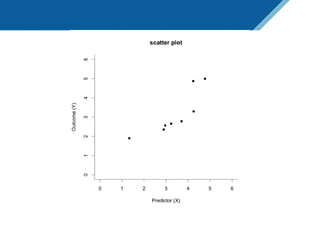
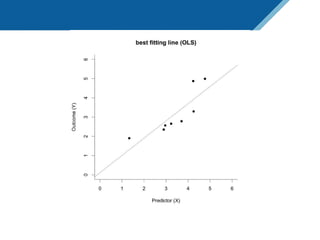
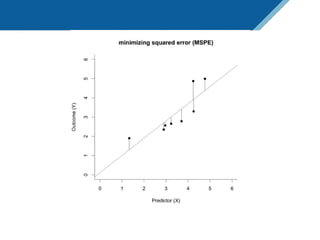
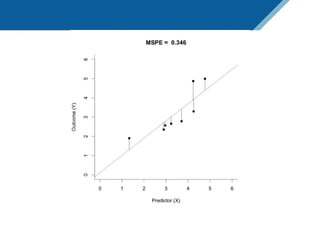
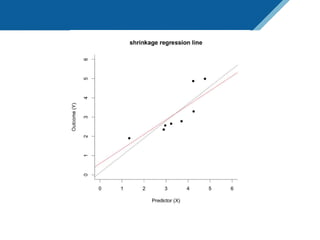
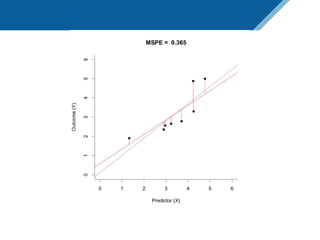
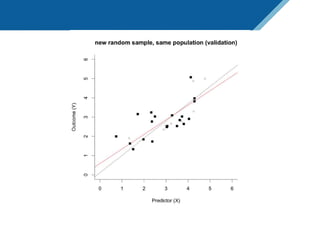
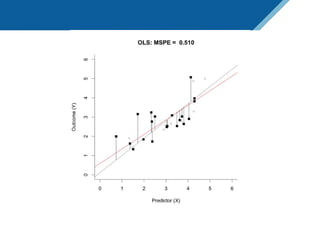
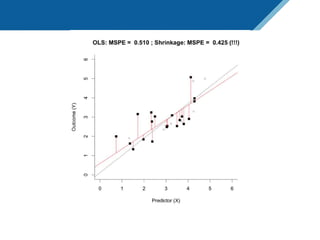
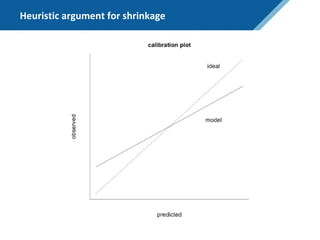
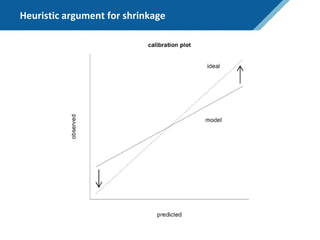
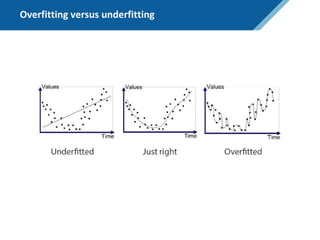
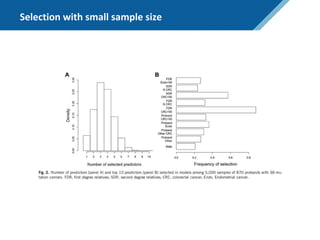
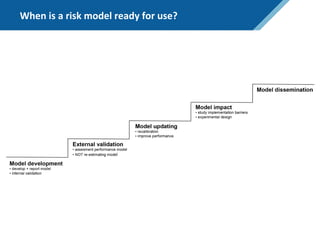
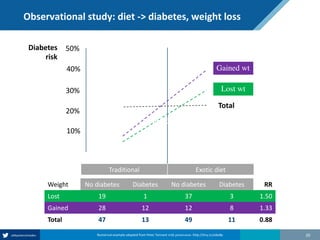
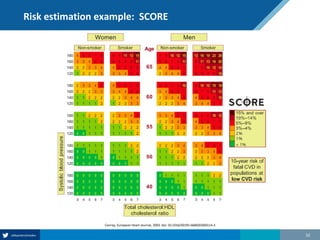
Here are the steps to solve this exercise:
1) Given:
Prev = 30%
Se = 99%
Sp = 95%
2) Calculate other metrics:
PPV = 75%
NPV = 99.7%
3) Re-calculate NPV assuming Prev of 10%:
NPV = 99.95%
4) Re-calculate NPV assuming Prev of 80%:
NPV = 91.2%
So in summary, the NPV decreases as the prevalence increases, since with a higher prevalence there is a higher chance that a negative test result represents a false negative.








































![In-class exercise – ClearBlue compact pregnancy test
• Calculate Prev, Se, Sp, NPV and PPV
• Re-calculate NPV assuming Prev of 10%, and again with 80%
• Make use of NPV = Sp*(1-Prev)/[(1-Se)*Prev + Sp*(1-Prev)]](https://image.slidesharecdn.com/predictionjan2020berlinslides-200116162020/85/The-basics-of-prediction-modeling-53-320.jpg)