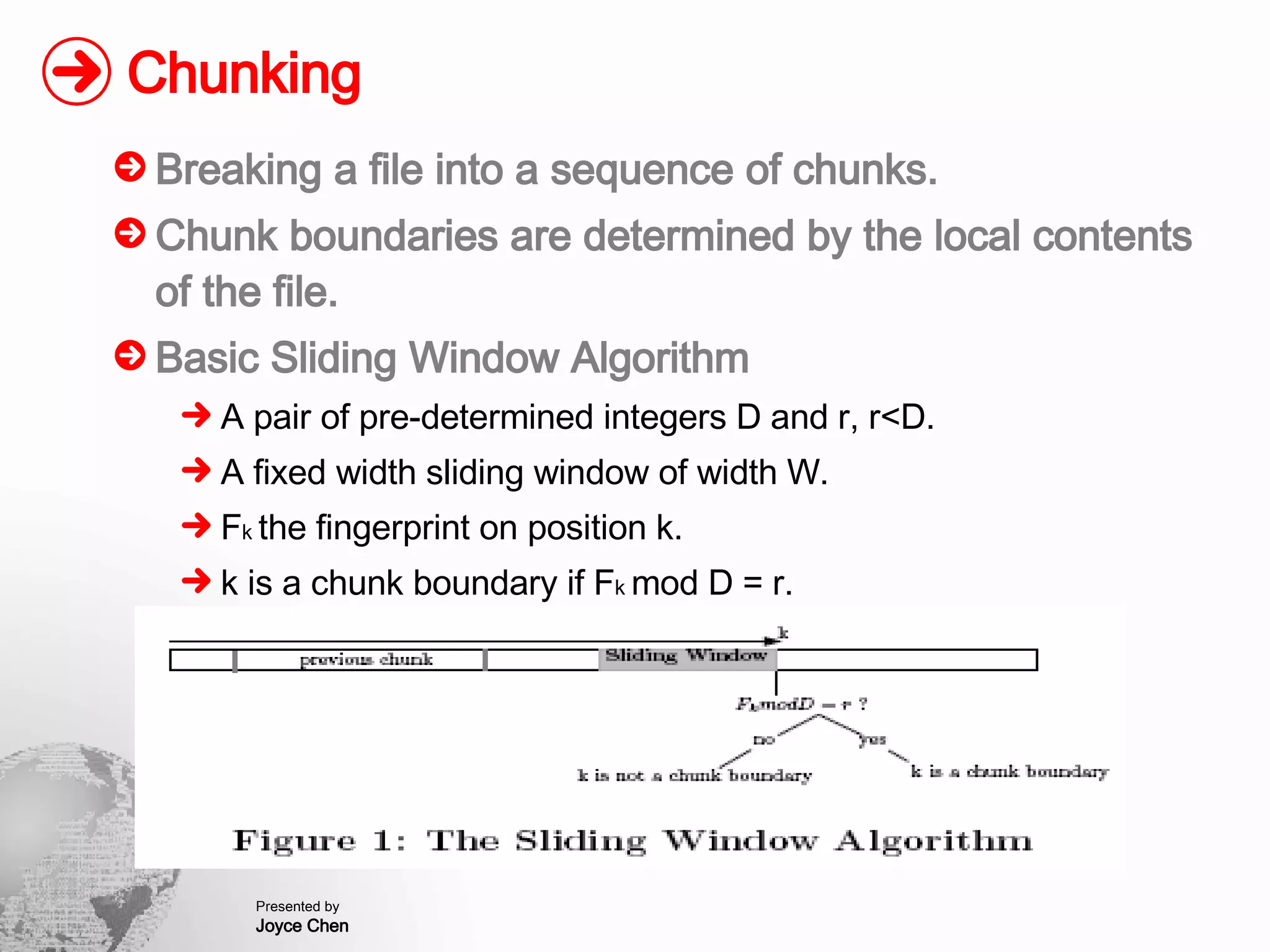
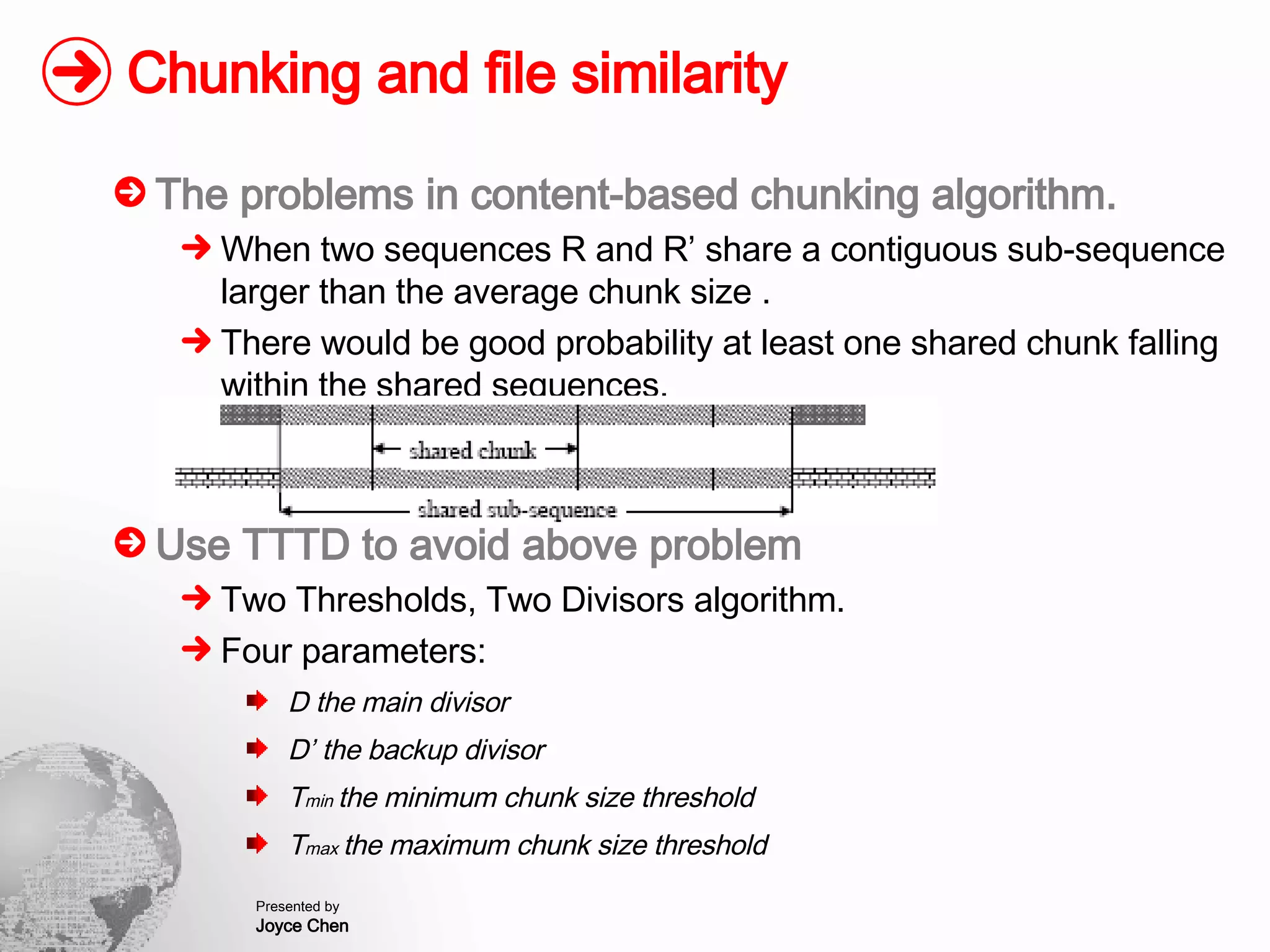
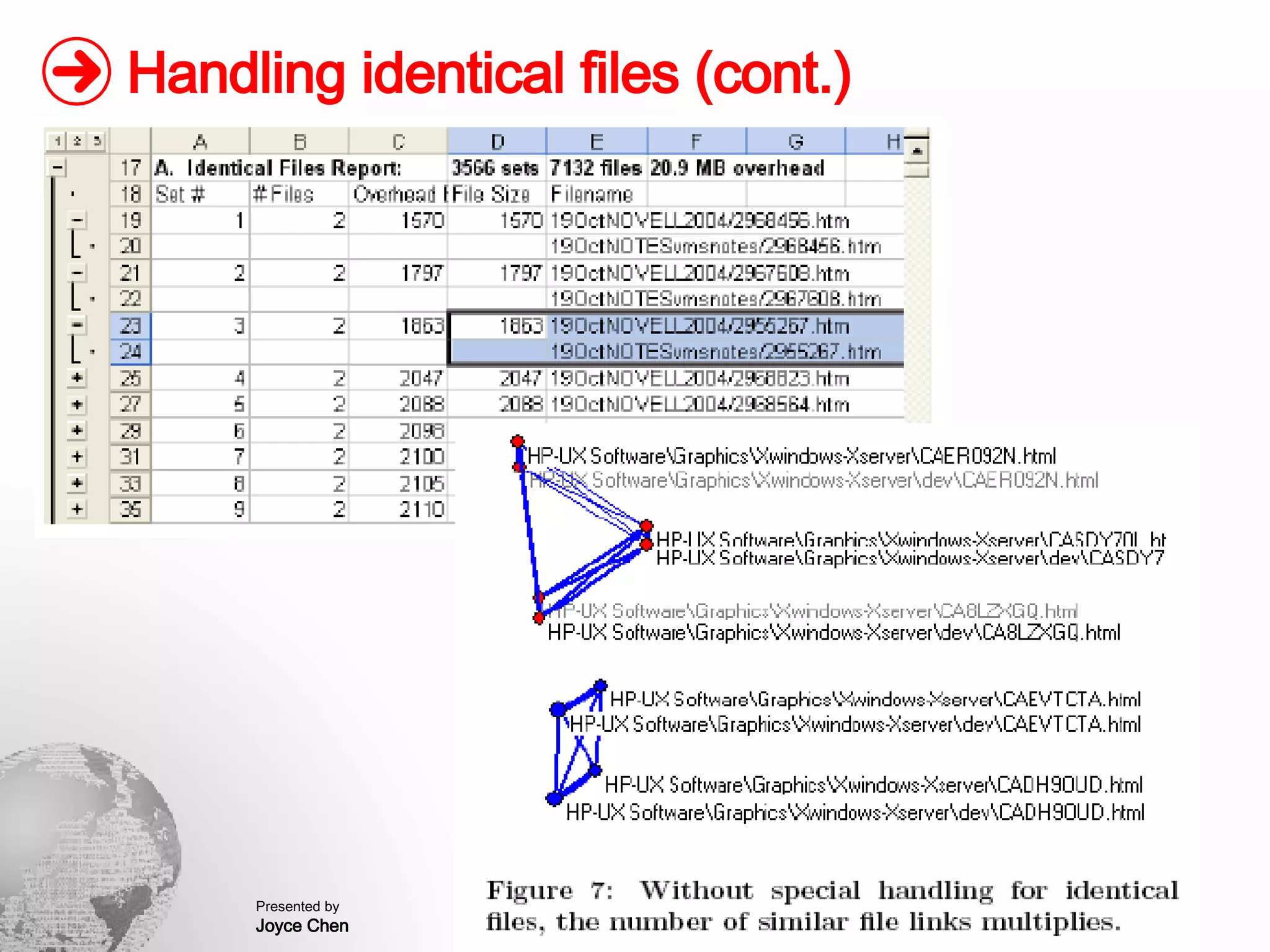
The document presents a method for finding similar files in large document repositories by breaking files into chunks, computing hashes for each chunk, and comparing chunk hashes across files to determine similarity. It involves chunking each file, hashing the chunks, constructing a bipartite graph between files and chunks, and building a file similarity graph based on shared chunks above a threshold. The method was implemented and tested on a repository of technical support documents, taking 25-39 minutes to process hundreds of documents totaling hundreds of megabytes in size.
![Finding Similar Files in Large Document Repositories KDD’05, August 21-24, 2005, Chicago, Illinois, USA. Copyright 2005 ACM George Forman HewlettPackard Labs [email_address] Kave Eshghi HewlettPackard Labs [email_address] Stephane Chiocchetti HewlettPackard France [email_address]](https://image.slidesharecdn.com/finding-similar-files-in-large-document-repositories4474/75/Finding-Similar-Files-in-Large-Document-Repositories-1-2048.jpg)








































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)







![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








