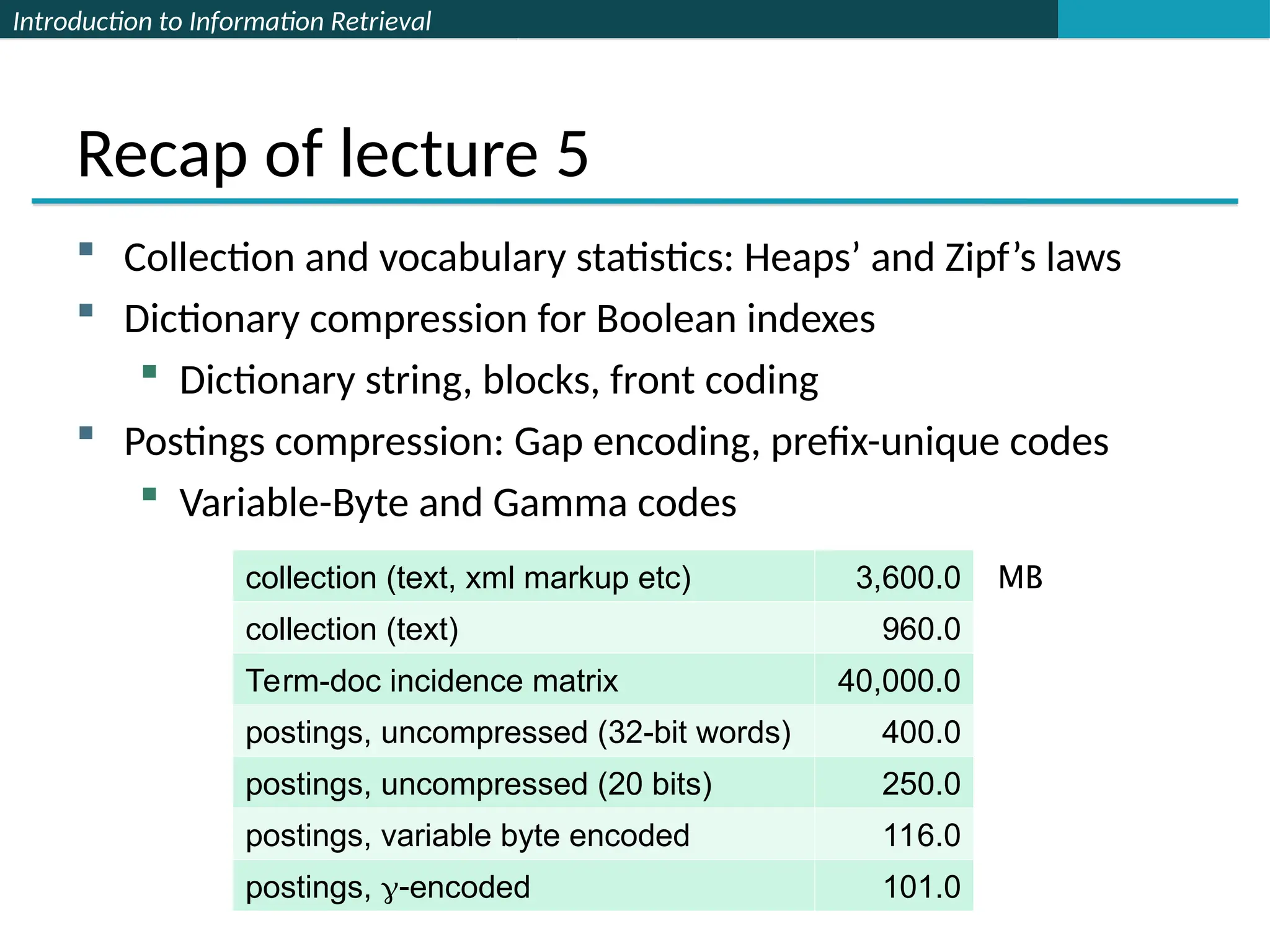
This document serves as an introduction to information retrieval principles, focusing on scoring, term weighting, and the vector space model. It discusses the shortcomings of boolean search methods and presents ranked retrieval as a more effective approach to handling user queries, highlighting various scoring methods like the Jaccard coefficient, term frequency, and TF-IDF weighting. Additionally, it covers concepts such as document vectors in high-dimensional space and cosine similarity for ranking relevant documents.






![Introduction to Information Retrieval
Scoring as the basis of ranked retrieval
We wish to return in order the documents most likely
to be useful to the searcher
How can we rank-order the documents in the
collection with respect to a query?
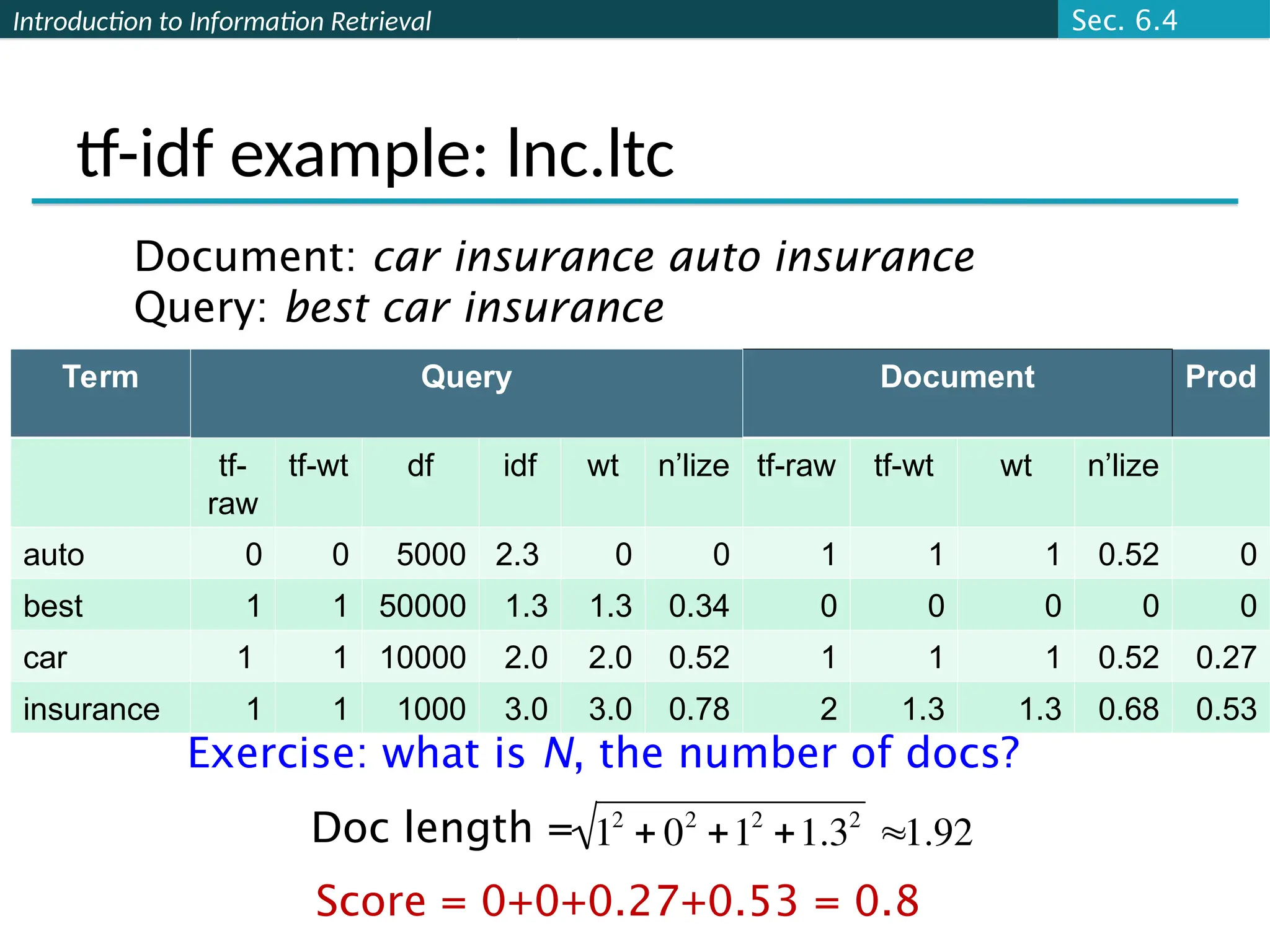
Assign a score – say in [0, 1] – to each document
This score measures how well document and query
“match”.
Ch. 6](https://image.slidesharecdn.com/lecture6-tfidf-240921173650-5df2353f/75/lecture-TFIDF-information-retrieval-ppt-8-2048.jpg)





















![Introduction to Information Retrieval
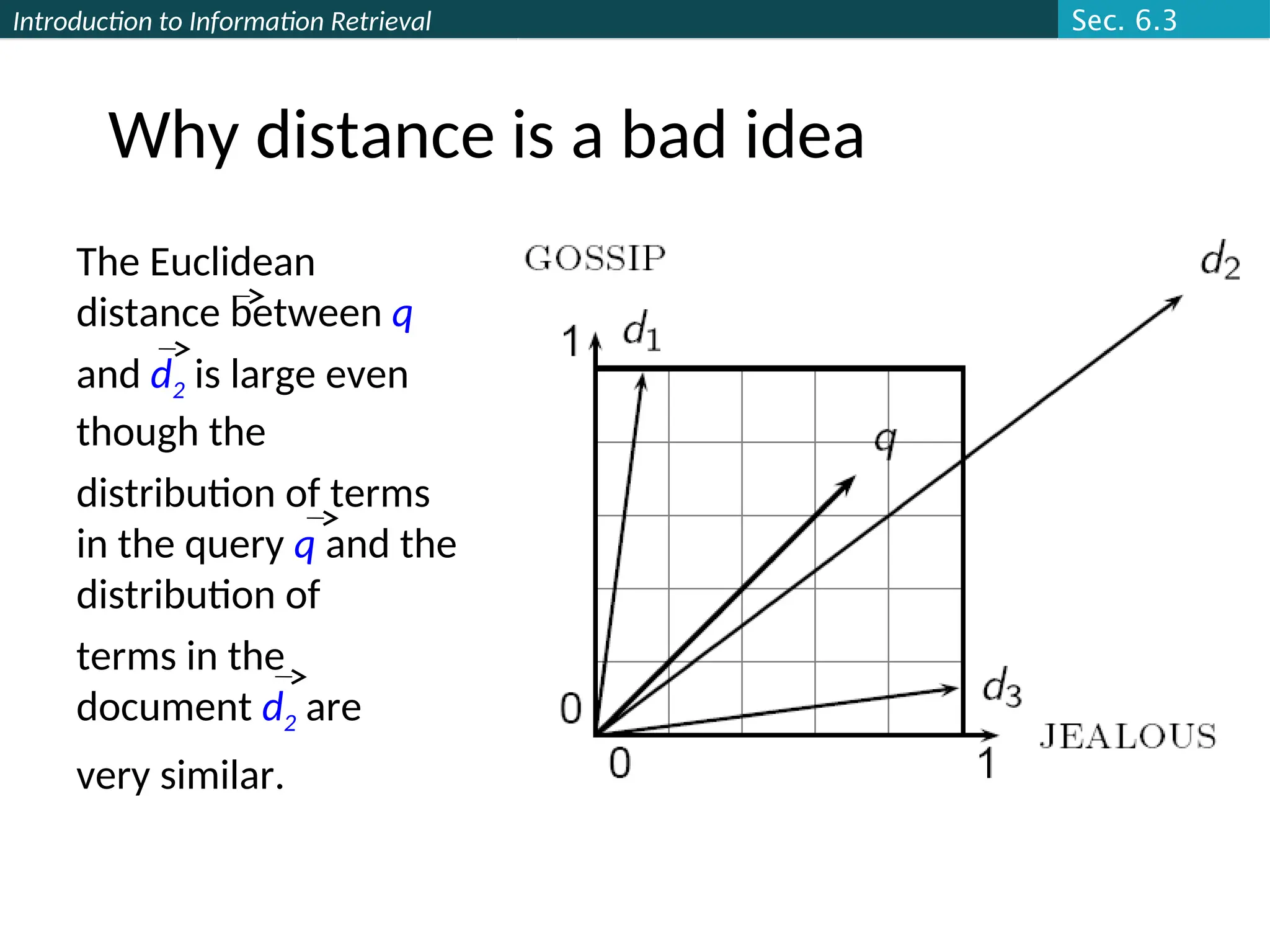
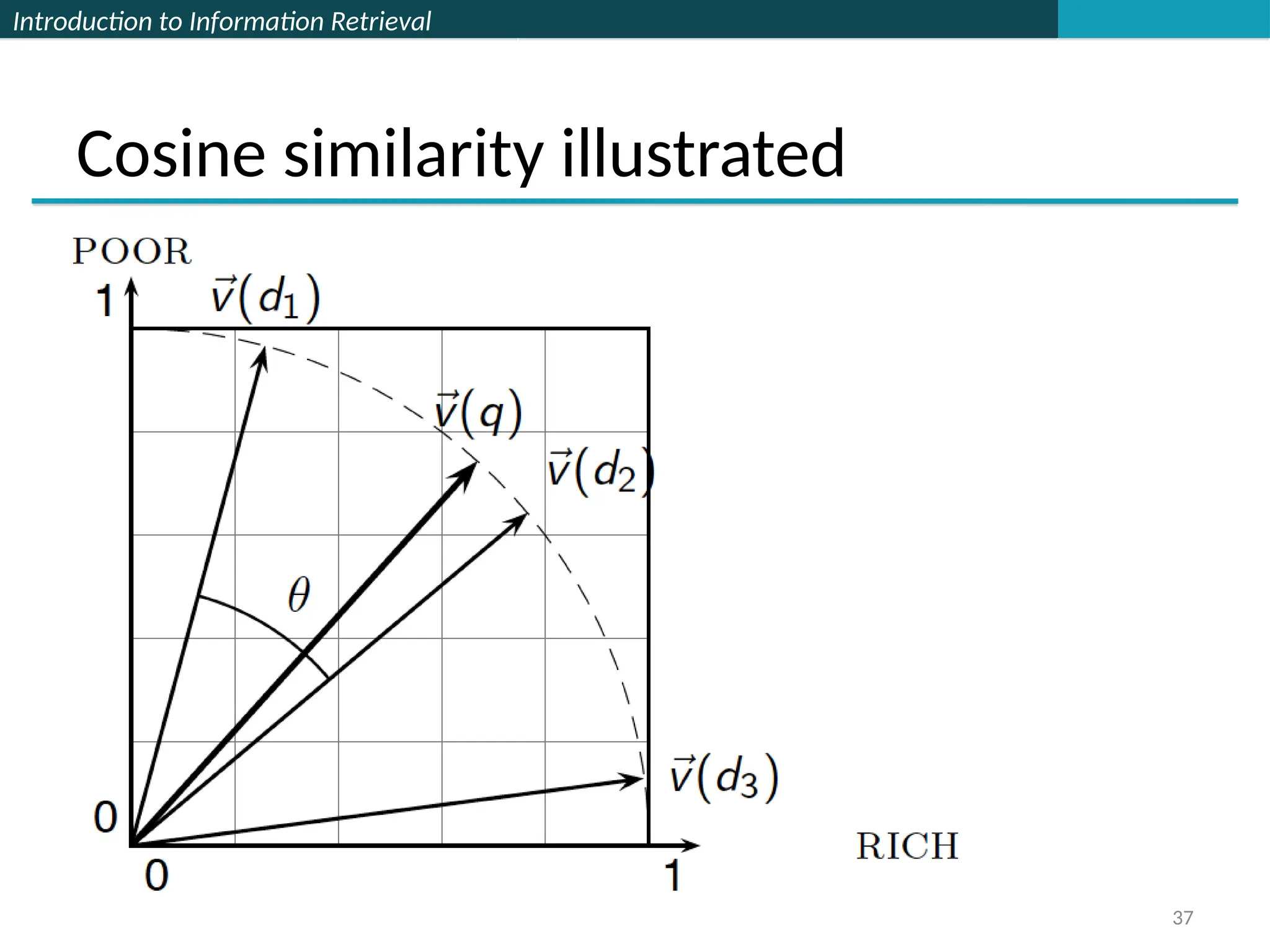
From angles to cosines
The following two notions are equivalent.
Rank documents in decreasing order of the angle between
query and document
Rank documents in increasing order of
cosine(query,document)
Cosine is a monotonically decreasing function for the
interval [0o
, 180o
]
Sec. 6.3](https://image.slidesharecdn.com/lecture6-tfidf-240921173650-5df2353f/75/lecture-TFIDF-information-retrieval-ppt-32-2048.jpg)












































![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)








