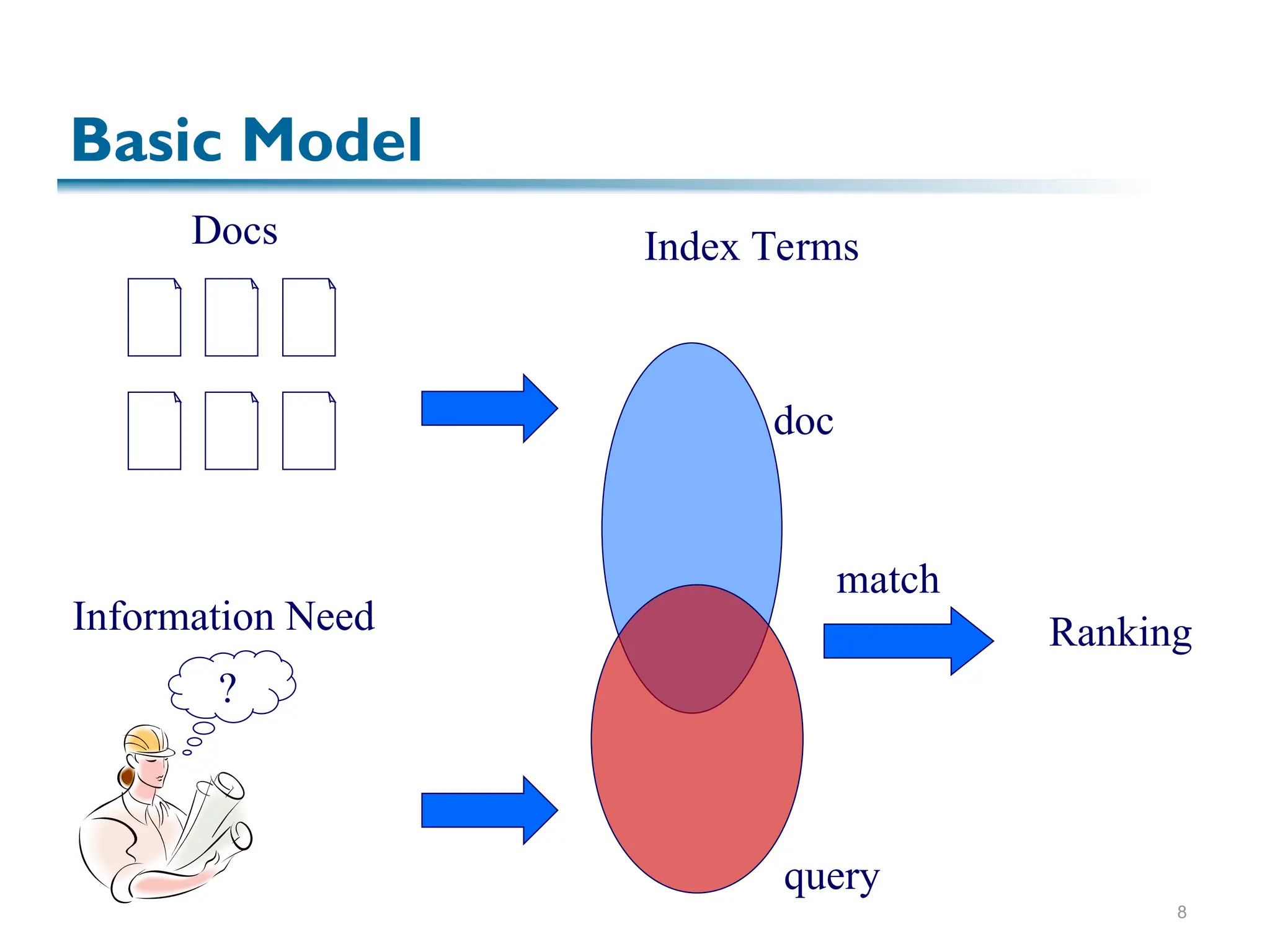
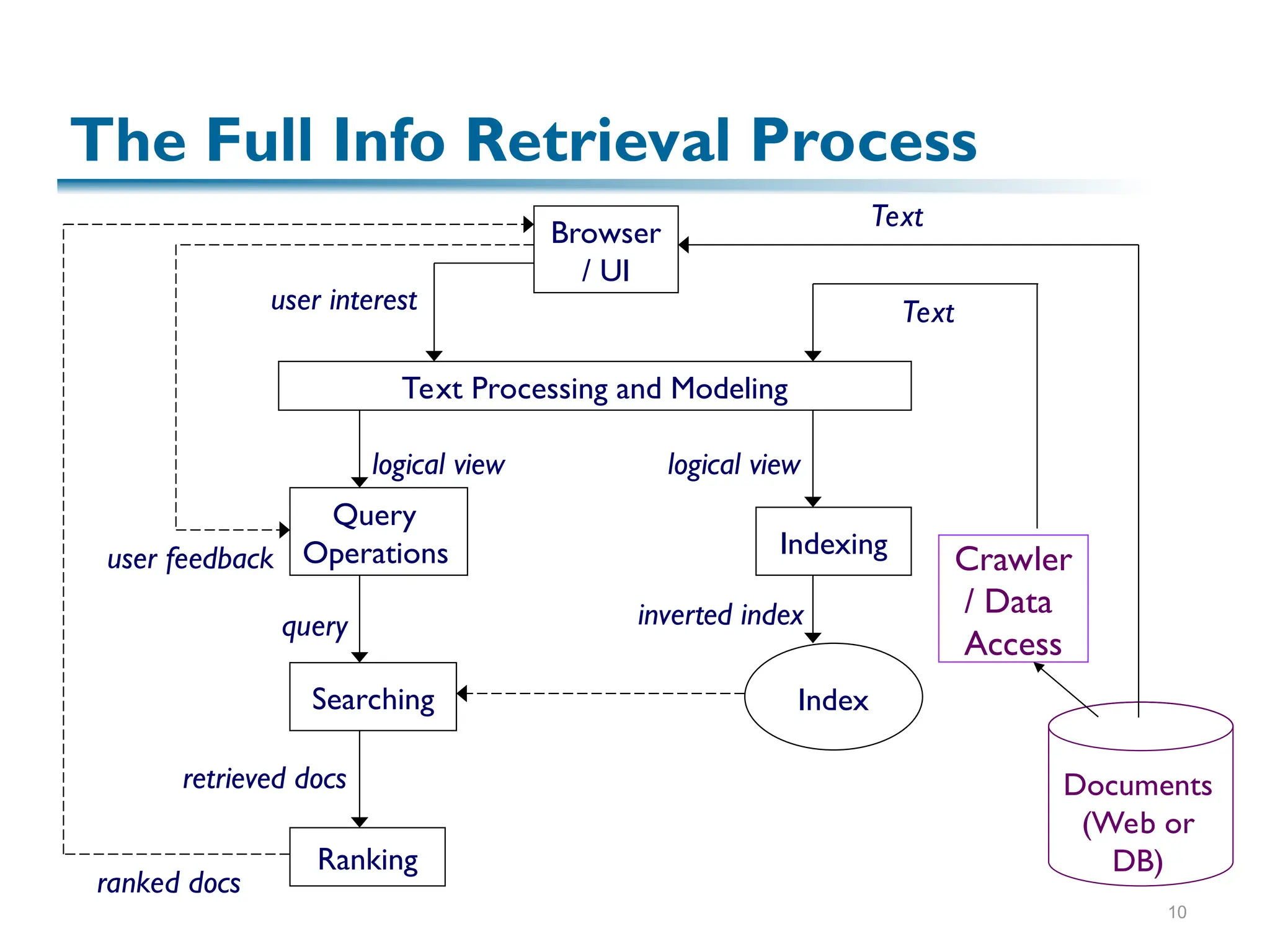
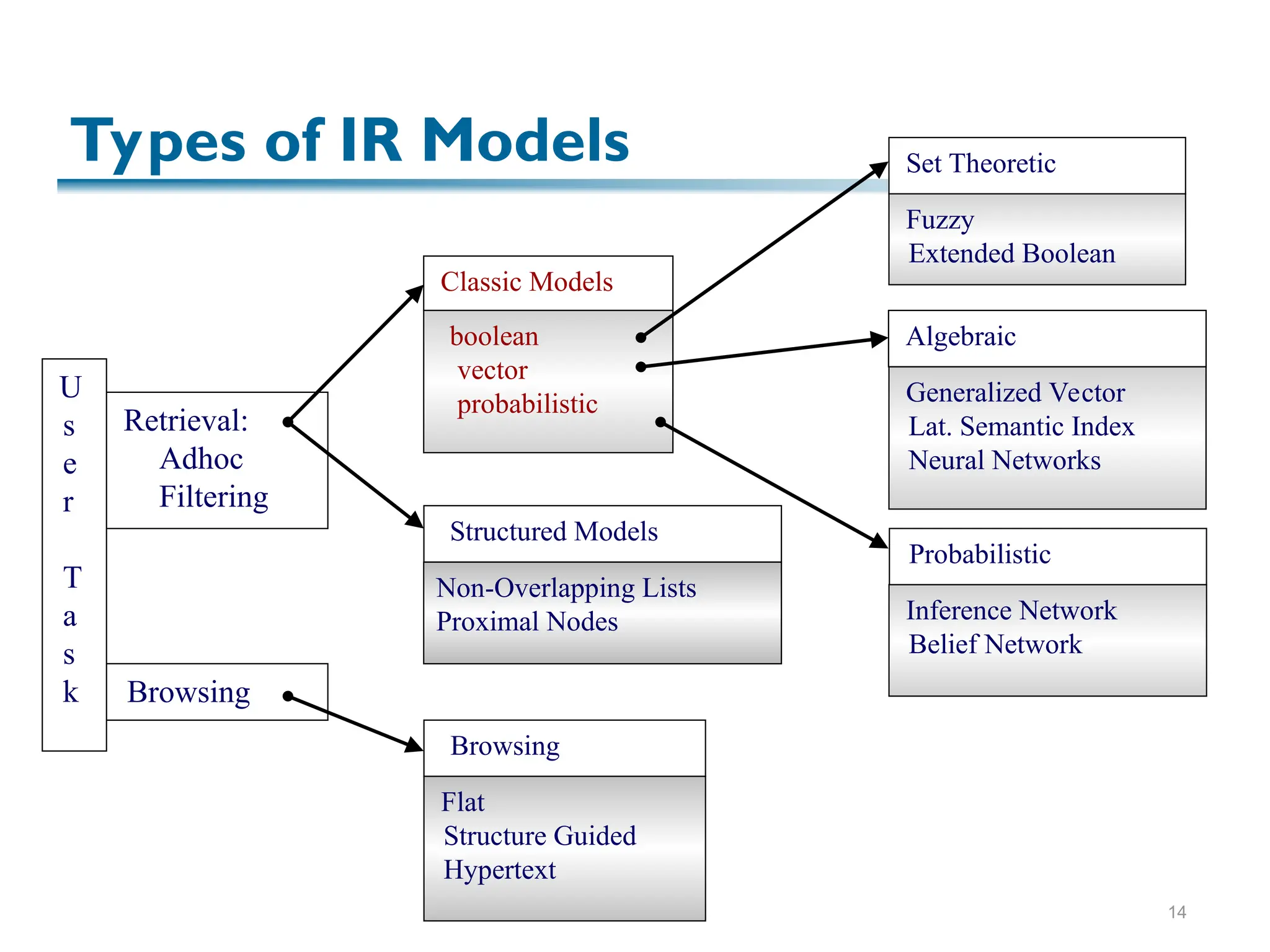
The document discusses the principles of information retrieval (IR) as applied to web search, highlighting key challenges such as the vast amount of content and varying quality of information online. It reviews traditional IR concepts, models, and ranking methods, with a focus on vector models which utilize term weighting to enhance search accuracy. The findings emphasize the importance of relevance and user needs in indexing and search operations.


















![23
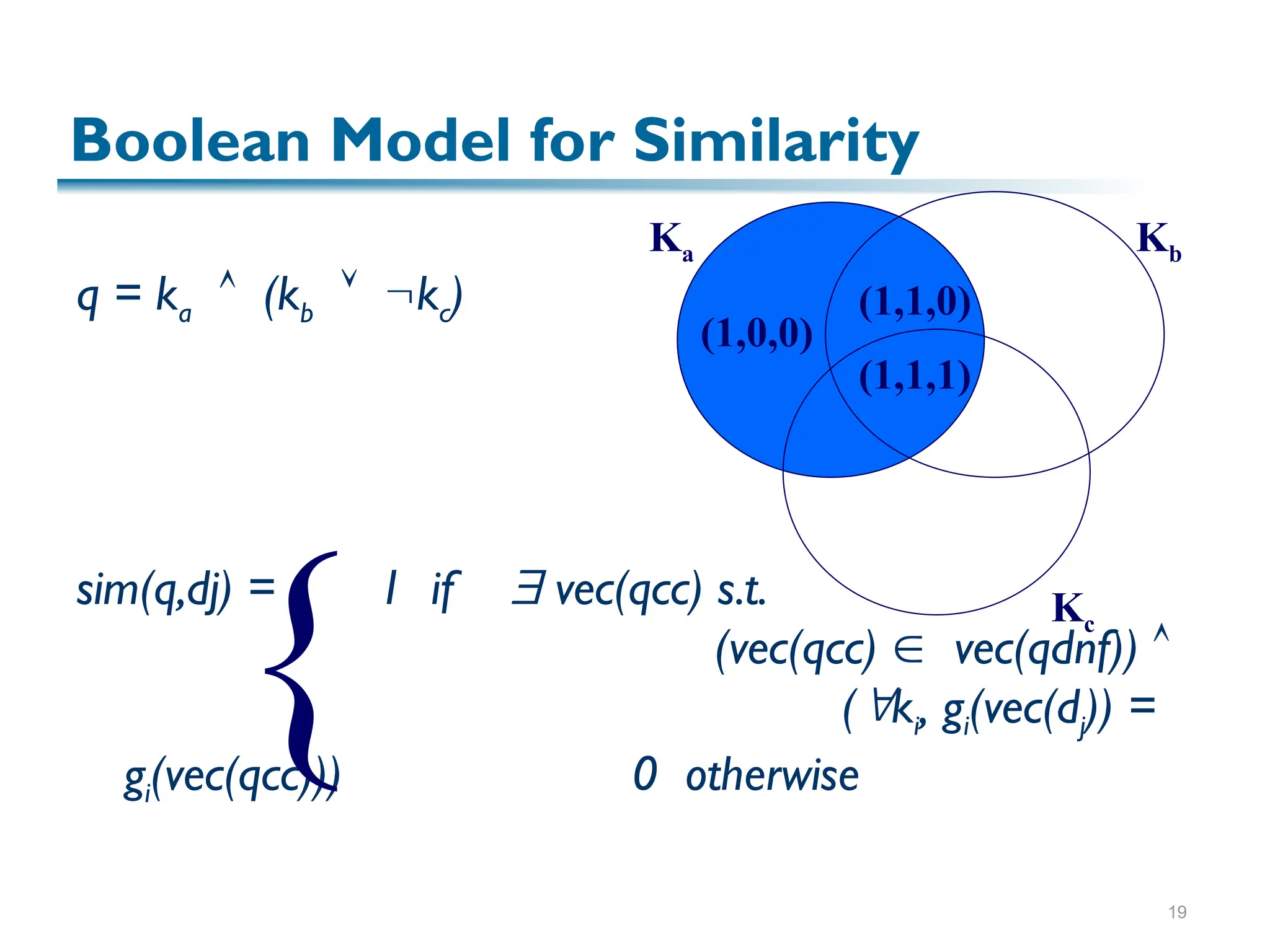
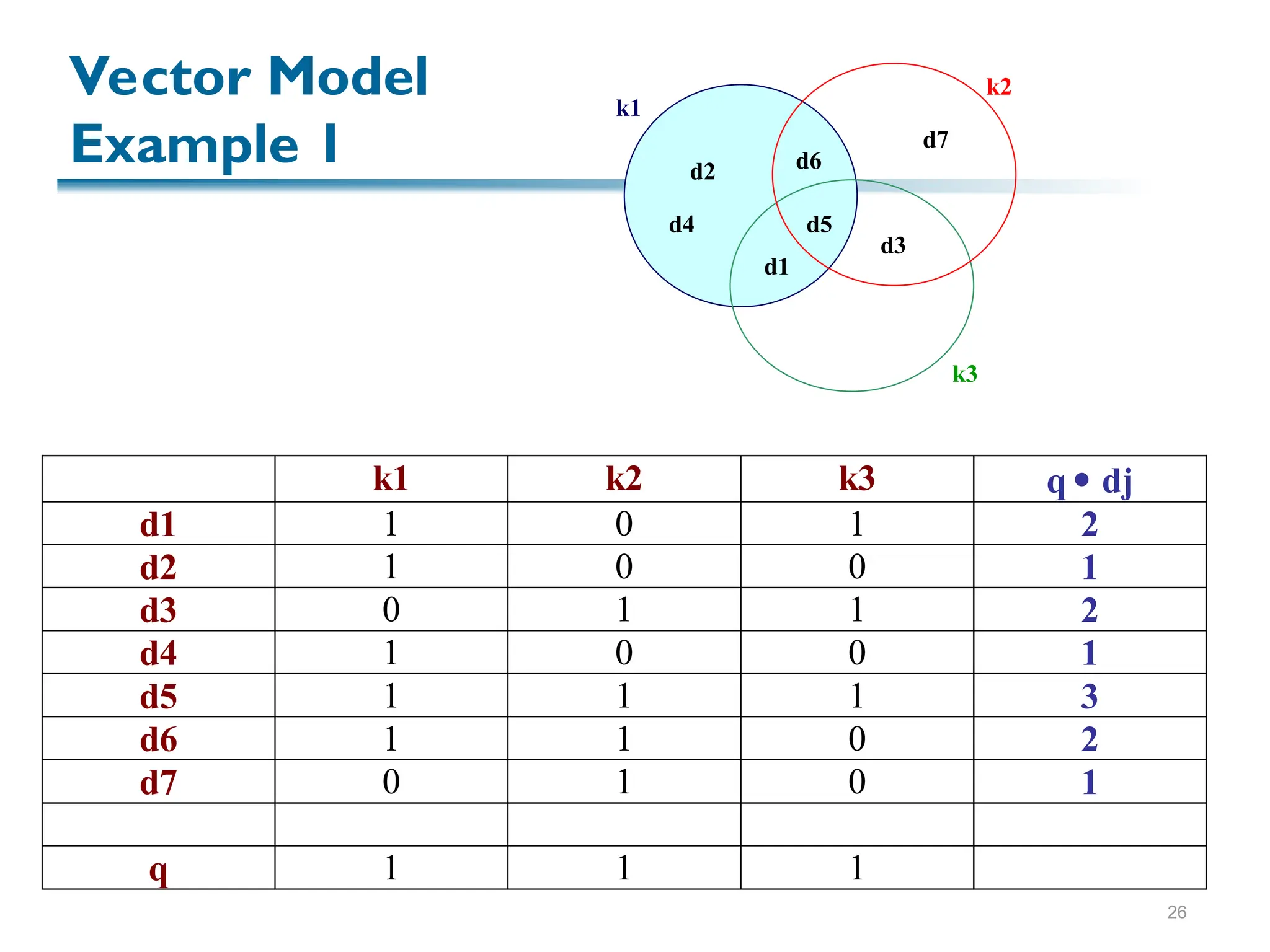
Sim(q,dj) = cos()
= [vec(dj) vec(q)] / |dj| * |q|
= [ wij * wiq] / |dj| * |q|
Since wij > 0 and wiq > 0,
0 ≤ sim(q,dj) ≤ 1
A document is retrieved even if it matches
the query terms only partially
i
j
dj
q
Vector Model](https://image.slidesharecdn.com/f-ir-241012083954-d6064a68/75/Information-Retrieval-and-Storage-Systems-23-2048.jpg)
![24
Weights in the Vector Model
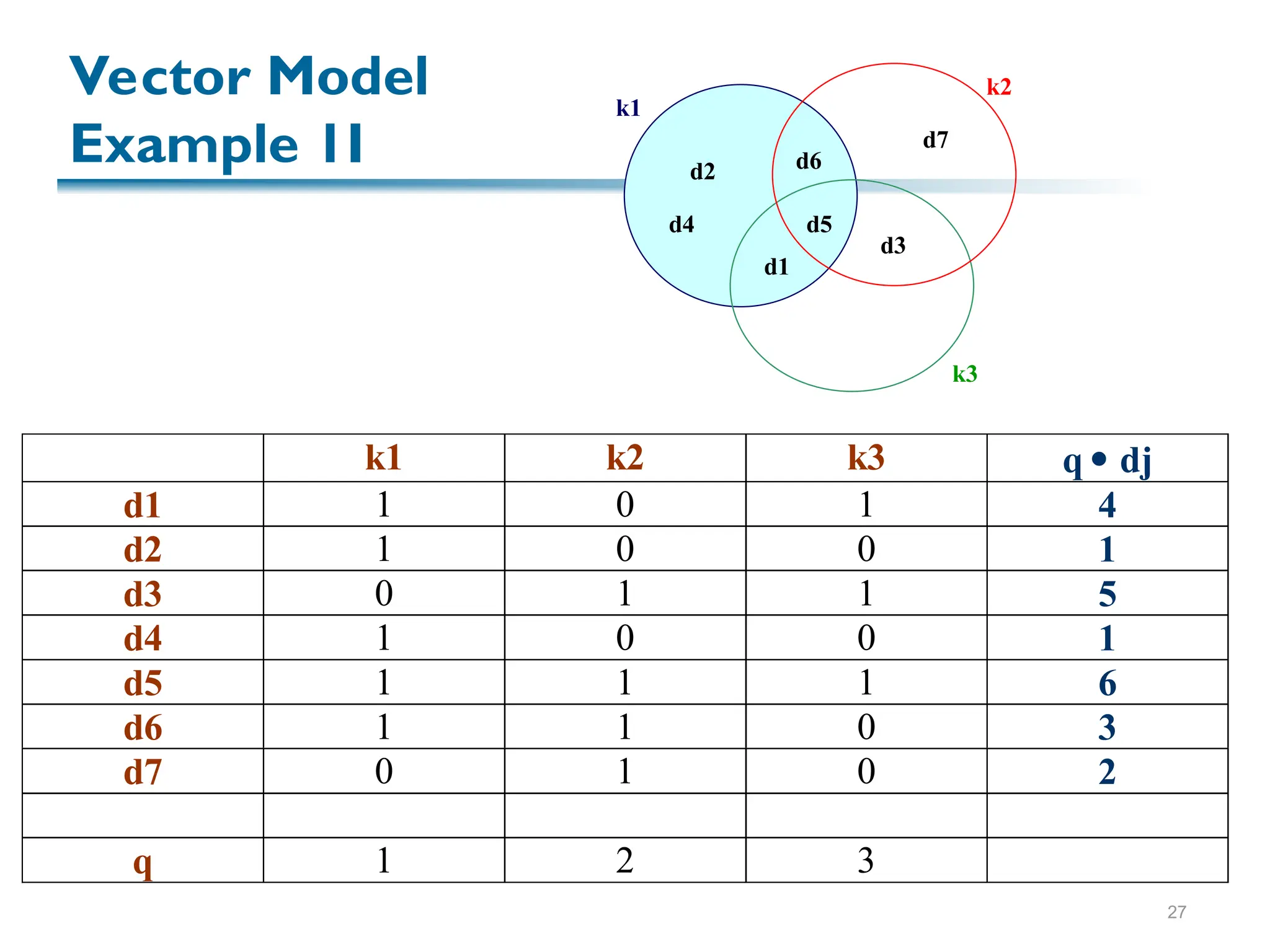
Sim(q,dj) = [ wij * wiq] / |dj| * |q|
How do we compute the weights wij and wiq?
A good weight must take into account two effects:
quantification of intra-document contents (similarity)
tf factor, the term frequency within a document
quantification of inter-documents separation
(dissimilarity)
idf factor, the inverse document frequency
wij = tf(i,j) * idf(i)](https://image.slidesharecdn.com/f-ir-241012083954-d6064a68/75/Information-Retrieval-and-Storage-Systems-24-2048.jpg)


![29
Vector Model, Summarized
The best term-weighting schemes tf-idf weights:
wij = f(i,j) * log(N/ni)
For the query term weights, a suggestion is
wiq = (0.5 + [0.5 * freq(i,q) / max(freq(l,q)]) * log(N / ni)
This model is very good in practice:
tf-idf works well with general collections
Simple and fast to compute
Vector model is usually as good as the known ranking
alternatives](https://image.slidesharecdn.com/f-ir-241012083954-d6064a68/75/Information-Retrieval-and-Storage-Systems-29-2048.jpg)





























![ICDIM 06 Web IR Tutorial [Compatibility Mode].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/icdim06webirtutorialcompatibilitymode-250307100423-5b1c7700-thumbnail.jpg?width=640&height=640&fit=bounds)
















![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)



