This document summarizes the key steps in building a risk prediction model:
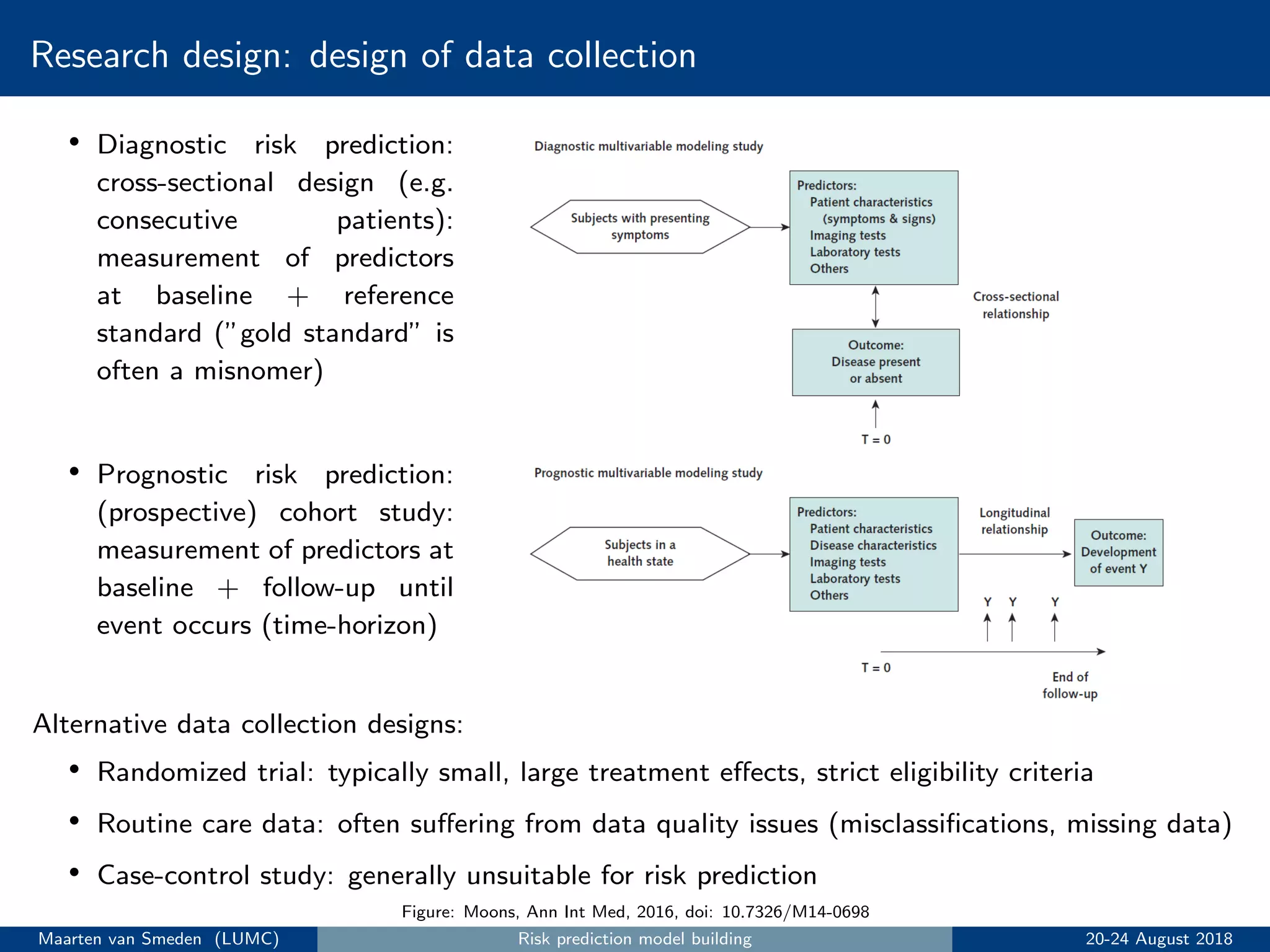
1. Conduct research design and data collection, typically using a prospective cohort study.
2. Choose statistical model, outcome, and candidate predictors based on clinical knowledge.
3. Perform initial data analysis including descriptive statistics and assessing predictors.
4. Specify and estimate the prediction model, addressing issues like handling continuous predictors and missing data.
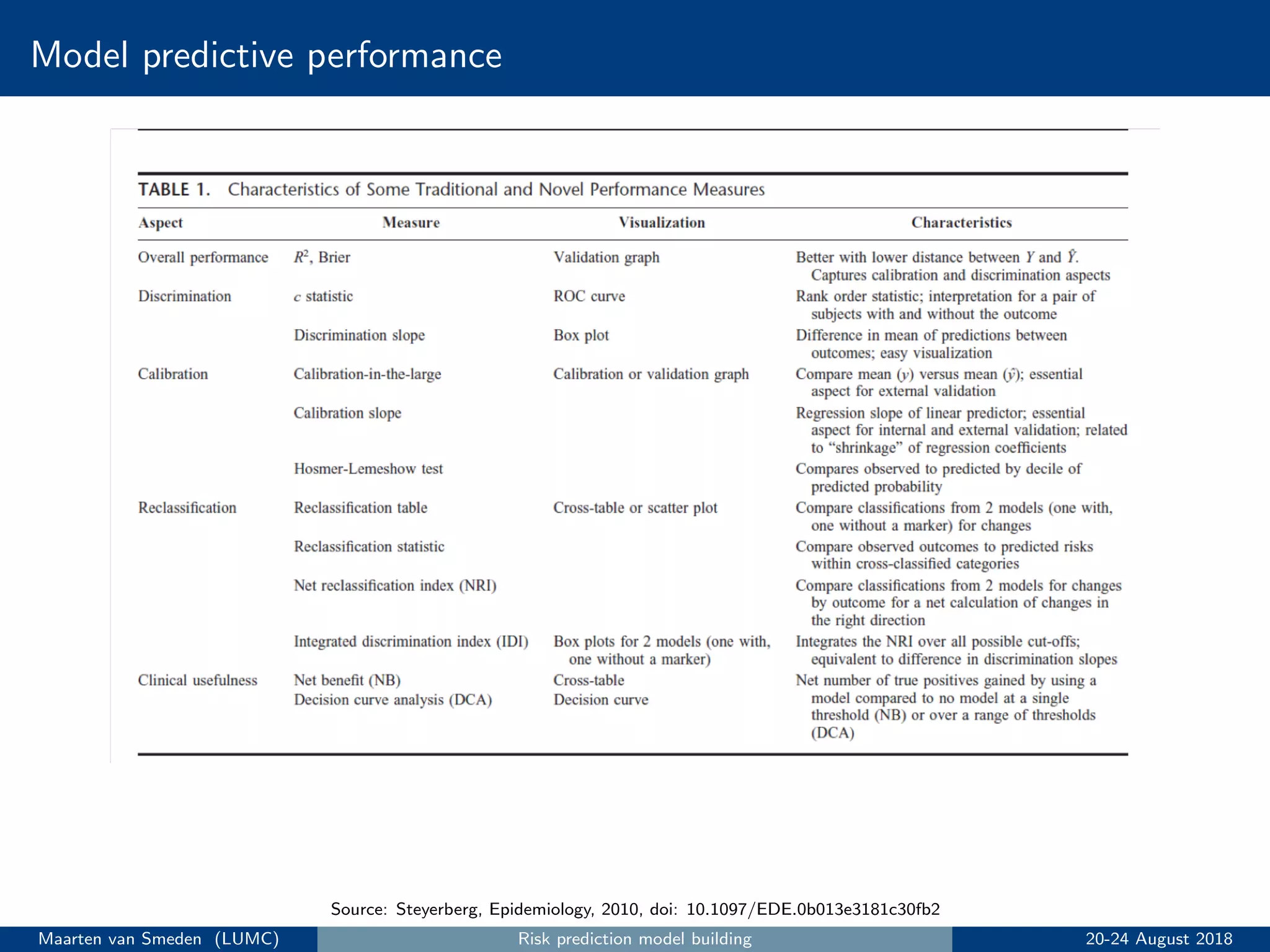
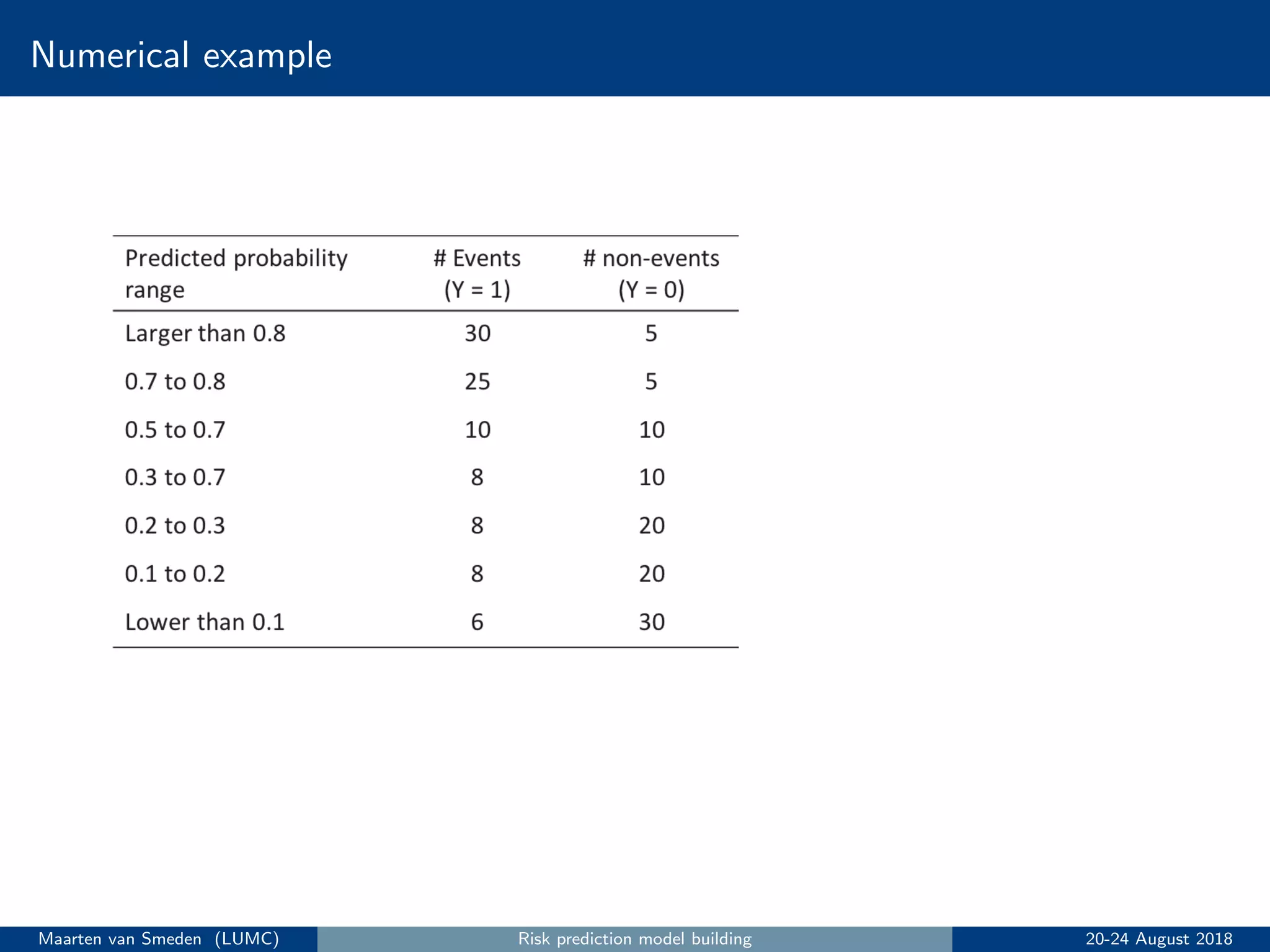
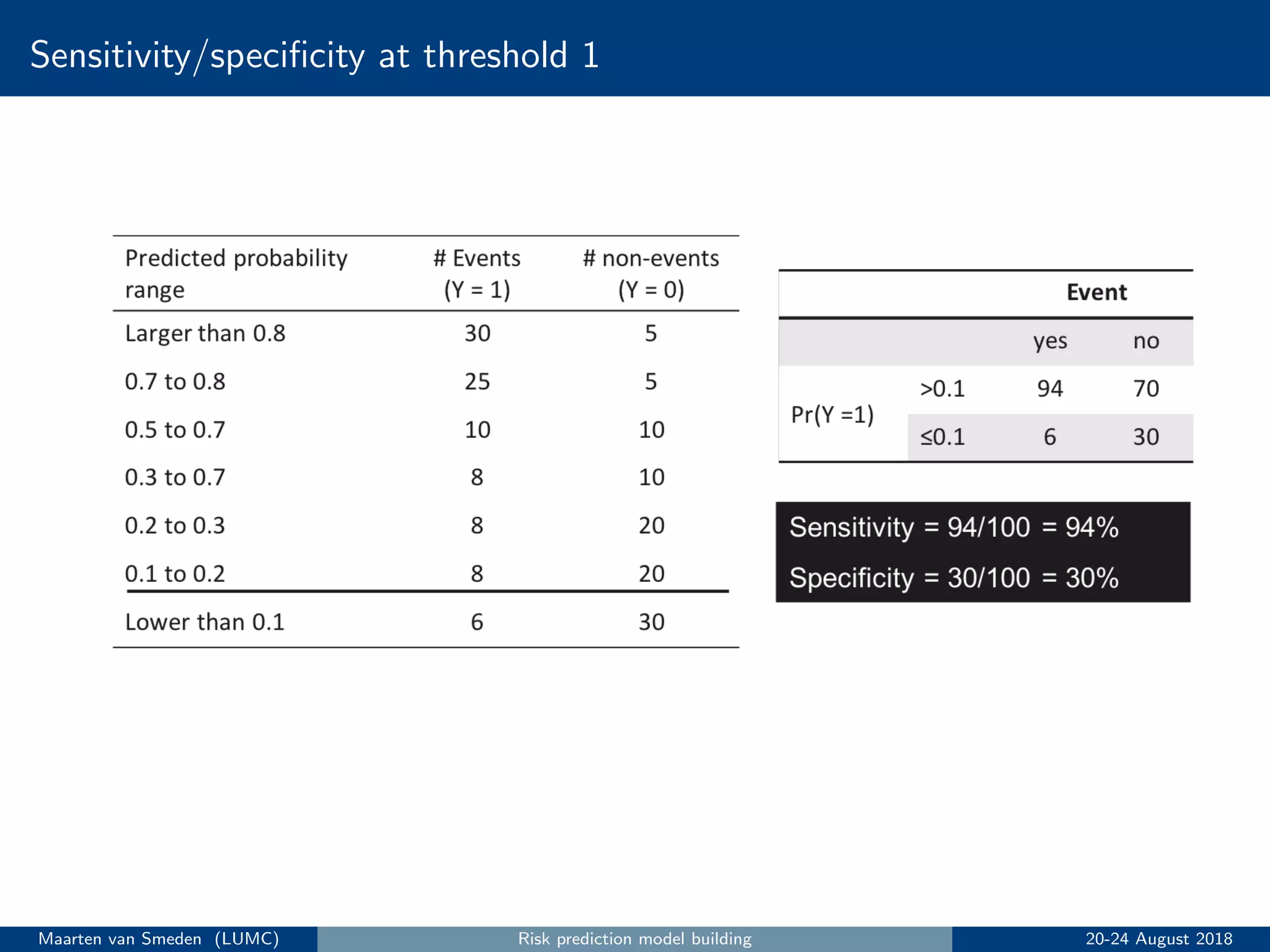
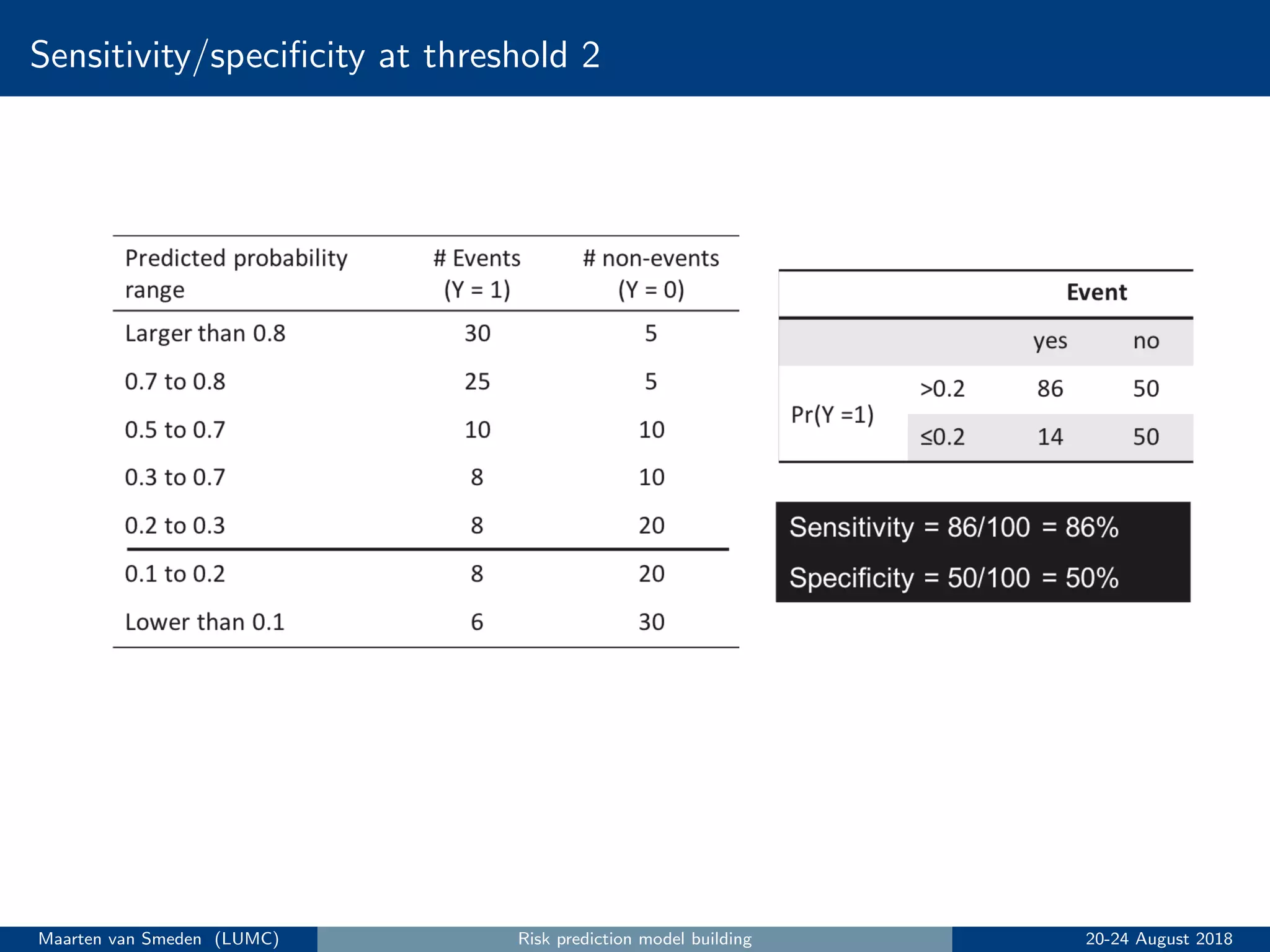
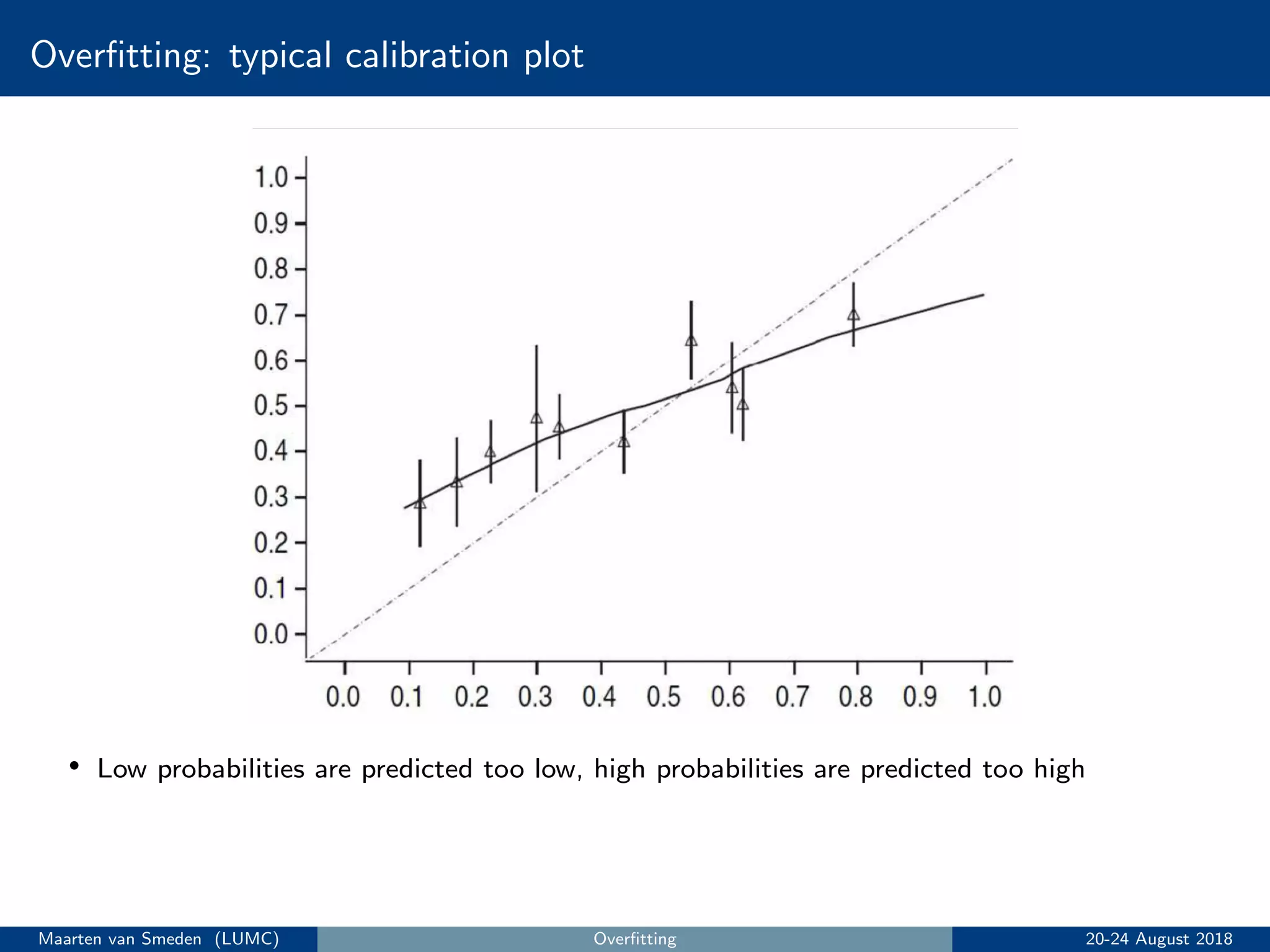
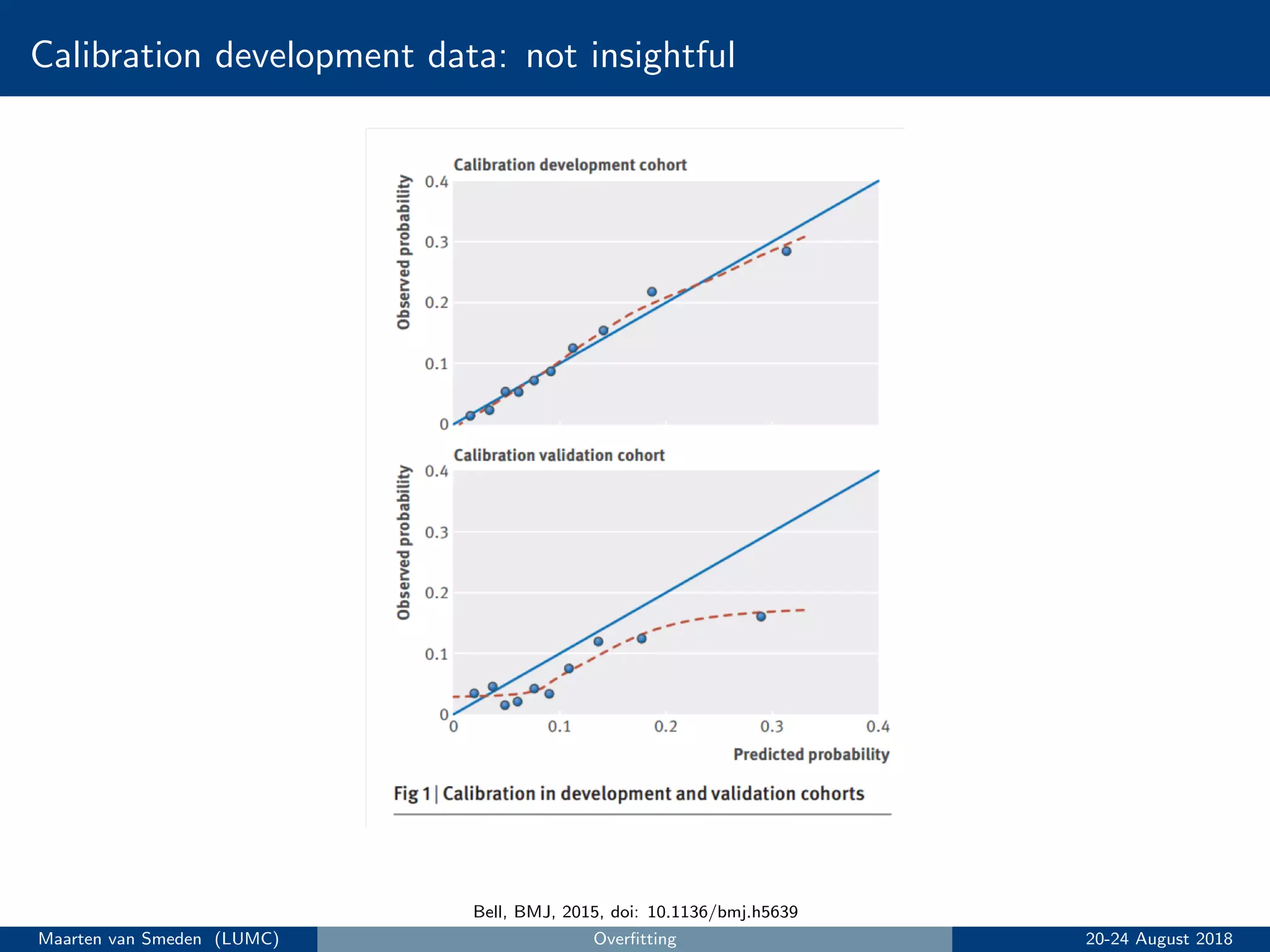
5. Evaluate the model's performance using measures like discrimination and calibration and perform internal validation to account for overoptimism.
6. Present the final model following reporting guidelines like TRIPOD.















![Dichotomania
Dichotomania is an obsessive compulsive disorder to which medical advisors in
particular are prone [. . .]. Show a medical advisor some continuous measurements
and he or she immediately wonders. Hmm, how can I make these clinically
meaningful? Where can I cut them in two? What ludicrous side conditions can I
impose on this?
Stephen Senn
Quote source: Senn, http://www.senns.demon.co.uk/Geep.htm
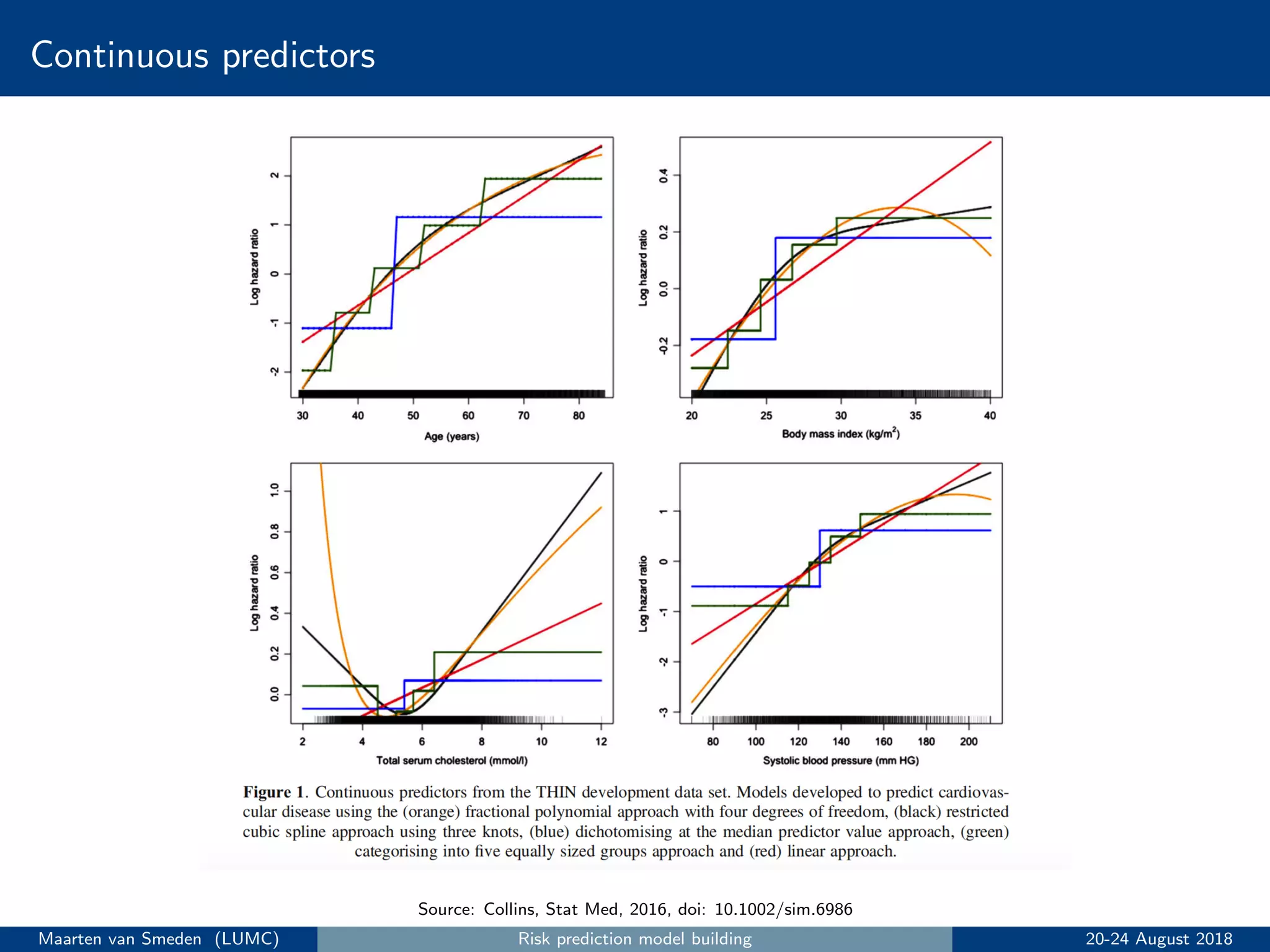
Dichotomising predictors is unfortunately very common in prediction modeling
• Example: create a new predictor with 0 if age < 50 years (’young’); 1 if age ≥ 50 years
(’old’)
• Throws away precious information for risk prediction
• Unrealistic, it assumes those immediately above and below the cut point have different risk
• Reduces predictive accuracy of the model
Avoid dichotomising predictors!
Maarten van Smeden (LUMC) Risk prediction model building 20-24 August 2018](https://image.slidesharecdn.com/topics5to7-180824132648/75/Introduction-to-prediction-modelling-Berlin-2018-Part-II-21-2048.jpg)