Downloaded 44 times




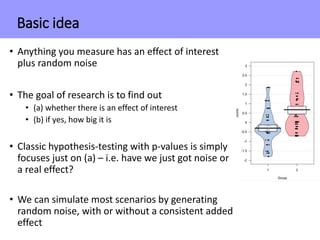
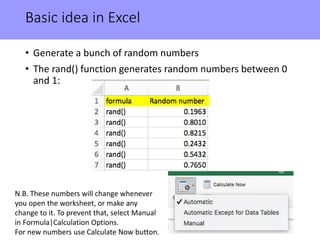

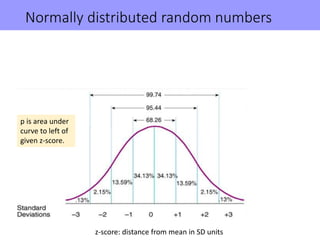



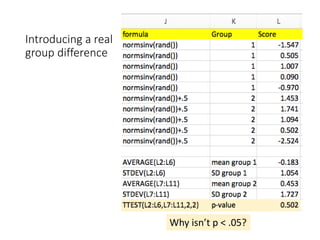

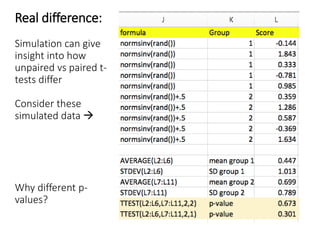
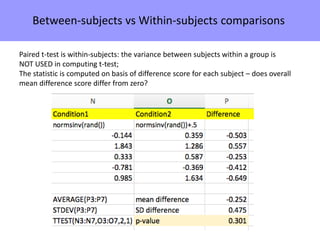

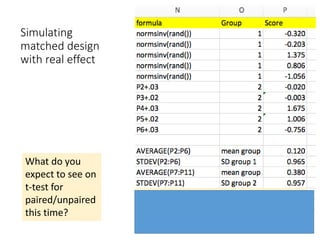
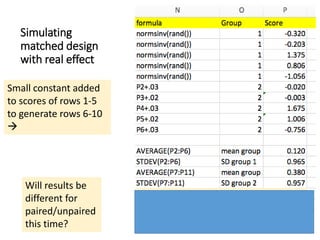
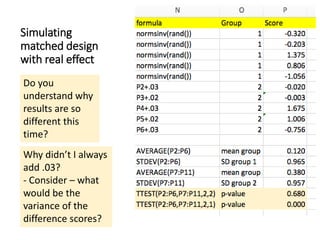



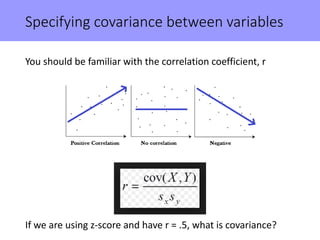




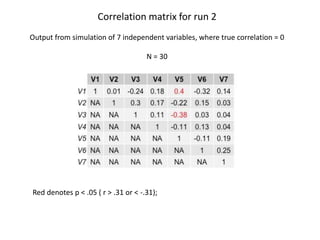
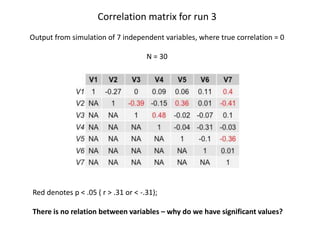




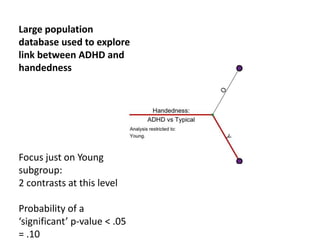
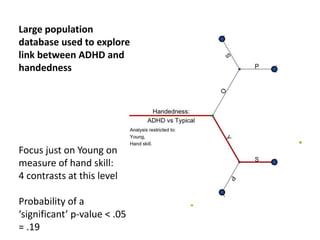
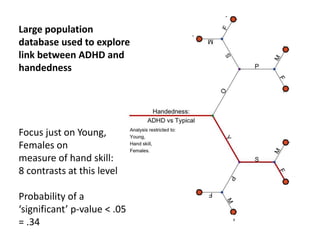
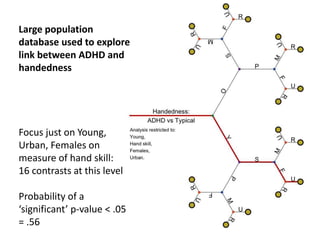




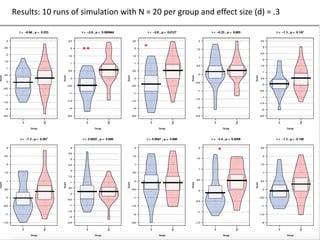

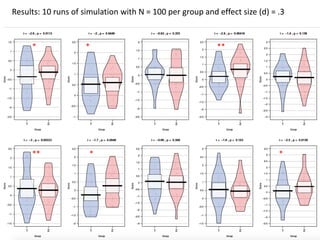






The document discusses the significance of simulating data for improving project design and analysis in research, particularly emphasizing its use in power analysis and understanding hypothesis testing. It explains methods for generating and analyzing simulated datasets using various tools, including Excel and R, to assess statistical validity and tackle issues like multiple testing and false positives. Additionally, it provides practical examples of using simulations to explore the effects of design choices on statistical outcomes.



































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)


















