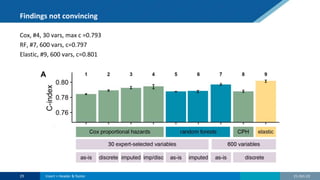
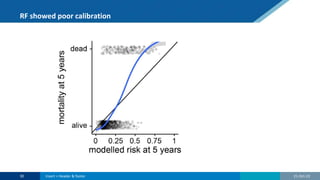
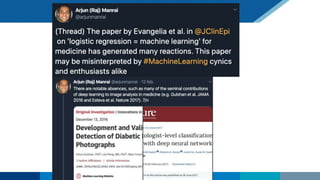
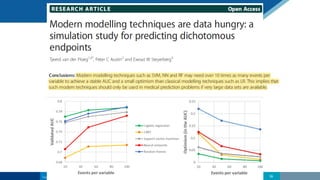
The document discusses the relationship between statistics and machine learning (ML) in medical research, highlighting both friction points and commonalities. It points out that while ML is often perceived as a new advancement, it fundamentally derives from statistical methods and emphasizes the importance of data quality and research questions. The summary concludes by suggesting collaboration between statistics and ML to tackle complex problems effectively.

























































































![CTEV [ clubfoot] DR ARUN LAL ,DR MOHAMED ASHRAF travancore medical college k...](https://cdn.slidesharecdn.com/ss_thumbnails/ctevclubfootdrarunlaldrmohamedashraftravancoremedicalcollegekollamkeralaindia-260208063247-18fc466c-thumbnail.jpg?width=640&height=640&fit=bounds)











![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)






