



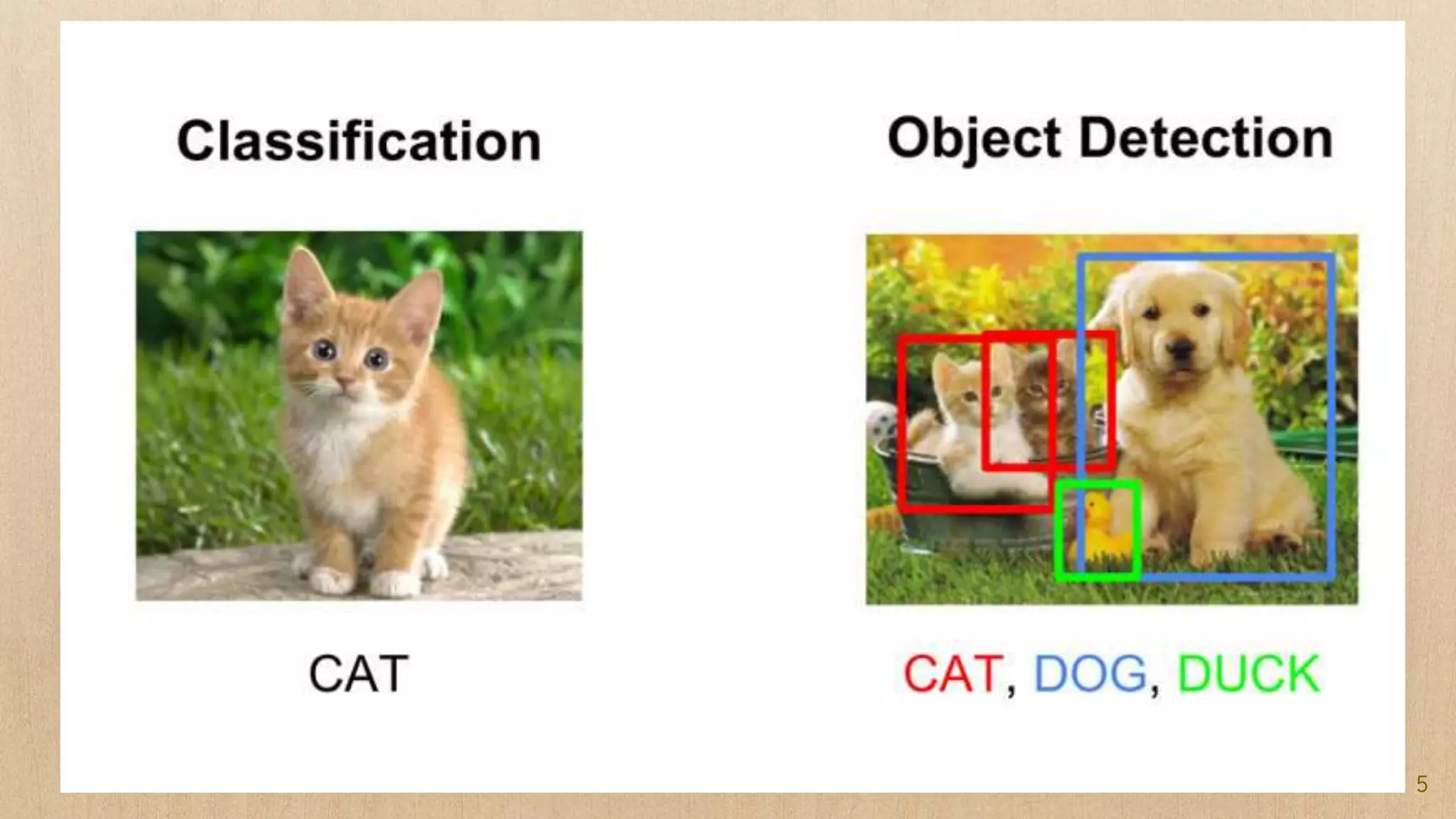





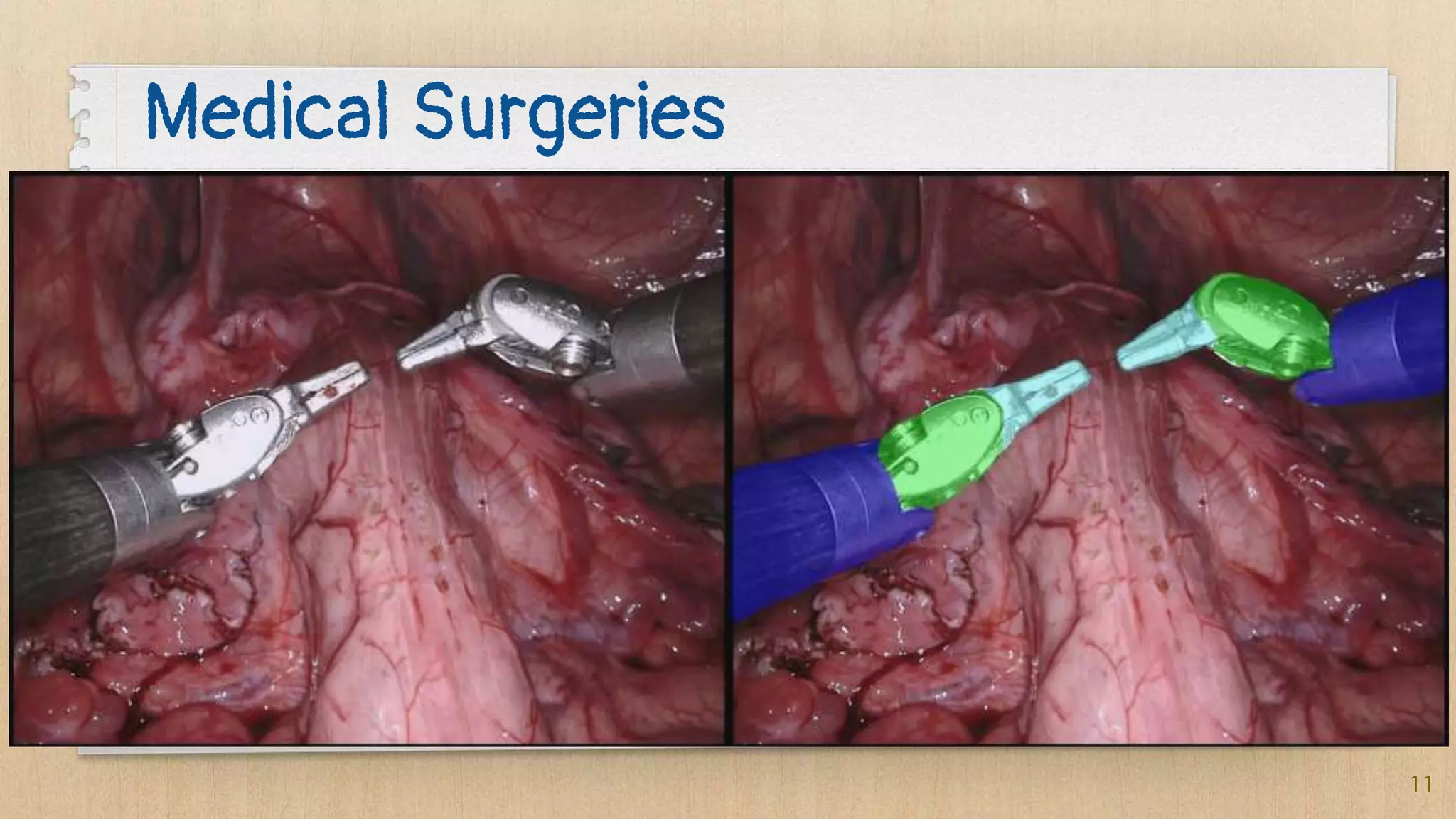
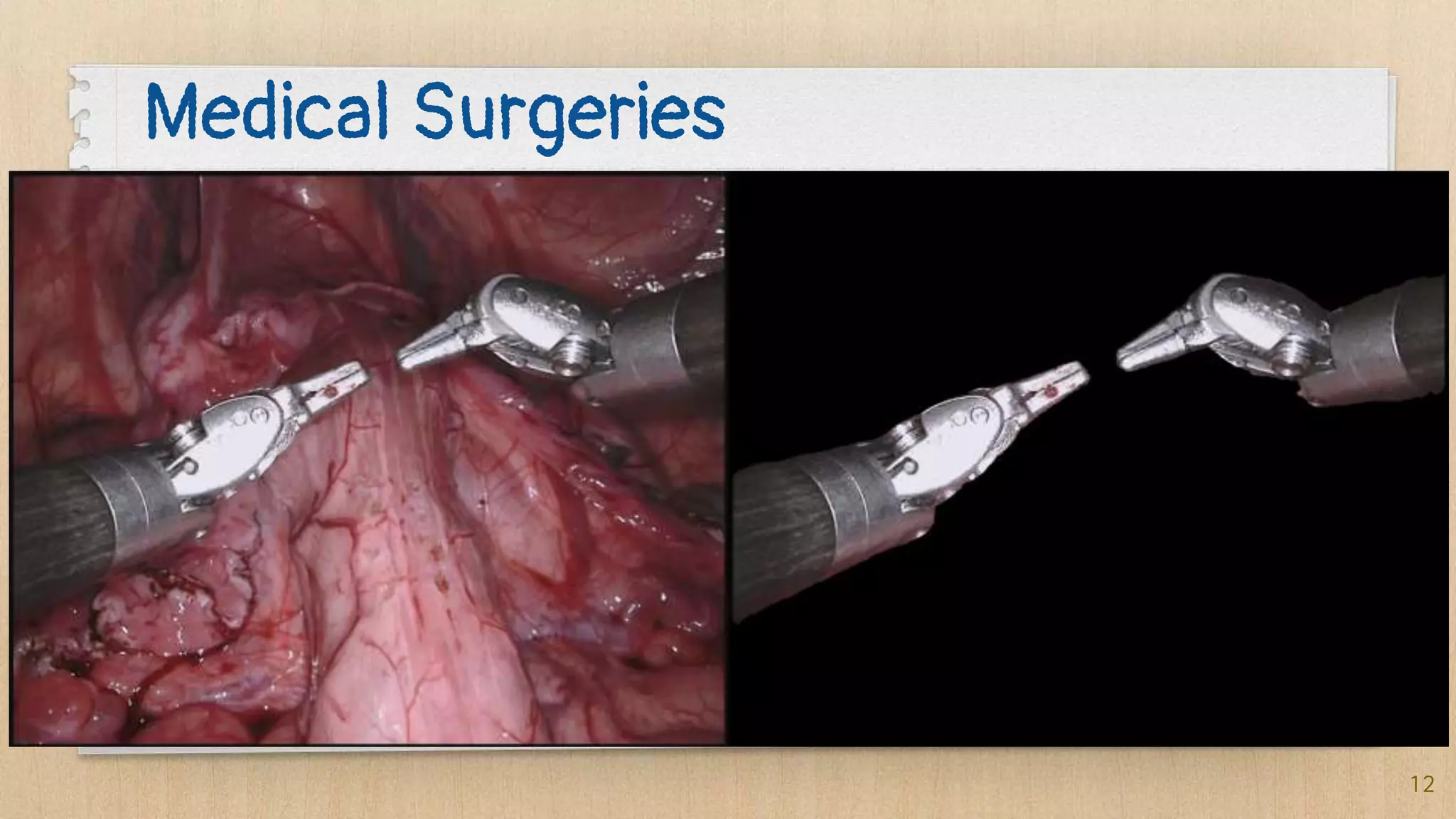
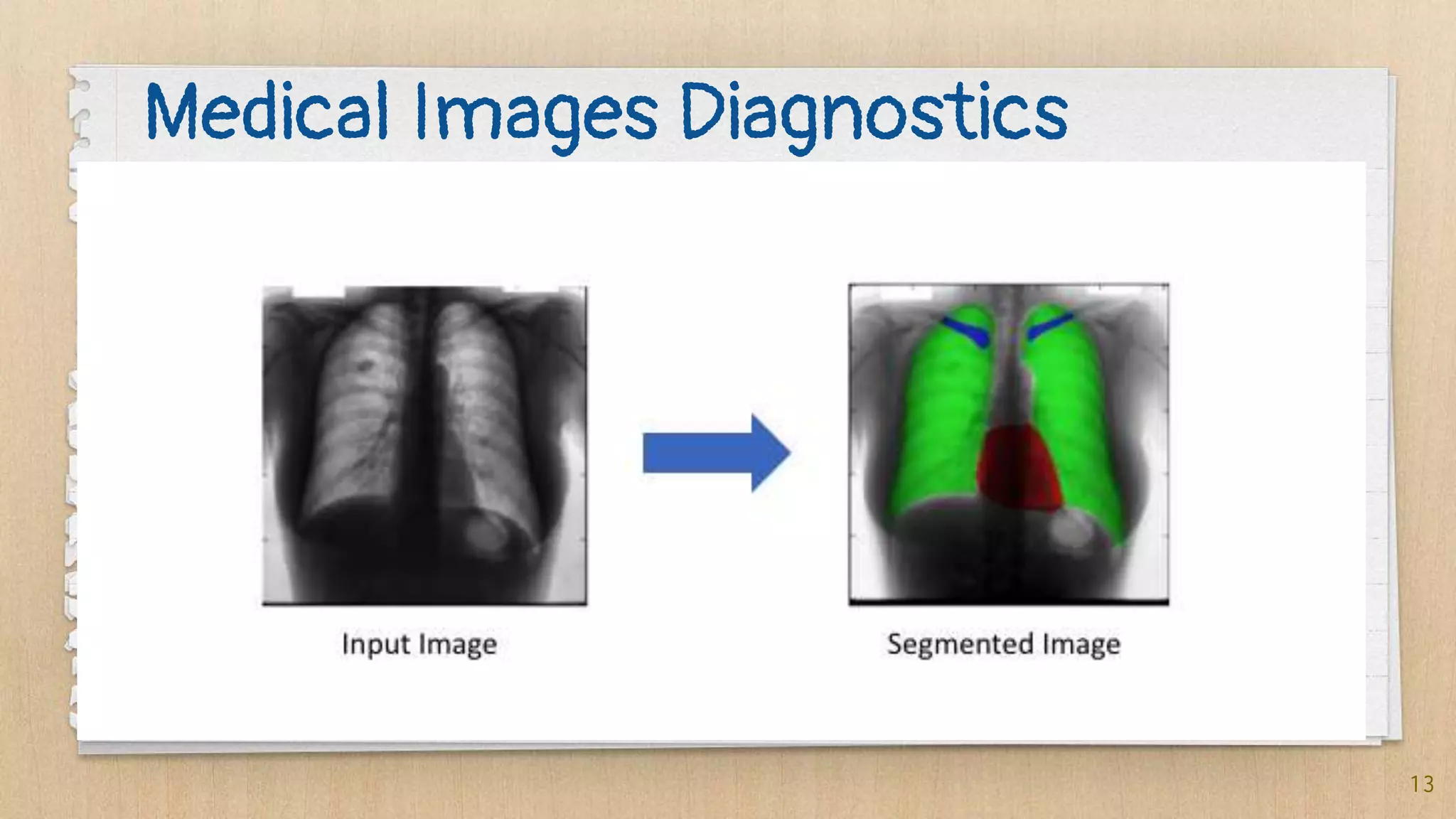


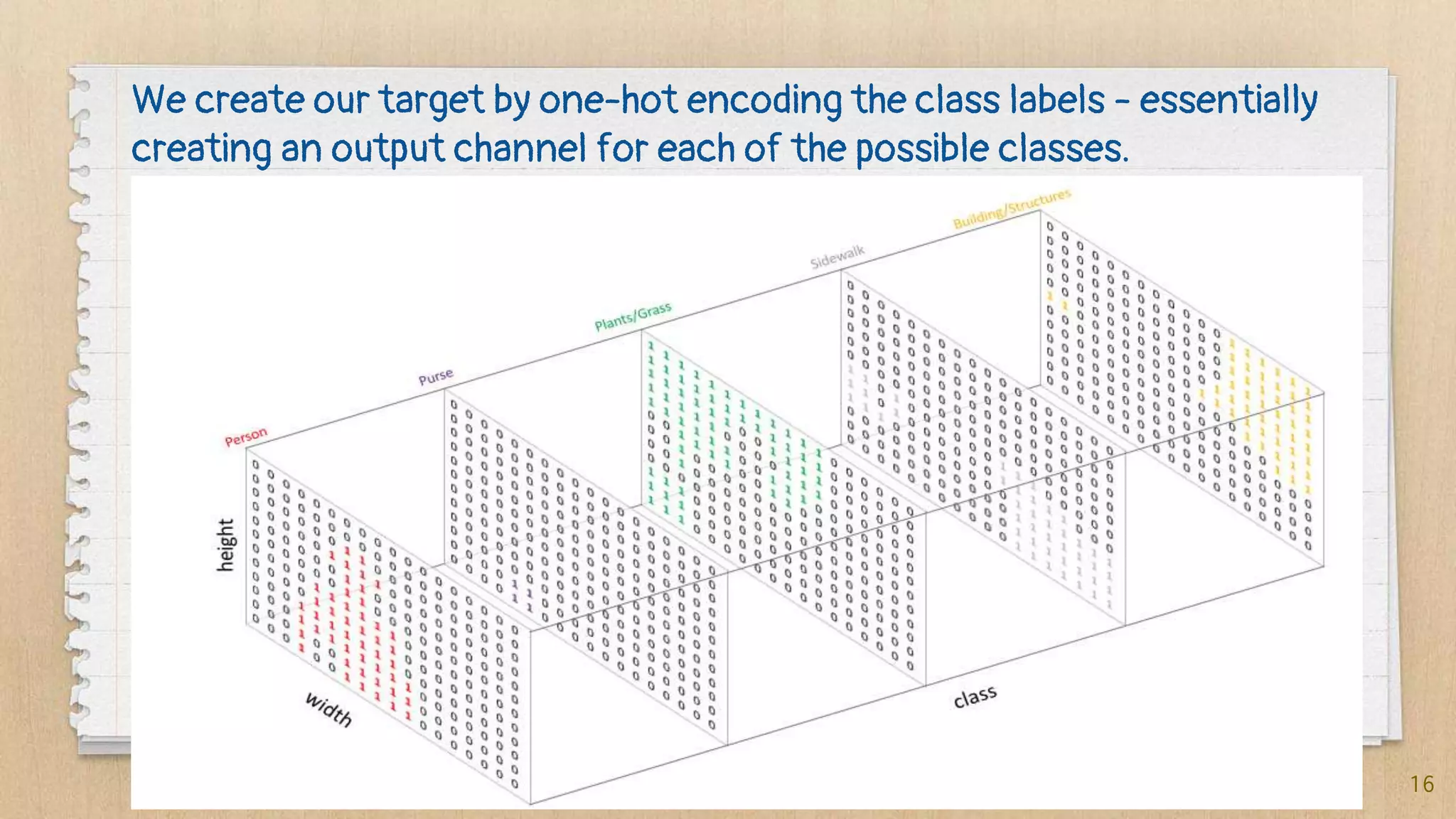


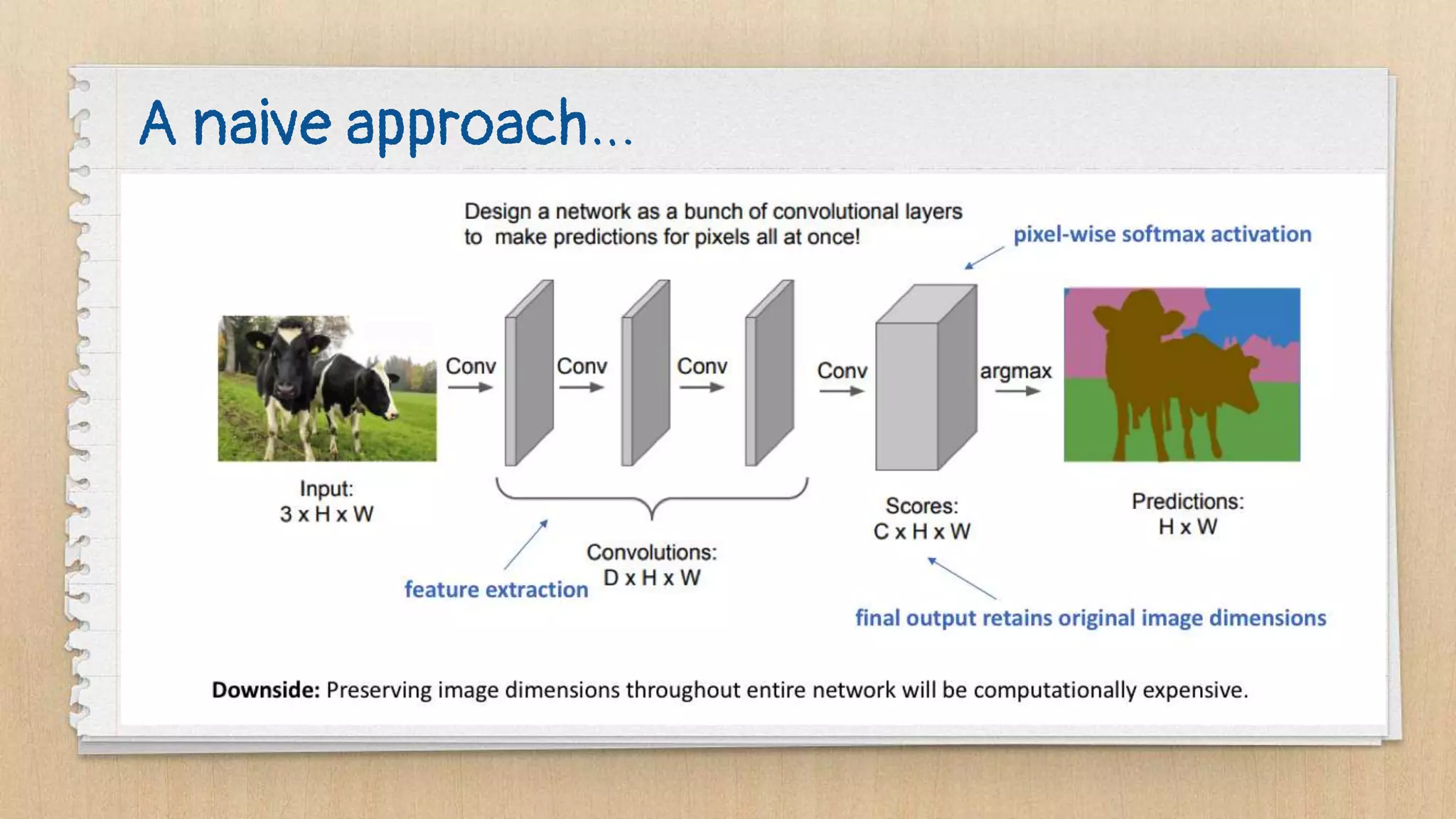



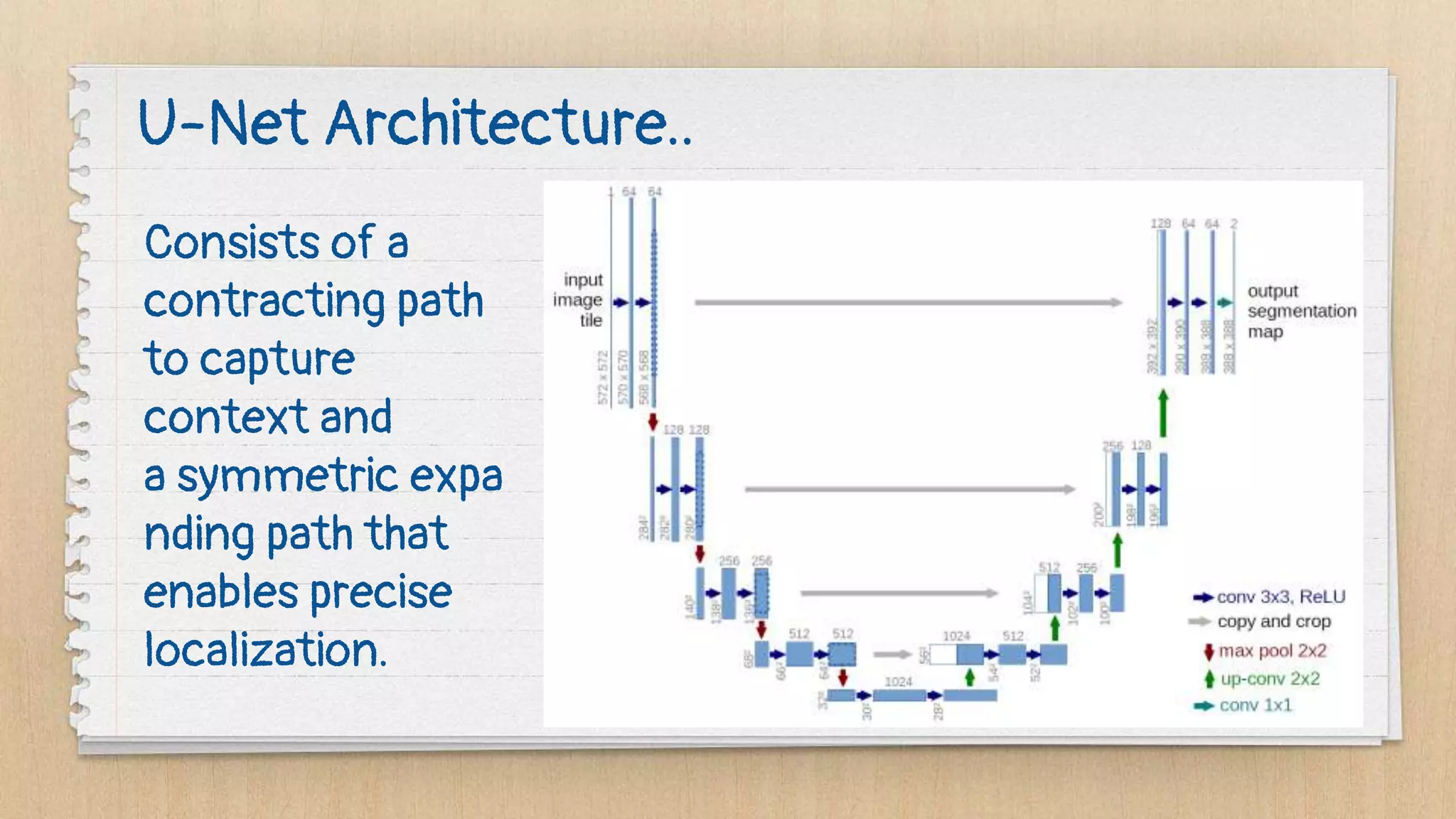

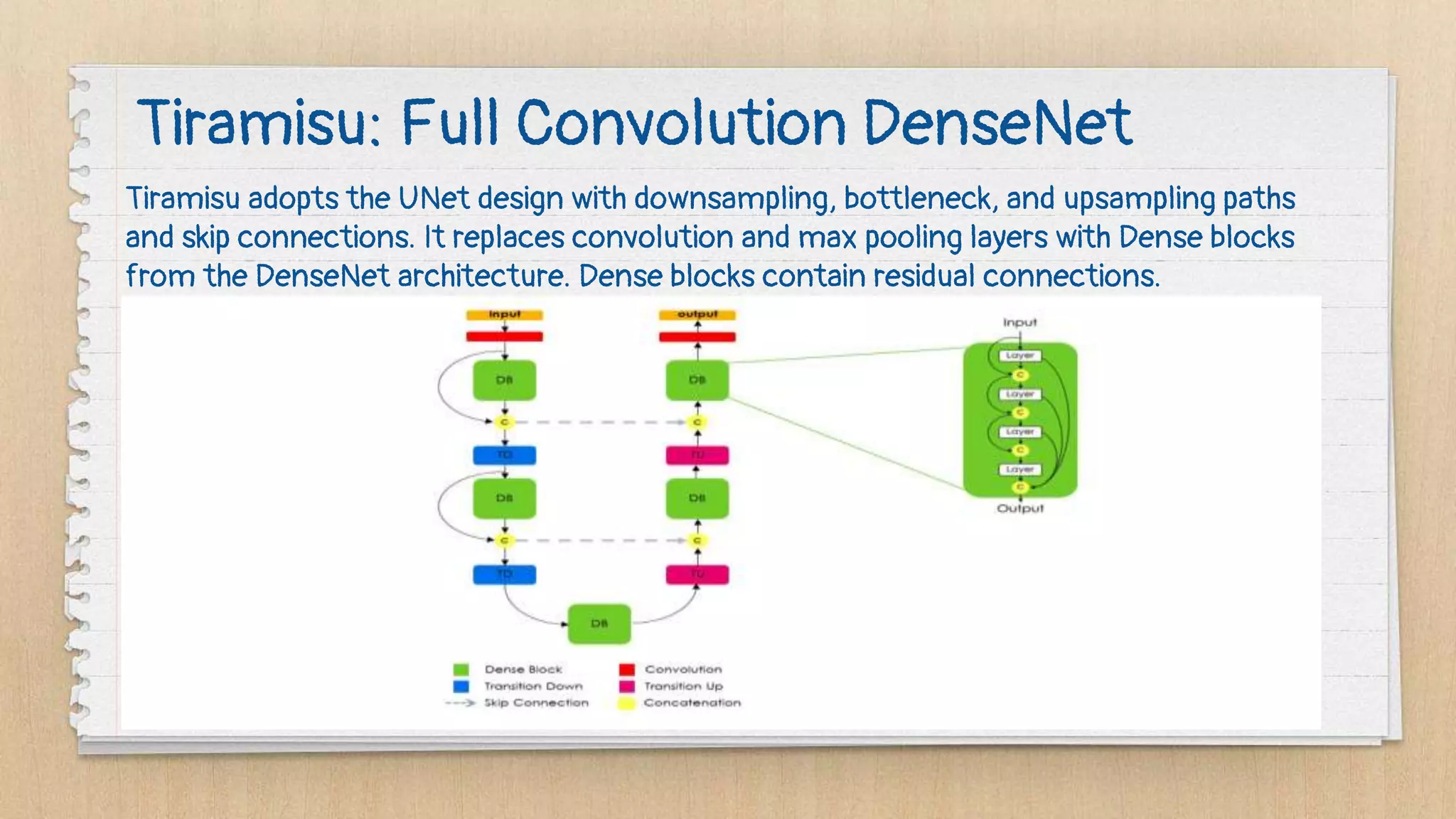




Semantic segmentation is a dense prediction task that labels each pixel of an image with a class. It has applications in autonomous vehicles, medical imaging, and surgeries. Popular architectures for semantic segmentation include U-Net, which uses an encoder-decoder structure with skip connections, and Tiramisu, which uses dense blocks. The loss function commonly used is pixel-wise cross entropy loss, which examines predictions at each pixel.



































































