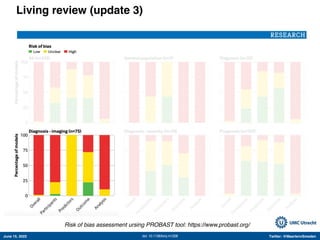
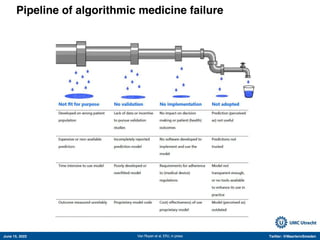
The document appears to be a Twitter thread by Maarten van Smeden discussing various topics related to machine learning and its applications in medicine. It includes links to several studies and articles. The thread touches on a number of issues, including the increasing use of AI in medical publications over time; examples of successful applications of machine learning like detecting diabetic retinopathy and tuberculosis; potential issues and misconceptions around ML methods; and the importance of accounting for bias, variance, and irreducible error in clinical prediction modeling.