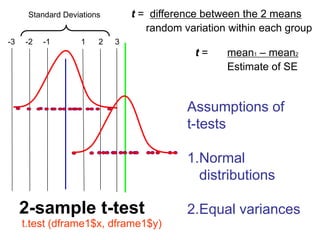
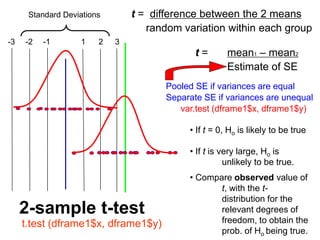
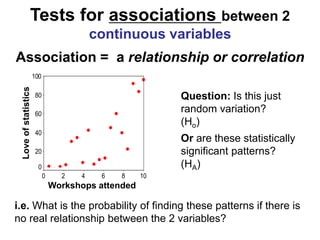
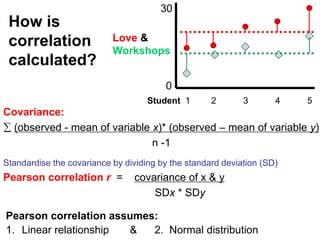
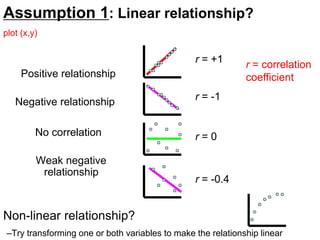
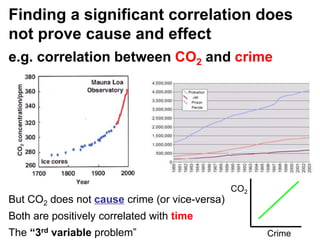
The document provides an overview of using R statistical software for data analysis, including steps to read and manipulate data, create visualizations, and perform statistical tests such as t-tests and correlation analyses. It covers descriptive statistics, hypothesis testing, and the importance of effect size and statistical power. The document also emphasizes the interpretation of results, including confidence intervals and correlation significance, while cautioning against inferring causation from correlation alone.



![Pairwise plots
names(dframe1)
pairs (dframe1[c(1,2,4)],
panel = panel.smooth)
Specifies variables
1, 2 and 4 in
dframe1
Sex
130 150 170 190
1.0
1.2
1.4
1.6
1.8
2.0
130
150
170
190
Height
1.0 1.2 1.4 1.6 1.8 2.0 20 25 30 35
20
25
30
35
Age](https://image.slidesharecdn.com/session1-gettingstarted-240610152443-26c74ae9/85/Session-1-Getting-started-with-R-Statistics-package-ppt-4-320.jpg)